Welcome to this exploration of LLM reasoning abilities, where we’ll tackle a big question: can models like GPT, Llama, Mistral, and Gemma truly reason, or are they just clever pattern matchers? With each new release, we’re seeing these models hitting higher benchmark scores, often giving the impression they’re on the verge of genuine problem-solving abilities. But a new study from Apple, "GSM-Symbolic: Understanding the Limitations of Mathematical Reasoning in Large Language Models", offers a reality check – and its findings could shift how we think about these capabilities.
If you are not a member, read here.
As an LLM Engineer for almost two years, I’m gonna share my perspective on this topic, including why it’s essential for LLMs to move beyond memorized patterns and deliver real reasoning. We’ll also break down the key findings from the GSM-Symbolic study, which reveals the gaps in mathematical reasoning these models still face. Finally, I’ll reflect on what this means for applying LLMs in real-world settings, where true reasoning – not just an impressive-looking response – is what we really need.
Why Does LLM Reasoning Matter?
In my view, the ultimate potential of LLMs goes far beyond predicting the next likely word in a sentence or echoing patterns from fine-tuning data.
The real challenge is in creating models that can genuinely generalize their reasoning.
Imagine an LLM that doesn’t just rely on past data but can face a completely new problem and solve it with high accuracy. This would transform LLMs from tools of narrow prediction into engines of real problem-solving in a broader way (really useful for humanoïd robot!).
We’re not quite there yet. While LLMs have shown remarkable progress, their true "reasoning" abilities are often limited to contexts they "know" based on patterns in the data they’ve seen before. The main question is: can they reach a point where they’re capable of flexible, reliable reasoning in unfamiliar territory? It’s a goal worth pursuing because a model that can genuinely generalize could be trusted to tackle new, unpredictable applications. This would open doors to areas where AI could make a real difference without the need for endless, specific fine-tuning.
The Benchmark Problem
Benchmarks like Massive Multitask Language Understanding (MMLU) test LLMs across diverse subjects to assess their adaptability. Yet studies like "GSM-Symbolic" reveal a key limitation: LLMs often rely on pattern matching over true reasoning. Even small tweaks to familiar questions can lead to inconsistencies, suggesting that high scores on benchmarks like GSM8K may reflect memorized patterns rather than real understanding. This raises a big question: Are these models actually reasoning or just pattern-matching based on data they’ve seen before?
The GSM-Symbolic study introduces a smart alternative. By creating new problem variations from symbolic templates, GSM-Symbolic challenges models in a way that pushes beyond mere familiarity with specific data. It tests models on different permutations of the same question, allowing us to see how well they adapt to variations and genuinely understand the logic, not just the pattern.
How LLMs Stumble on Simple Changes?

One of the most revealing aspects of the study was how Llm performance dropped when just the numbers in a problem were changed. It’s as if the models were relying on an exact memory of the problem rather than logically thinking through it from scratch. For us, this is trivial: if someone told you they’d changed 30 to 45 in a math question, you’d instantly adapt your solution. But for LLMs, a small variation like this can be hugely destabilizing.
I think this points to a fundamental gap between pattern recognition and true reasoning. When I see that even slight variations in problem phrasing cause these models to stumble, I can’t help but wonder if we’re measuring the wrong thing with traditional benchmarks.
Complexity and the Challenge of Noise
To push LLMs further, the researchers added irrelevant information (they call it "GSM-NoOp"). The aim was to find out if these models could focus on the essential parts of a problem and ignore any irrelevant details. This is a basic skill for humans of problem-solving, but LLMs didn’t fare well. When given extra information that didn’t change the core solution, model performance sometimes dropped by up to 65%. The models seemingly tried to integrate every detail into the answer, no matter how irrelevant, showing that they aren’t doing what we might call "abstract Reasoning."
If a model can’t filter out noise in a controlled math problem, how can it handle real-world situations where relevant and irrelevant information are mixed?
Why Does GSM-Symbolic Matter?
GSM-Symbolic offers a way forward by focusing on a broader distribution of problems, creating a more realistic test of reasoning. Rather than viewing LLMs as a finished product, this benchmark acknowledges their current limitations and encourages real progress forward.
The challenge here is that we’re not just asking LLMs to do math; we’re asking them to process logic at a level that resembles human thought. And GSM-Symbolic forces models to face the kind of question variations humans handle intuitively. It’s a crucial step if we want LLMs to move beyond memorizing patterns toward something closer to true reasoning.
