Thoughts and Theory, Compositionality & Graphs
This blog post was co-authored with Etienne Denis and Paul Wu and is based on our paper "NodePiece: Compositional and Parameter-Efficient Representations of Large Knowledge Graphs".

Knowledge graphs (KGs) keep growing larger and larger: Wikidata has about 100M nodes (entities), YAGO 4 is about 50M nodes, and custom graphs like Google KG or Diffbot are orders of magnitude larger  .
.
Performing any machine learning (ML) or graph representation learning (GRL) tasks on them usually implies embedding entities and relations into a latent space by mapping each entity and relation to a unique vector (or sometimes many vectors, or whole unique matrices). We usually refer to those as shallow embeddings.
Shallow Embedding: Limitations
Pretty much all existing KG embedding algorithms (like TransE, RotatE, DistMult, etc) are shallow.
Even GNN-based models with learnable entity embeddings matrix, e.g., CompGCN, have a shallow lookup layer before message passing.
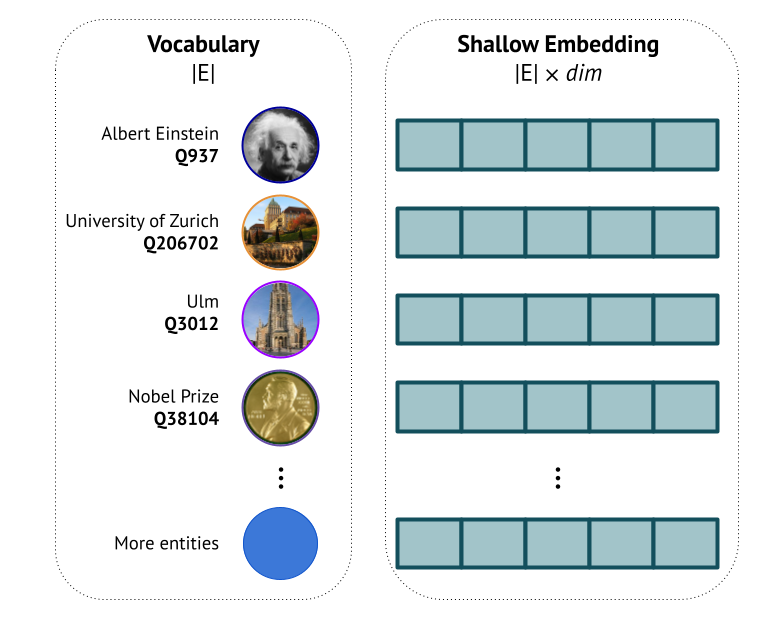
Essentially, shallow means embedding lookup: for a vocabulary of |E| entities, you must have |E| d-dimensional rows in the embedding matrix ( 
 ). That is, 100 entities = 100 rows, 10K entities = 10K rows, 100M entities = 100M rows, and so on. Now multiply # of rows by embedding dimension to get an approximate number of learnable parameters (# of relations |R| is much much smaller than |E| so we focus on entities mostly). And the whole embedding matrix resides in a precious GPU memory
). That is, 100 entities = 100 rows, 10K entities = 10K rows, 100M entities = 100M rows, and so on. Now multiply # of rows by embedding dimension to get an approximate number of learnable parameters (# of relations |R| is much much smaller than |E| so we focus on entities mostly). And the whole embedding matrix resides in a precious GPU memory  .
.
By the way, classical graph embedding algorithms like node2vec are shallow as well since they also map each node to a unique vector.
