
Intuition, a derivation and Jensen’s Inequality
The Mean Absolute Deviation (MAD) and Standard Deviation (STD) are both ways to measure the dispersion in a set of data. The MAD describes what the expected deviation is whereas the STD is a bit more abstract. The usual example given concerns finding 68% of observations within 1 STD, 95% within 2 STD etc – but this is just the special case of the Normal Distribution.
Whilst it is true that STD can be used to give bounds like this for many more (finite mean and variance) distributions due to Chebyshev’s Inequality, the point remains that STD gains its informational content from knowing the distribution of the data – which is quite an assumption to assert in the real world. Partially due to this and partially due to attribute substitution on the back of the abstract definition of STD, the two concepts are quite commonly mixed up giving rise to talk about the ‘average deviation being x%’ when that quoted number happens to be the STD instead of the correct MAD.
The aim here is to show:
- how the MAD and STD are related
- how confusing the two can lead to serious issues
- when MAD is the only option
Quick definitions
The Mean Absolute Deviation (MAD) and Standard Deviation (STD) are both ways to measure the dispersion in a set of data. For a random variable, X, we can collect n observations {x_1, x_2, ..., x_n} to form a sample with the sample STD given by:
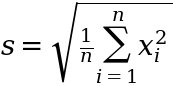
and the sample MAD given by:
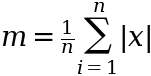
where in both cases we have assumed a mean of 0. It turns out that m < s no matter the distribution.
Why?
An intuitive answer is to think about each function as a weighted sum. With the MAD we give each value an equal weight of 1/n. With the STD however we weight each value by x_i/n i.e. because we square each value this means that we effectively applying a weighting to each value where the weight is the size of the deviation itself. This will have the effect of exaggerating large deviations by giving them a larger weight and vice versa.
Derivation in the gaussian case
It turns out we can derive the result that m < s fairly simply in the case of the normal distribution (as is almost always the case). What we want is a way to express the MAD in terms of the STD. Given that the STD by construction is parameterised in the normal distribution we can do this by taking the expectation of the MAD:
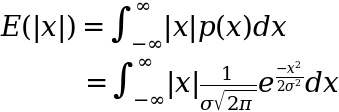
where the expectation is:
- the probability that we get a certain MAD – the
p(x) - times by that MAD – the absolute value term of
x
Now given that the normal distribution is symmetric we can:
- multiply it by 2 and integrate only from 0 to infinity (not from negative infinity) – so like folding it in half
- remove the absolute value sign as this is guaranteed by the fact we are only looking at the positive domain (integrating from 0 not negative infinity)
This gives us:
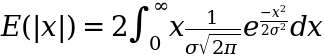
Now we need to do that bit of magic called ‘variable substitution’ that makes the whole integral much easier to work with. For the substitution let’s use the following:
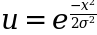
Differentiating to get x dx so we can substitute this into our integral we have:
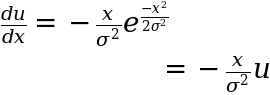
and so rearranging the above we get:
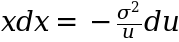
Plugging this in we have our substituted integral ready to go. Quite helpfully (as tends to be the case with these clever substitutions) the u‘s cancel and we end up with a fairly simple integral:
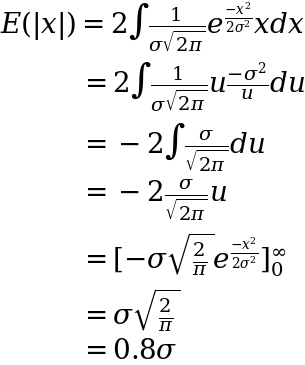
where in this final step we have:
- re-substituted back in for
upost integration and returned our integration bounds to{0, infinity} - calculated the definite integral
As a result we get that the MAD is around 0.8x the STD in the case of the normal distribution – or vice versa the STD is around 1.25x MAD.
What happens with fatter tails?
We can leverage our earlier intuition as the STD weighting every point according to the respective size of that point to answer this. With fatter tails we are more likely to get extreme large deviations. As these large deviations only get an equal weight in the MAD they will impact the STD much more than the MAD and as a result increase this ratio.
In the simple case of 1,000,000 moves where:
- 999,999 are -1
- 1 is 1,000,000
we will have MAD=2 but STD=1000 leading to our previous ratio of 1.25x blowing up to 500x.
