
As data scientists, we experiment with different versions of code, models, and data. Additionally, we even use version control system like Git to manage our code, track versions, move forward and backward in time, and share our code with our teams.
The versioning of code is important because it helps reproduce software on a much larger scale. The versioning of data is important is because it helps develop machine learning models with similar metrics at any given time by any developer in your team or organization.
Therefore, it is crucial to version your models as well as data. But veteran software engineers will know that using Git for storing large files is a big no.
Not only is Git inefficient with larger files, it is also not a standardized environment for storing large data files. Most data is stored in AWS S3 buckets, Google Cloud Storage, or any institutional remote storage server.
So how do we version data? Enter DVC.
Introducing DVC
DVC is a system for Data Version Control that works hand in hand with Git to track our data files. It even has a similar syntax like Git so it’s quite easy to learn.
Let’s take a look at some of the great data versioning features of DVC in this article. But first, lets make a new project folder and a virtual environment and install it as a Python package:
$ pip install "dvc[all]"or if you use Pipenv:
$ pipenv shell
$ pipenv install "dvc[all]"You should see an output like so:

Now, lets initialize a git repository. You should see the following output:
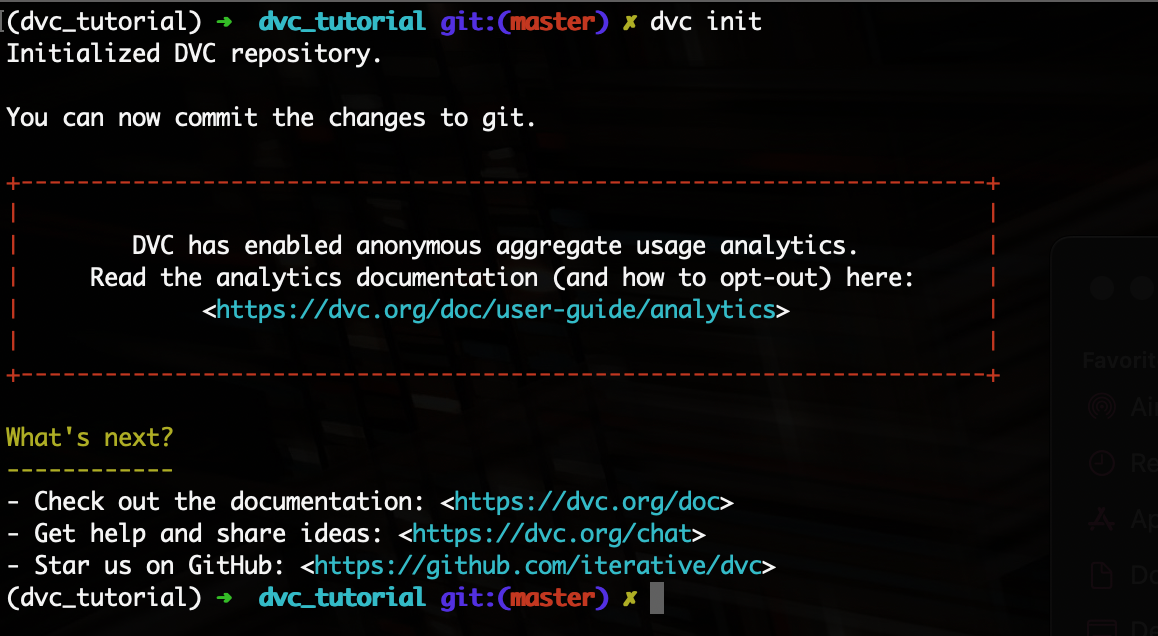
Perfect! We can now go ahead into adding our data into DVC.
