In less than two months since its first release, Apple’s ML research team’s latest creation, MLX, has already made significant strides in the ML community. It is remarkable to see how quickly the new framework has garnered attention, as evidenced by over 12k stars on GitHub and a growing community of over 500 members on Hugging Face 🤗.
In a previous article, we demonstrated how MLX performs in training a simple Graph Convolutional Network (GCN), benchmarking it against various devices including CPU, PyTorch’s MPS, and CUDA GPUs. The results were enlightening and showed the potential of MLX in running models efficiently.
In this exploration, we delve deeper, setting out to benchmark multiple key operations commonly leveraged in neural networks.
Test bed
In our benchmark, each operation is evaluated based on a variety of experiments, varying in input shape and size. We’ve run these sequentially and multiple times across different processes to ensure stable and reliable runtime measures.
In the spirit of open collaboration, we’ve made the benchmark code open-source and easy to run. This allows contributors to easily add their own benchmarks based on their device and config.
GitHub – TristanBilot/mlx-benchmark: Benchmark of Apple’s MLX operations on all Apple Silicons…
Note: many thanks to all contributors, without whom this benchmark wouldn’t comprise as many baseline chips.
We successfully ran this benchmark across 10 different Apple Silicon chips and 3 high-efficiency CUDA GPUs:
Apple Silicon: M1, M1 Pro, M1 Max, M2, M2 Pro, M2 Max, M2 Ultra, M3, M3 Pro, M3 Max
CUDA GPU: RTX4090 128GB (Laptop), Tesla V100 32GB (NVLink), Tesla V100 32GB (PCIe).
Benchmark results
For each benchmark, the runtime is measured in milliseconds. Both MPS and CUDA baselines use the operations implemented within PyTorch, whereas Apple Silicon baselines use MLX’s operations.
Linear layer
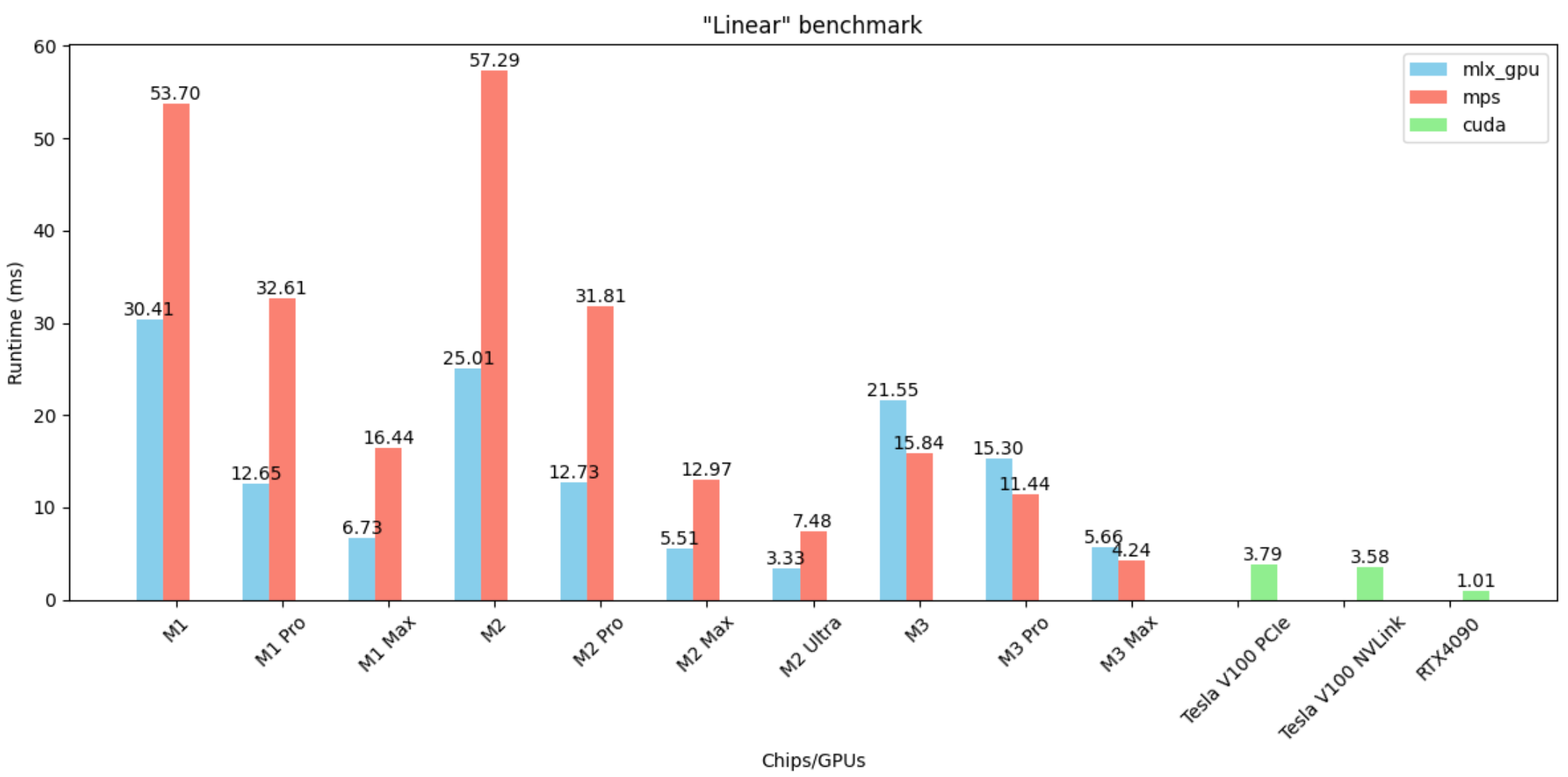
- MLX is ~2x faster than MPS but worse on M3* chips
- The best performing M2 Ultra chip is faster than the two Tesla V100 GPUs! The RTX4090 remains 3x faster than the M2 Ultra.
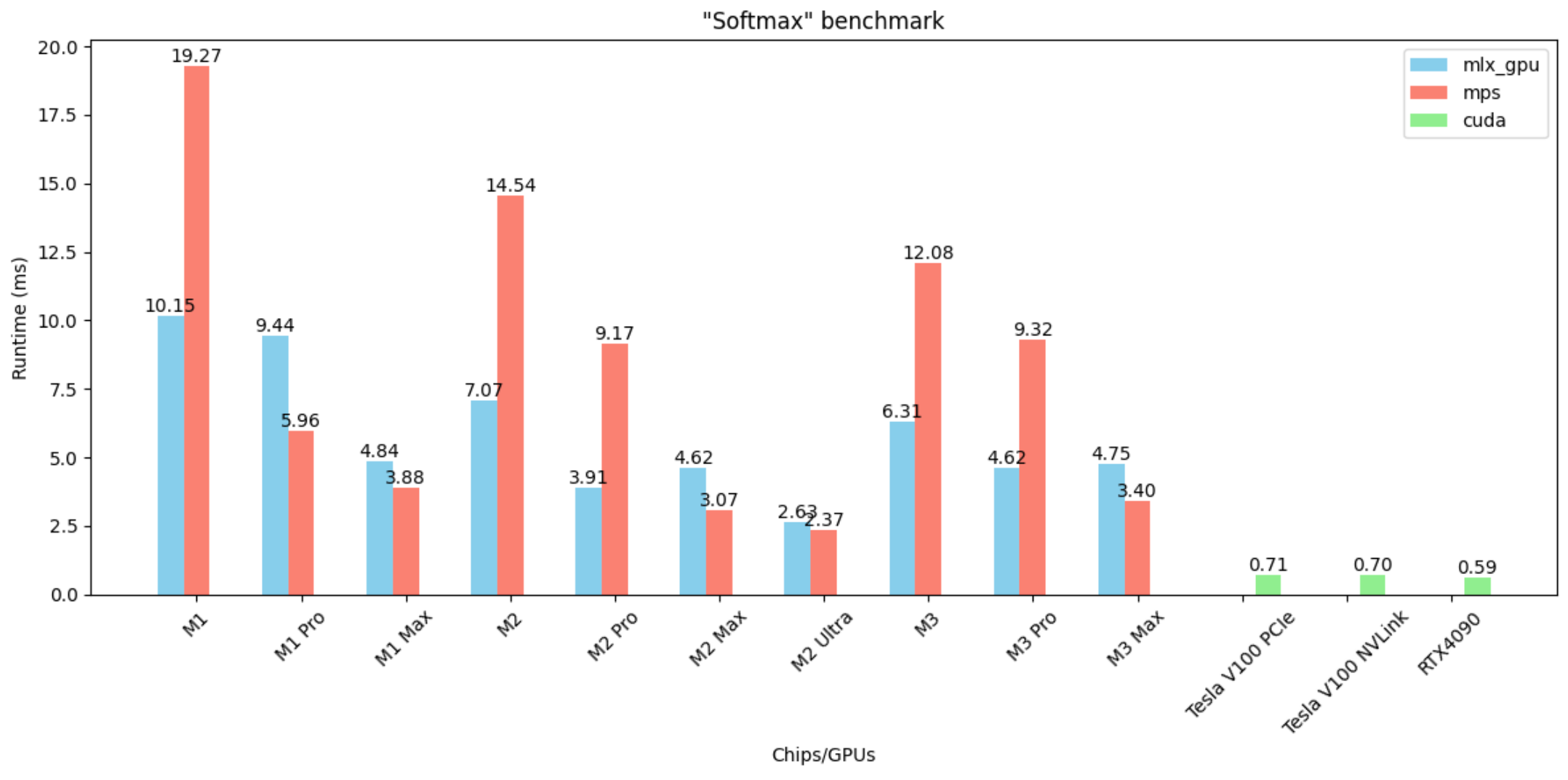
Softmax