What about with other distributions?
There‘s a great article here showing how this applies for the uniform distribution that follows the same process – derive the MAD and STD and then take their ratio. But how can we make the sweeping statement that MAD will always be less than or equal to the STD?
For that we can rely on Jensen’s inequality. Jensen’s inequality is an incredibly useful result that shows its face in almost all areas that deal with convexity and is to do with how the:
- average of two values from a convex function compares to
- the value from that convex function when taken at the average
This is much easier to see with a pictorial representation like below:
| # import usuals | |
| import numpy as np | |
| import matplotlib.pyplot as plt | |
| import seaborn as sns | |
| import warnings | |
| # bit of config | |
| %config Completer.use_jedi = False | |
| warnings.filterwarnings('ignore') | |
| sns.set() | |
| # create our convex shifted x squared function | |
| def convex_f(x): | |
| return 4 + x**2 | |
| # create points to plot that fn | |
| xs = np.linspace(0, 10, 101) | |
| ys = convex_f(xs) | |
| # create our straight line to represent the average of convex function | |
| xs_avg = np.linspace(2, 8, 81) | |
| ys_avg = np.linspace(convex_f(2), convex_f(8), 81) | |
| # plot it | |
| fig, ax = plt.subplots(figsize=(20,12)) | |
| ax.plot(xs, ys) | |
| ax.plot(xs_avg, ys_avg) | |
| # label it | |
| ax.set_title("Example of Jensen's Inequality with shifted x squared", fontsize=20) | |
| ax.set_xlabel('x', fontsize=14) | |
| ax.set_ylabel('f(x)', fontsize=14); |
 by
by 
The orange line represents the average of the function at 2 points (x=2 and x=8) and as we can clearly see this is always greater than the actual function at any linear combination of these 2 points – this is what Jensen’s inequality states. Back to the case of MAD vs STD we can write this as:
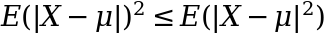
but the term on the right hand side is just the expression for the variance – given that the absolute value expression is redundant because we square the observations anyway. We can then express this as:
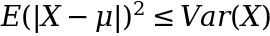
and then taking the square root gets us back to:
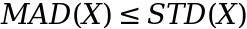
When does this cause issues?
Precisely because of the above result we will have that:
- most deviations will be smaller than the MAD
- there will be some larger than the MAD
- there will be some much larger than the MAD (depending on how much kurtosis your variable has)
This is required such that our average deviation is what it is – if we have some much larger values, then we must need lots only a little bit smaller to average out at our average.
If we are fine with one very bad result (or estimation error) being offset by a string of good results then this is no problem and confusing the 2 isn’t that problematic. However this is rarely the case in real life. A few examples include:
- once you lose all your money at blackjack you can’t win it back again incrementally (one large negative error wipes you out)
- a supermarket under-estimating how much stock to hold, running out completely one week and going bust isn’t offset by perfect prediction the following weeks
- Google Maps estimating your journey time – being 30 minutes early for a flight doesn’t offset being 30 minutes late and missing it
- any other example where you lose according to the square of the error or have absorbing barriers
In all the above examples if you were to base your decisions on the concept of the MAD and not factor in the fact that you can get much larger deviations (even in a gaussian world) then you run into trouble.
What about when the STD doesn’t exist?
The implicit assumption in the above is that we have a variable whose distribution has a finite variance. With a finite variance we have a finite (and thus comparable) STD. Due to the nature of sample Statistics we will always have a finite sample variance – to compute it we just grab all our data and plug it into the above equation for STD.
However there are cases when the population variance is infinite and so the only measure we have to compute dispersion is the MAD. We can still calculate the sample STD but this isn’t really a useful quantity anymore because it can’t be used to estimate the population parameter (because it doesn’t exist / is infinite). Examples are anything that follows a Paretian distribution:
- sizes of cities
- amount of time spent playing games on Steam (some get played a lot, lots get played very little)
In these cases understanding the MAD is essential because the STD isn’t going to get us anywhere.
Recap
In summary:
- MAD <= STD for all distributions due to Jensen’s Inequality
- confusing STD for MAD can lead to serious errors when we have a convex exposure to errors (one big error matters much more than a few offsetting smaller errors)
- sometimes MAD is the only option in situations where our true population has infinite variance