What happens when scaling to a merely sized WikiKG 2 graph of 2.5M entities from the Open Graph Benchmark (OGB)? Well, … 
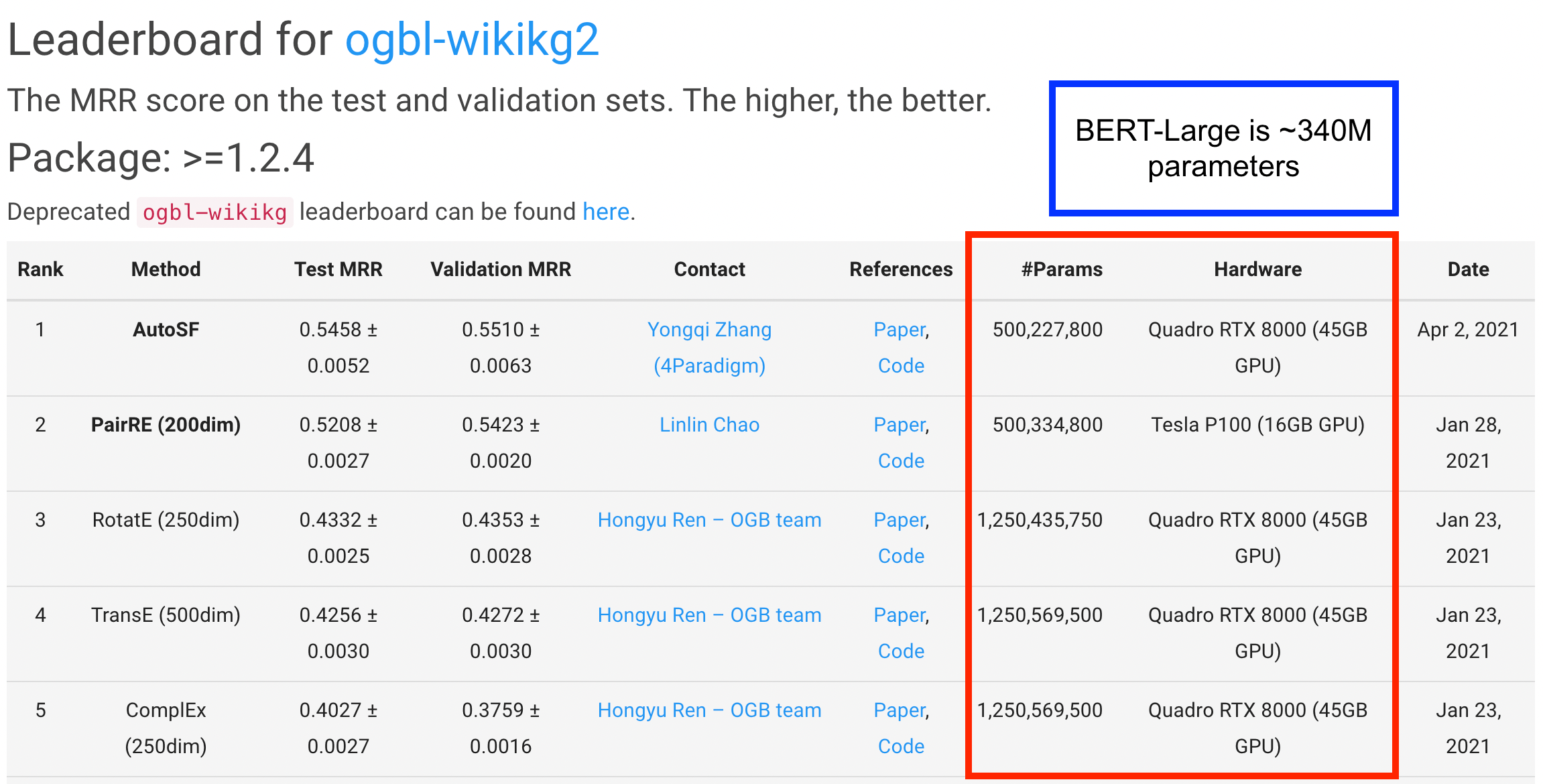
So the model size varies in between 500M-1.25B parameters (and you need a  -expensive GPU with 45 GB VRAM or reduce the embedding dimension)
-expensive GPU with 45 GB VRAM or reduce the embedding dimension) 
 Hold on, how large is BERT that revolutionized NLP or GPT-2 that was deemed "too dangerous to be publicly released"? 340M and 1.5B parameters, respectively. So you might have a naturally emerging question:
Hold on, how large is BERT that revolutionized NLP or GPT-2 that was deemed "too dangerous to be publicly released"? 340M and 1.5B parameters, respectively. So you might have a naturally emerging question:
Are we spending our parameter budget efficiently? Why are 1.25B WikiKG embeddings not SO dangerous?
(well, apart from energy consumption on training)
I’m sure you know that better than me:
- LMs have a small fixed-size vocabulary and a powerful encoder on top of this vocabulary (variations of Transformer, of course);
- That small fixed-size vocabulary allows to process any word, even those unseen during training;
- That small fixed-size vocabulary is still sufficiently wide (768–1024d).
On the other hand, what do we have in shallow embedding models? (Here we arrive at the Header picture  )
)
- Only a vocabulary of entities and relations, no general-purpose encoder;
- A giant vocabulary eats up all the parameter budget. Either the vocabulary size grows too large, or you have to reduce dimensionality to keep the overall size reasonable.
- Transductive-only setup – no ability to build representations of unseen nodes, they are OOV (out-of-vocabulary).
Do those shallow properties remind you of anything?  Welcome back to 2014!
Welcome back to 2014!

Detour: From word2vec to Byte-Pair Encoding
What did NLP folks do in the pre-historic pre-Transformer times?

Word2Vec and GloVe provided matrices of 400K – 3M pre-trained word embeddings (and sometimes phrases). Anything beyond those 400K – 3M words falls into the OOV (out-of-vocabulary  ) category. Similarly, if at inference time you receive an unseen word – you have to replace it with the token.
