We’ll start with a brief reminder of the problems that can be solved with RAG, before looking at the improvements in LLMs and their impact on the need to use RAG.
Let’s start by a bit of history
RAG isn’t really new
The idea of injecting a context to let a language model get access to up-to-date data is quite "old" (at the LLM level). It was first introduced by Facebook AI/Meta researcher in this 2020 paper "Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks". In comparison the first version of ChatGPT was only released on November 2022.
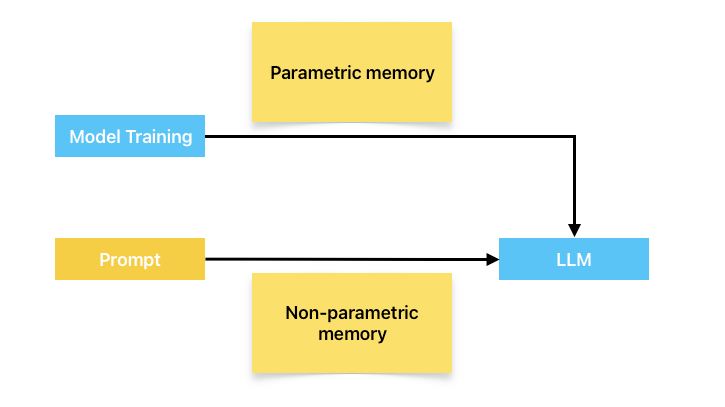
In this paper they distinguish two kind of memory:
- the parametric one, which is what is inherent to the LLM, what it learned while being fed lot and lot of texts during training,
- the non-parametric one, which is the memory you can provide by feeding a context to the prompt.
For the retrieval part the authors of the paper were already using text embeddings to search for relevant documents. (Please note that while semantic search is very often used in RAG to find documents, it is not the only possibility).
The result of their experimentation was that using RAG we could obtain more specific and factual answers than without using it.
What changed with ChatGPT
With the release of ChatGPT on November 2022 people discovered what can, be done using a LLM: to generate an answer from a query. But they also discovered some limitations like:
- a LLM does not have access to information to events that occurred after their training dataset was created (or were not part of the dataset),
- a LLM tends to made up things (hallucinations) instead of saying "I don’t know".
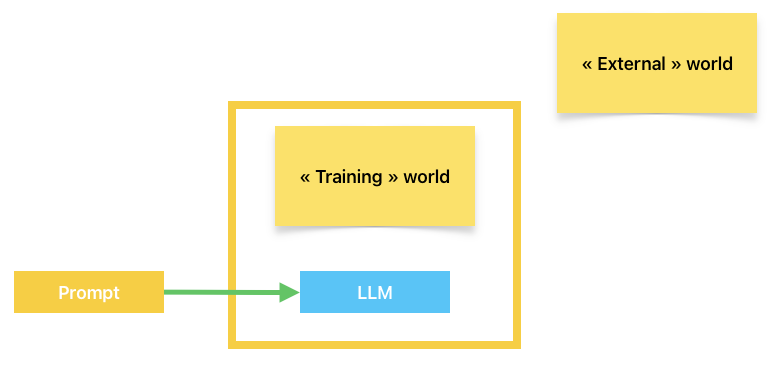
The LLM can’t have directly access to external knowledge, all it can use is what was in its training dataset and what is given in the prompt. Asking directly to answer a question to something that is not part of the first or the latter often result into hallucinations are LLM are used to generate text, not to give facts.
The rise of RAG
Even though it already existed, I only heard about RAG on May 2023. The idea was quite simple. Instead of asking the LLM (ChatGPT) to answer directly to a query, how about asking it to formulate its answer using a context, and only the context, provided in the prompt?
The prompt is what is given to an LLM as the starting point for it to generate an answer.
Use the following pieces of context to answer the users question.
If you don't know the answer, just say that you don't know,
don't try to make up an answer.
----------------
{context}Results were quite good, hallucinations were reduced, the answer could be based on up-to-date data and even business data.
Since then lots of articles have been written about RAG.
The limitations
They were mostly about the size of the context that could be fed to the prompt as ChatGPT-3.5 original model was limited to 4k tokens which was about 3000 english words. This limit is not about how much text you can put in the prompt, it is about how much text you can have considering both the prompt and the answer!
Giving a too big context means you can’t have a long answer.

The context window is like having a blackboard, the more space is used to give instructions the less remain to write an answer.
So it was crucial to balance between having a too Long Context (and not having room for the answer) or risking missing the relevant knowledge to answer the query in the prompt.
Nowadays
What has changed since then? A little and a lot at the same time.
The need to create a prompt with a context to answer a query in order both: to have up-to-date information and reduce hallucinations is still present.
Also it is still not an easy task to look for relevant documents in RAG.
Although semantic search is presented as easy to implement, the reality is that as the number of documents increases, strategies need to be put in place to ensure that what is retrieved is actually relevant.
The context window has increased
It is the biggest change that occurred in my opinion, at least for what is relevant for this article.
If you take a model like GPT-4o (first released on May 2024) you have a 128K context window, that’s a lot of text you can put in the prompt. (But the output is limited to "only" about 16K tokens, which is still quite big).
As for Gemini 1.5 from google it started to be available with a 1 Million token context window on February 2024.
What consequences?
To answer this question we will take a look at some articles about this topic.
Some people argues that since nowadays context window are big enough to contain a book, there is no longer the need to select only relevant data. You can directly input all the knowledge of your company as the context in the prompt and ask your query on it.
Some researchers even found (July 2024) out that it might give better results than purely relying on RAG.
Retrieval Augmented Generation or Long-Context LLMs? A Comprehensive Study and Hybrid Approach
While the article was focused on "Self-ROUTE" a proposition to determine wether to use a Long-Context prompt or RAG to answer a query, they did start by determining than in most cases the Long-Context choice might provide better results than relying only on RAG. The final goal of their experimentation is both to increase the quality of the answers, and to reduce costs
A most recent article (September 2024) suggests that RAG is still relevant and the limitations encountered in the previous article were mostly about the order in which found relevant text were added to the prompt. (They recommend to keep those chunks in the same order they were in the original document).
In Defense of RAG in the Era of Long-Context Language Models
This second article has a different conclusion than the other and say that stuffing too much information in the context results in degrading the quality of the answer. It also provides food for thought on the importance of the order of elements in building context in the prompt.
To continue on this subject, I recommend reading a third article, although it is a little older (July 2023). As nowadays most LLMs remain transformer based, this article is still relevant to help us understand some limitations of using long long-context prompts.
Lost in the Middle: How Language Models Use Long Contexts
To summarize, they used a context where only one of the document was relevant, and they looked for the quality of the answer according to the position of this relevant document. They then repeated the experiment with an increasing number of chunks in the context. Changing the LLM had no impact on the overall shape of the curves.

The LLM is most likely to be able to use an information if it is at the start of the prompt than if it is in the middle. It improves in the end. Also increasing the number of "non-relevant" documents reduces the capacity of the model to retrieve an information.
To conclude, my thoughts about it
In my humble opinion Retrieval-Augmented Generation will still stay relevant for a very very long time, the main reason being… money.
The longer the prompt is the more computation time is needed to process the context. Consequently, using RAG to limit the prompt to what is needed reduces the cost compared to feeding the LLM with all your company knowledge.
In the future, when using LLM with long context, what we might expect from RAG might be not to find out relevant parts of documents to answer a query, but to filter-out irrelevant parts in order to reduce the costs and increase the quality.
But I do think that the future of RAG will lie in the use of smaller, more specialized models rather than models designed for general use.
That’s all folks!
Feel free to clap, follow me or give your opinion!