A Call for Better Benchmarks
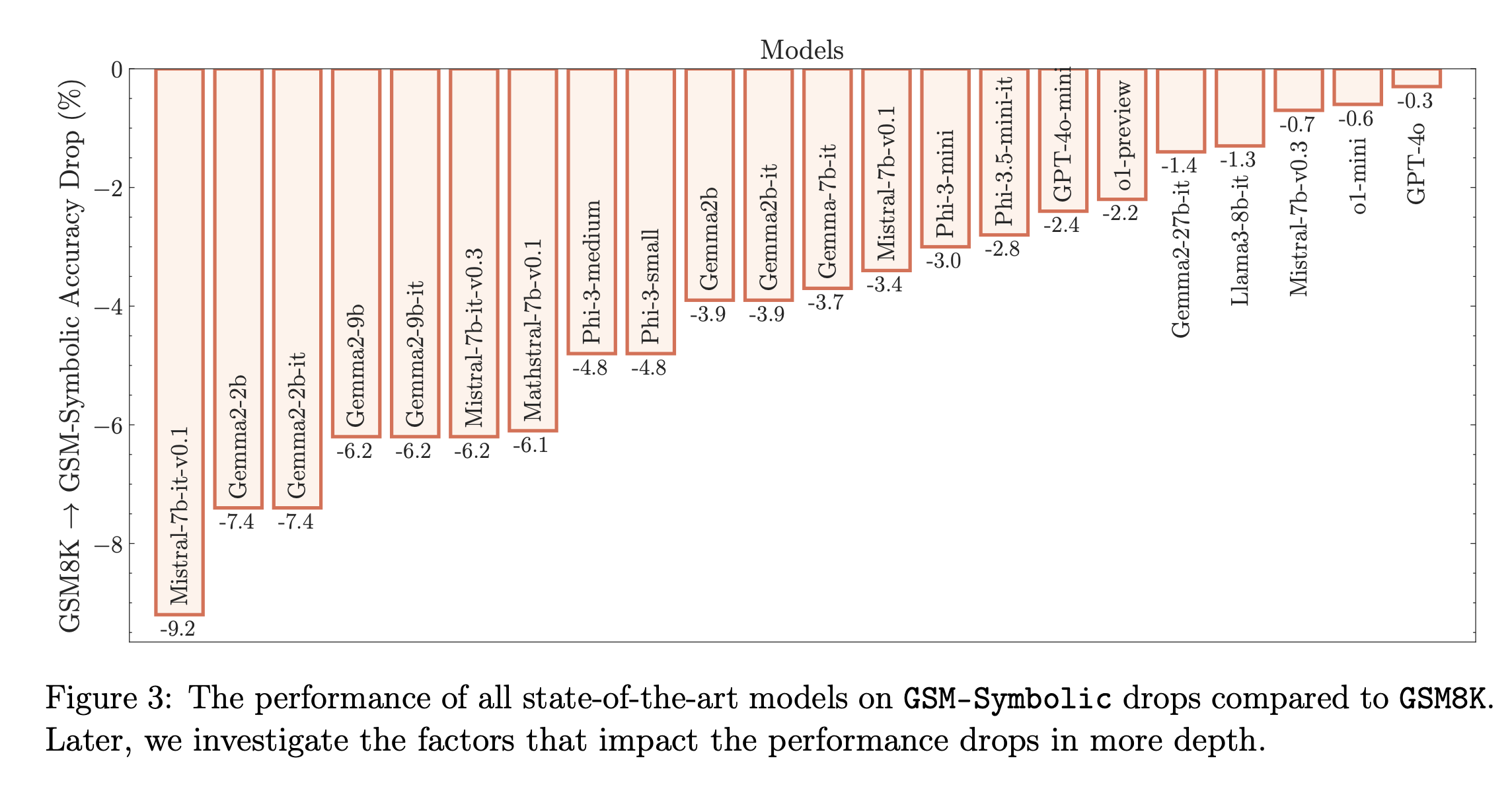
The current approach to LLM evaluation often feels like a game of numbers. We’re constantly hearing about models reaching new levels of accuracy, but the way these scores are computed often overshadows the question of what they truly represent. When we measure performance based on datasets that overlap with training data or even on problems too familiar to the model, we’re potentially measuring memorization more than understanding.
Conclusion
GSM-Symbolic shows us that while LLMs are remarkable, they’re still far from reasoning like we do. Real progress will come when we challenge them in ways that require true logic, not just repeating patterns they’ve seen before. With smarter benchmarks, we can get a clearer picture of their actual capabilities – and figure out what it’ll take to help them reach the next level.
Loved the Article? Here’s How to Show Some Love:
- Clap 50 times – each one truly helps!

- Follow me here on Medium and subscribe for free to catch my latest posts.
 ️
️ - Let’s connect on LinkedIn, check out my projects on GitHub, and stay in touch on Twitter
References
[2] Artificial Analysis, LLM Leaderboard by Artificial Analysis (2024)
[3] Hugging Face, Open LLM Leaderboard (2024)
[4] OpenLM.ai, Chatbot Arena (2024)
[5] D. Hendrycks et al., Measuring Massive Multitask Language Understanding, ICLR (2021)
[6] Cobe et al., Training Verifiers to Solve Math Word Problems (2021)