Adding + committing data into DVC
I have one data file in my project’s data folder like so:
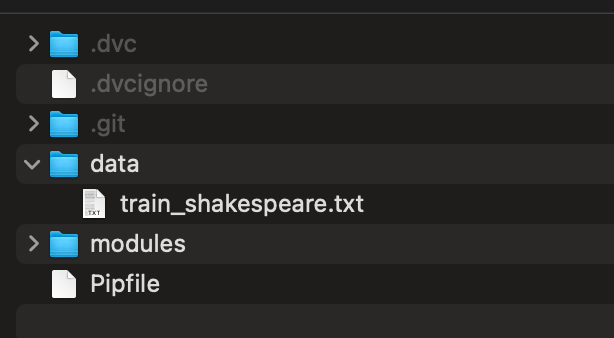
To run a size check from the terminal, use:
$ ls -lh dataYou’ll see the following output as the data file is displayed as 5.2 MB.

We can now add this data file to DVC. Run:
$ dvc add data/train_shakespeare.txtYou’ll see the following output, prompting us to run the git add command:
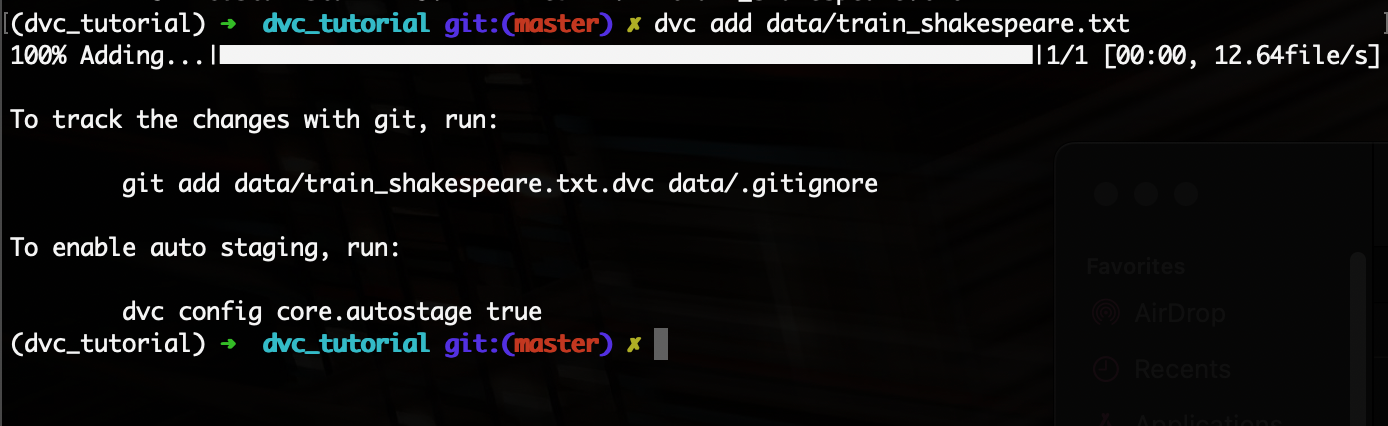
We will now run the git add command:
$ git add data/train_shakespeare.txt.dvc data/.gitignoreNow that we’ve added our new .dvc file to our git tracking, we can go ahead and commit it to our git:
$ git commit -m "added data."Setting up a remote storage for our data
We can simply utilize Google Drive for storing our versioned datasets and in this tutorial we’re going to do exactly that.
Let’s create a new folder in our Google drive and look at its URL:
https://drive.google.com/drive/u/0/folders/**cVtFRMoZKxe5iNMd-K_T50Ie**
Highlighted in bold is the ID of the folder that we want to copy to our terminal so that DVC can track our data in that newly created Drive folder.
Let’s do that:
$ dvc remote add -d storage gdrive://cVtFRMoZKxe5iNMd-K_T50IeTime to commit our changes to git:
$ git commit .dvc/config -m "Configured remote storage."Perfect! Now we can push our data to our remote storage.
$ dvc push It’ll ask for an authentication code or simply take you to perform authentication in your browser, simply follow the instructions and you’ll be good to go.
Pulling remote data
If you or your colleagues want to access the remotely stored data, it can be done with the pull command.