- MLX is up to 2x faster than MPS on some chips
- CUDA GPUs are ~10x faster than M2 and ~4x faster than M2 Ultra
Sigmoid

- MLX is ~30% faster than MPS on all chips
- M2 Max is faster than M2 Ultra here
Concatenation
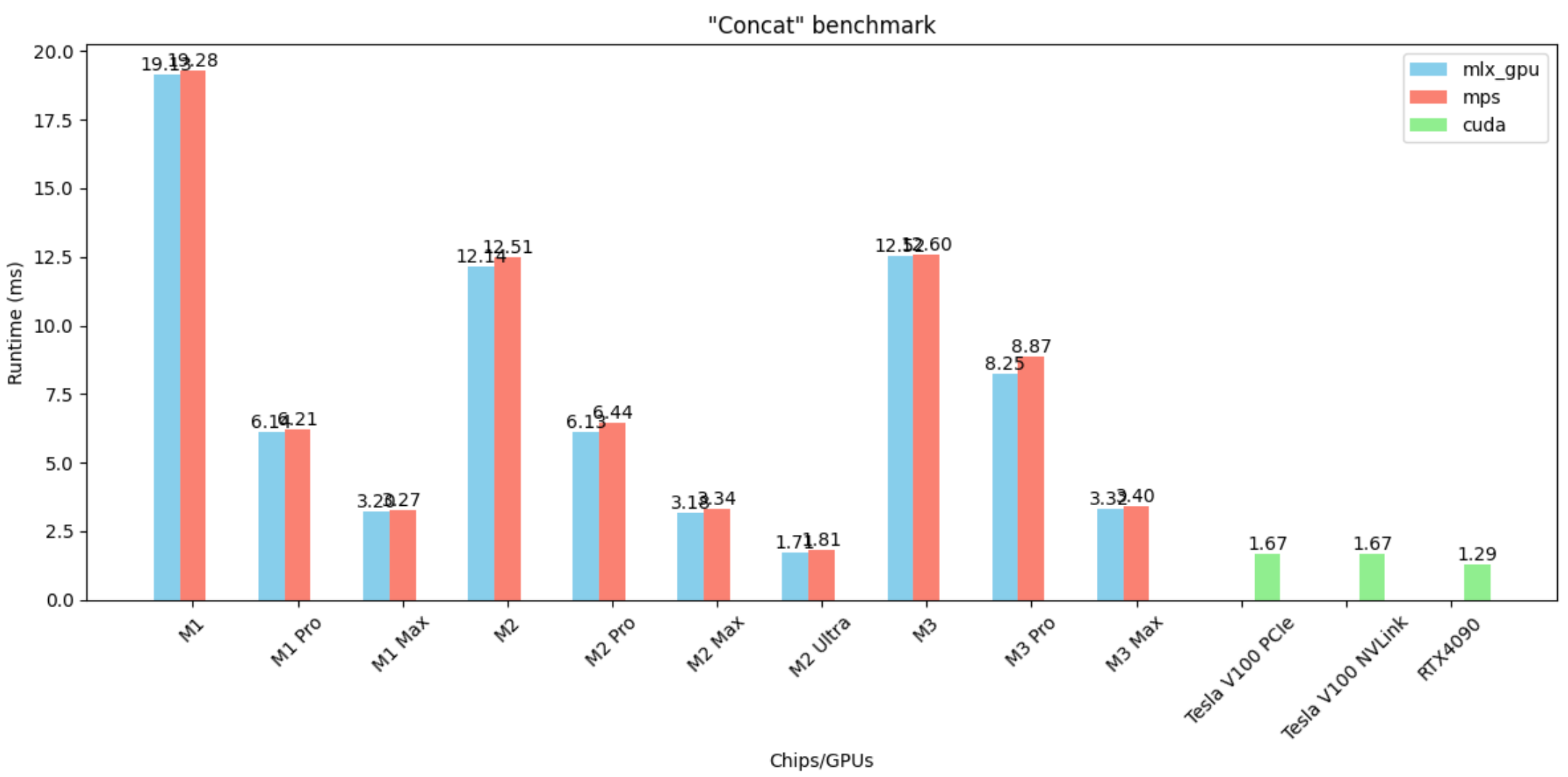
- MLX and MPS are almost equivalent
- No big difference between CUDA GPUs and M2 Ultra, whereas M3 is particularly slow here
Binary Cross Entropy (BCE)

- The MPS implementation of BCE seems extremely slow on M1 and M2
- M2 Max, M2 Ultra and M3 Max are only ~3x slower than CUDA GPUs
Sort
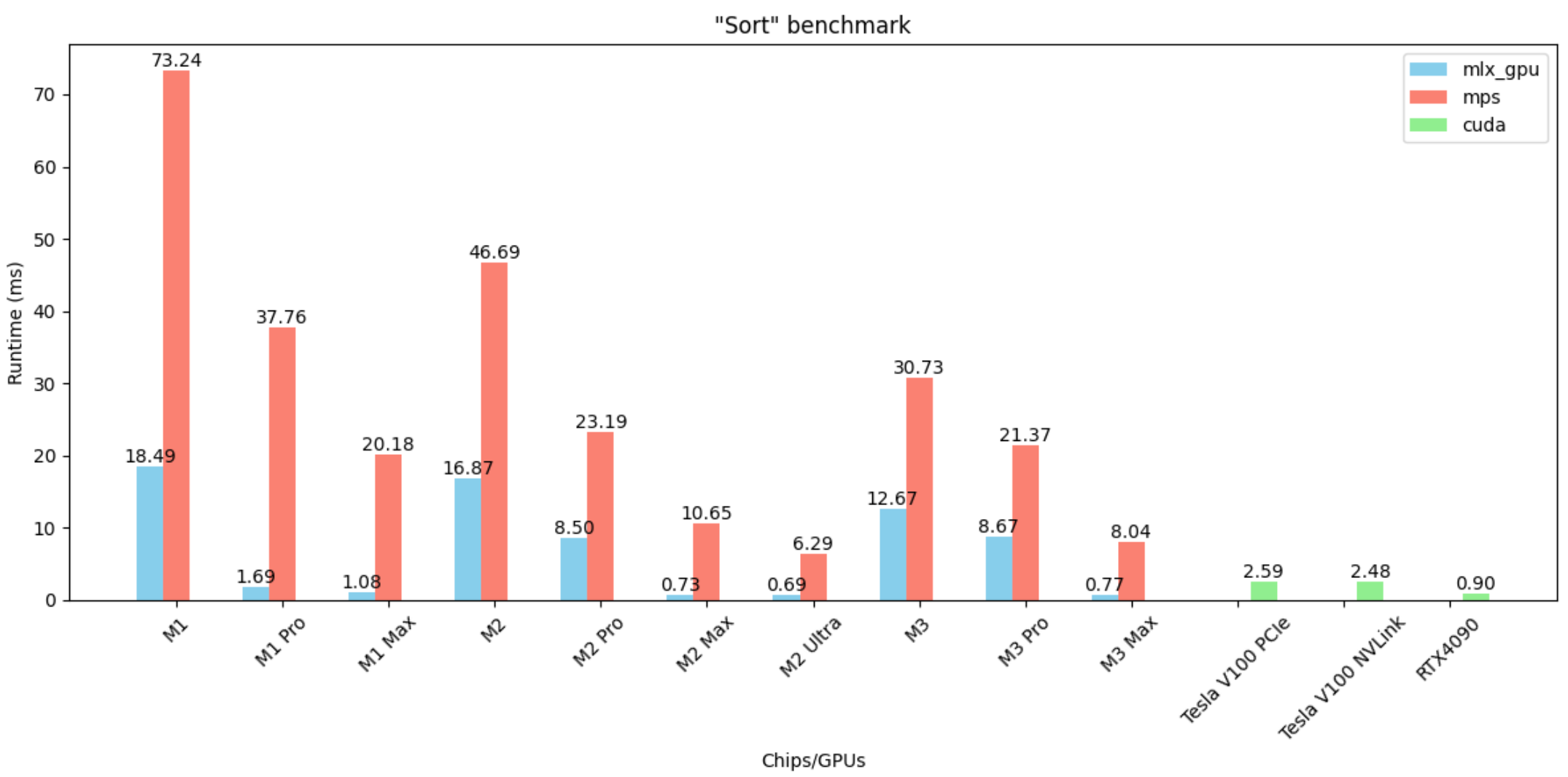
- MLX’s sort is really fast.
- On M2 Max, M2 Ultra and M3 Max, it achieves better performance than all CUDA GPUs, including the recent RTX4090
Conv2D
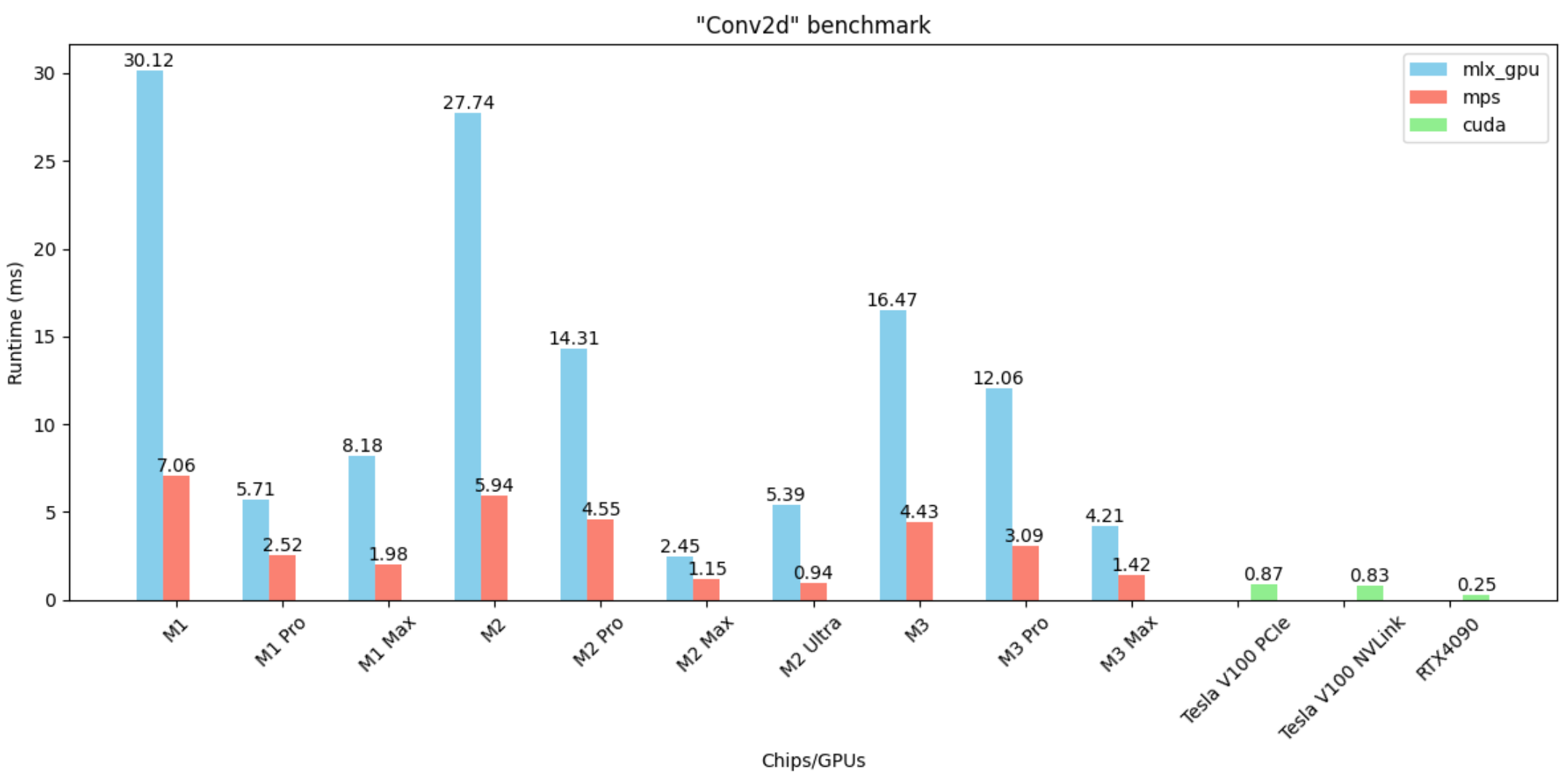
- MLX is 2–5x slower than MPS
- RTX4090 is particularly fast on this operation
Discussion
Results
Our benchmarks have led to some the following findings:
- MLX running on Apple Silicon consistently outperforms PyTorch with MPS backend in the majority of operations.
- CUDA GPUs remain inevitably faster than Apple Silicon.