) category. Similarly, if at inference time you receive an unseen word – you have to replace it with the token.

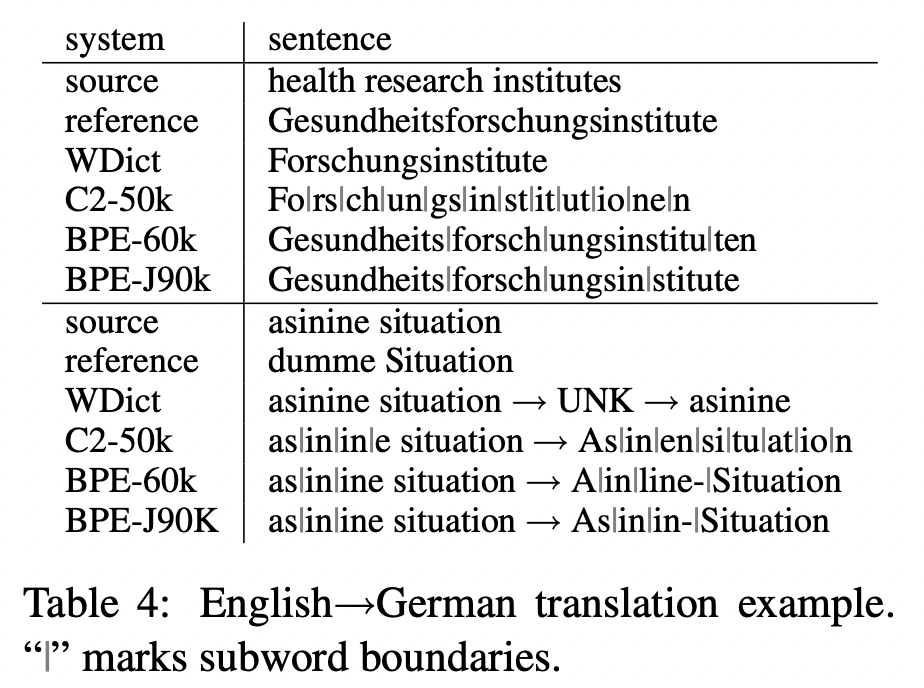
In the end, no matter how we expand the words vocabulary, we’ll never be able to fully capture all of them due to the compositional nature of language  . Soon, the community realized that we need a more compositional mechanism to represent any word, seen or unseen, using the same set of atoms
. Soon, the community realized that we need a more compositional mechanism to represent any word, seen or unseen, using the same set of atoms  . The year 2015 was rich in such approaches:
. The year 2015 was rich in such approaches:
- character-based models where atoms are essentially the alphabet
 with some auxiliary symbols;
with some auxiliary symbols; - "word pieces"
 or "subword units" models introduced in the seminal work of Sennrich et al where atoms are most common n-grams. Algorithms implementing those subword units as Byte-Pair Encoding (BPE) in subword-nmt or WordPiece/SentencePiece became a de-facto standard pre-processing step in all modern neural language models.
or "subword units" models introduced in the seminal work of Sennrich et al where atoms are most common n-grams. Algorithms implementing those subword units as Byte-Pair Encoding (BPE) in subword-nmt or WordPiece/SentencePiece became a de-facto standard pre-processing step in all modern neural language models.
Now, using a finite vocabulary of atoms, it is possible to build pretty much an infinite number of combinations-words, any unseen word can be tokenized into a sequence of chars or word pieces, and there is no OOV issue!
Furthermore, you don’t need to store 3M-large vocabulary matrices as input embeddings. Using word pieces, typical vocabularies are much smaller. 
- BERT: 30K WordPiece tokens
- GPT-2 & GPT-3: 50K BPE tokens
So why don’t we adopt this for the Graph ML domain?
If nodes are "words", can we design a fixed-size vocabulary of "sub-word" (sub-node) units for graphs?
Tokenizing KGs with NodePiece
 We tackle this very research question in our recent work where we propose NodePiece as a compositional "node tokenization" approach for reducing vocabulary size in large KGs. Instead of storing huge entity embedding matrices, we suggest learning a fixed-size vocabulary of atoms and a simple encoder that will be able to bootstrap representations of any node from a sequence of atoms in the same way as words are constructed from a sequence of subword units.
We tackle this very research question in our recent work where we propose NodePiece as a compositional "node tokenization" approach for reducing vocabulary size in large KGs. Instead of storing huge entity embedding matrices, we suggest learning a fixed-size vocabulary of atoms and a simple encoder that will be able to bootstrap representations of any node from a sequence of atoms in the same way as words are constructed from a sequence of subword units.
In NodePiece, vocabulary atoms (or "node pieces", or "tokens", if you prefer) are anchor nodes and relation types. Anchor nodes are a subset of existing nodes in the graph and can be selected randomly or according to some centrality measures like PageRank or node degree. You don’t need many anchor nodes (as you don’t need all possible n-grams in the tokens vocabulary) – we found that, often, 1–10% is enough. And sometimes you don’t even need anchor nodes at all  !