But first, let’s delete the data and its cache stored locally so that we can pull it from remote:
$ rm -f data/train_shakespeare.txt
$ rm -rf .dvc/cacheNow, pull:
$ dvc pullYou’ll see the following output on pulling the file:
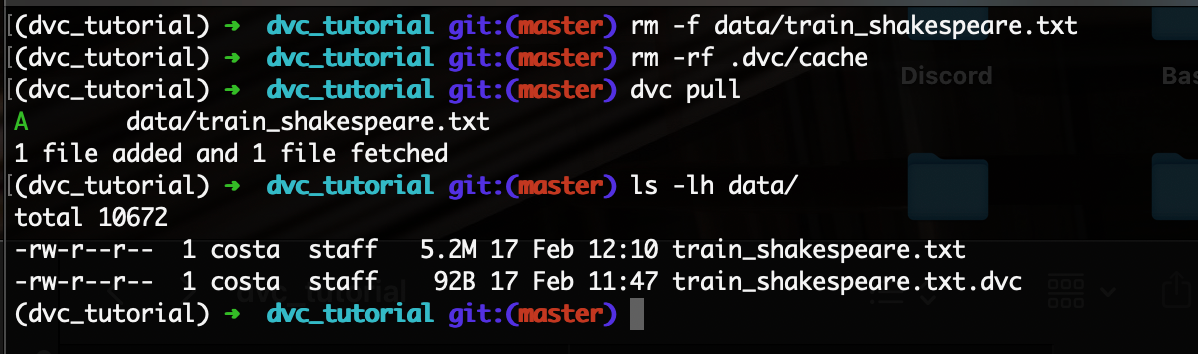
As you can see, once dvc is tracking your data file, pulling it from remote storage is a breeze.
Tracking a different version of data
Imagine if we want to track a new version of the same data file, we can easily add it to dvc and subsequently, to git again:
$ dvc add data/train_shakespeare.txt
$ git add data/train_shakespeare.txt.dvcNow, you’ll see a new version of the .dvc file is ready to be committed to our git:
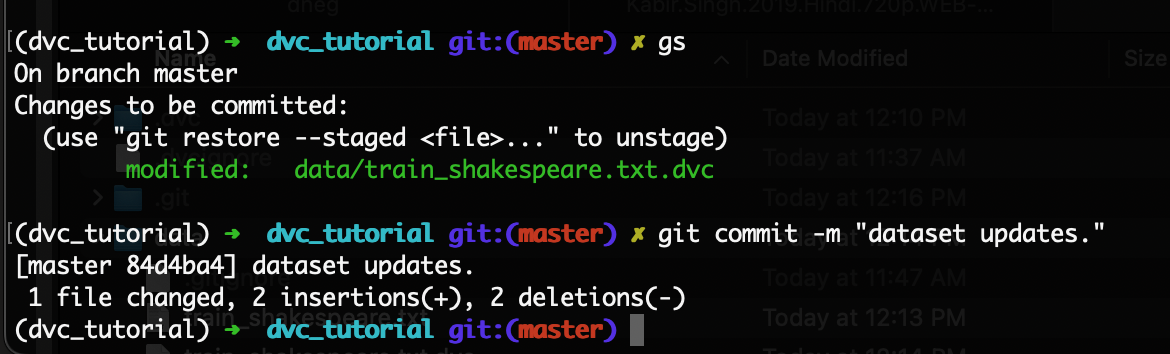
Commit the file.