- Notably, MLX excels in certain operations, such as Sort and Linear, demonstrating strong efficiency even compared to CUDA GPU benchmarks.
- The convolution operations are still particularly slow with MLX. It seems that MLX’s team is currently working on improving the speed of these operations.
Note: curious readers may be interested in checking the comprehensive set of operations available in the benchmark.
Apple Silicon vs CUDA GPU
While CUDA GPUs are undeniably faster, it’s crucial to take a step back and consider the broader picture. Nvidia has spent years perfecting its GPU technology, reaching a level of maturity and performance that currently stands unrivaled. When you weigh the differences in hardware sophistication, maturity, and cost between Nvidia GPUs and Apple Silicon chips, it offers a significant perspective.
This is where MLX comes into its own. This framework becomes particularly beneficial in scenarios where one needs to run large models on their personal Mac. With MLX, you can achieve this without the need for additional, expensive GPU hardware. It’s a game-changer for those seeking efficient machine learning capabilities directly on their Mac devices.
Notably, running LLM inference directly on Apple Silicon with MLX has gained increasing popularity recently.
Unified memory changes the game
Apple Silicon stands out in the GPU landscape with its unified memory architecture, which uniquely leverages the entirety of a Mac’s RAM for running models. This is a significant change compared to traditional GPU setups.
But perhaps the most striking advantage of using Apple Silicon is the elimination of data transfers between the CPU and GPU. This might sound like a small detail, but in the real world of machine learning projects, these data transfers are a notorious source of latency. Our previous article highlighted this aspect, showing very different benchmark results when accounting for data transfer times during training:

These results show the average training time per epoch of a Graph Convolutional Network model, essentially composed of two linear layers. Differing from the benchmarks in this article, this specific benchmark evaluates the average runtime of a complete training loop, including the time for data transfers from CPU to GPU.
These results bring an interesting insight to light: the performance of CUDA GPUs noticeably slows down when real data transfer times are included. This underlines the significant impact that data transfers have on overall speed, a factor that we can’t overlook in the current benchmark.
Conclusion
This benchmark gives us a clear picture of how MLX performs compared to PyTorch running on MPS and CUDA GPUs. We found that MLX is usually much faster than MPS for most operations, but also slower than CUDA GPUs.
What makes MLX really stand out is its unified memory, which eliminates the need for time-consuming data transfers between the CPU and GPU.
In a future article, we plan to include data transfer times in our benchmarks. This could offer a more comprehensive understanding of MLX’s overall efficiency.
— – – – – – – –
Thx for reading!
— Special thanks to Ian Myers for spotting issues on the previous CUDA benchmarks.