Now, we can push our latest dataset to remote storage:
$ dvc pushLooking at our Google drive, we can see that we have two versions of our data stored:
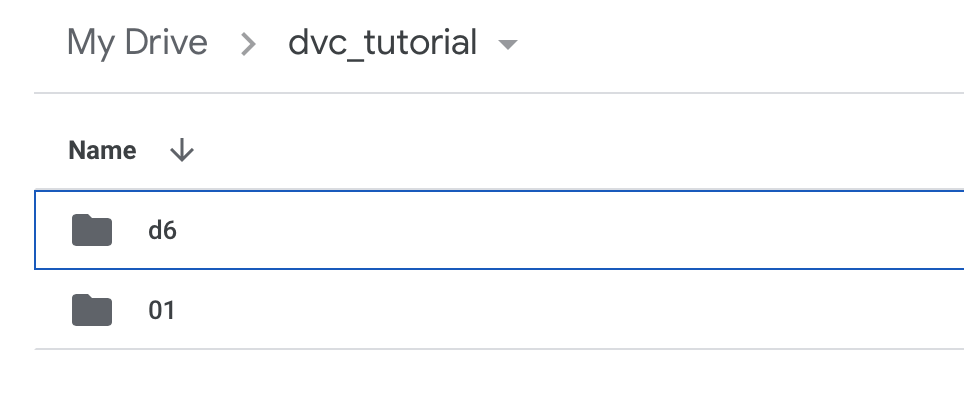
Returning to a different dataset version
With DVC, it become easy to go back in time to an older version of a dataset.
If we look at the git log of our project so far, we see that we have commited two .dvc file versions to git:

Therefore, we must go back to our previous version of the .dvc file, as that is the one git is tracking.
First, simply do a Git checkout to an older commit, like so:
$ git checkout HEAT^1 data/train_shakespeare.txt.dvc Second, do a checkout of dvc:
$ dvc checkoutYou’ll see the following output. We have now restored our data file to its previous version!
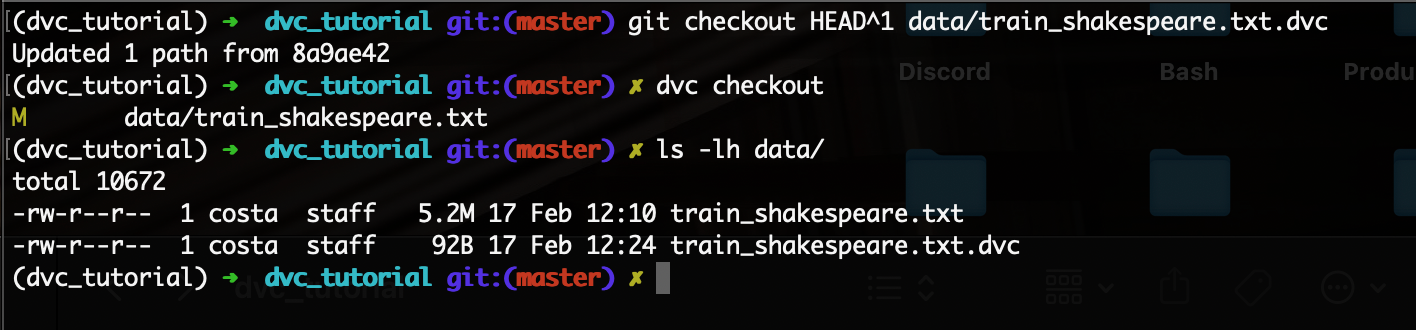
Additionally, if you want to keep these dataset changes, simply commit it to git again:
$ git commit data/train_shakespeare.txt.dvc -m "reverted data changes."Perfect! Till now, you have learned most of the fundamental data versioning features of DVC. Great job!
Final words…
DVC provides us with a massive helping hand in versioning datasets for our Data Science projects, and after this article, I hope you have some useful knowledge about getting started with it.
Practising on some sample projects and exploring the DVC documentation will be your best bet to advance your skill with this amazing tool.
If you liked this article, every week I put out a story in which I share little pieces of knowledge from the world of data science and Programming in general. Follow me to never miss them! 😄
You can also connect with me on LinkedIn and Twitter.
A couple of other articles from me that you may fancy reading:
The Reusable Python Logging Template For All Your Data Science Apps
The Easy Python CI/CD Pipeline Using Docker Compose and GitHub Actions