!
All relation types are included in the vocabulary as, often, there are not so many of them compared to the total number of nodes (entities).
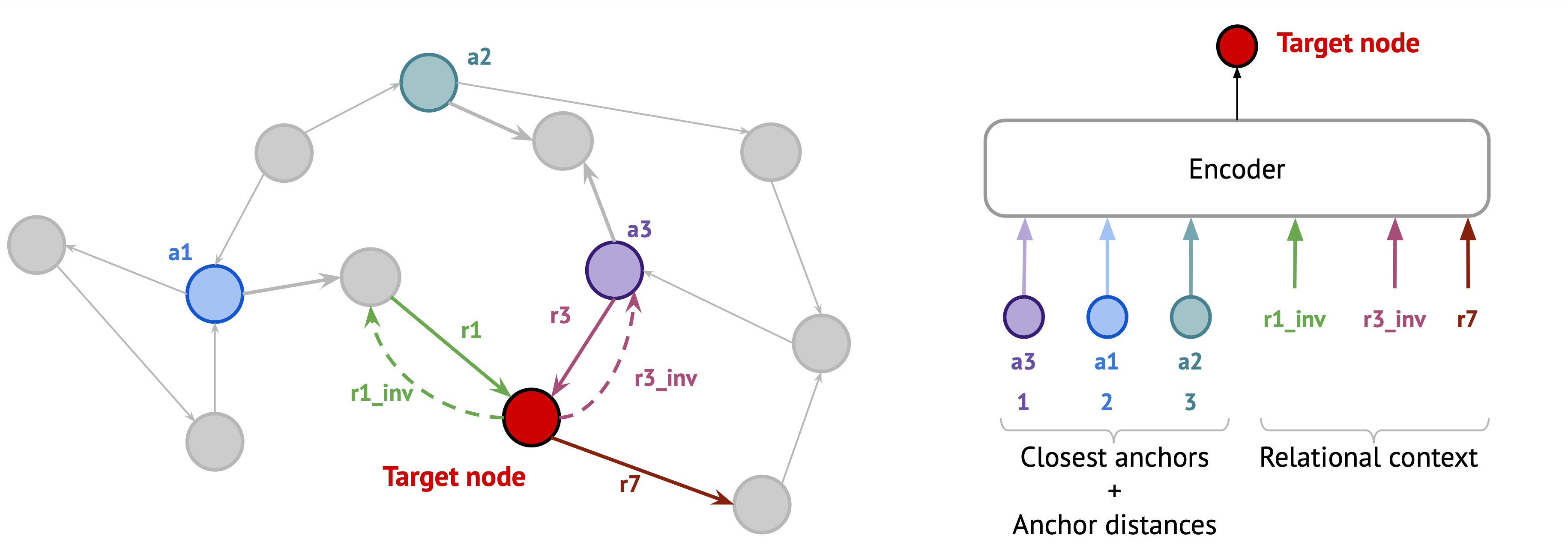
So how do we tokenize an arbitrary node in a graph? Let’s follow the illustration with a basic intuition.
Suppose we want to tokenize the red node  given anchors and several relation types.
given anchors and several relation types.
- We find k nearest anchors using BFS and arrange them in a sequence of ascending order of their distances to (k=20 if often enough).
- Anchor distances are scalars akin to positional encodings that help to localize (or "triangulate") node in a graph and attribute it to the anchor nodes. Similar to positional encodings, we add k anchor distance embeddings to k respective nearest anchor nodes.
- In large KGs, some "hash collisions" are still possible, so the third ingredient
 is the node relational context of m __ unique outgoing relations emitted from (note that a standard pre-processing step of adding inverse edges to the graph is very helpful as we maintain full reachability of every node). Depending on the KG size and density, we vary m from 3 to 15.
is the node relational context of m __ unique outgoing relations emitted from (note that a standard pre-processing step of adding inverse edges to the graph is very helpful as we maintain full reachability of every node). Depending on the KG size and density, we vary m from 3 to 15. - Now, we have a k+m sequence of tokens that uniquely identifies any node. Any injective pooling (sequence encoder like MLP or Transformer) can be used to encode the k+m sequence into a unique embedding vector which is the node embedding we have been looking for.
 Let’s see how this sequence might look like by tokenizing Albert Einstein in Wikidata terms. Suppose we have already pre-selected some anchors, and we could use three nearest:
Let’s see how this sequence might look like by tokenizing Albert Einstein in Wikidata terms. Suppose we have already pre-selected some anchors, and we could use three nearest: Ulm, Nobel Prize, Theoretical Physics. All of them are found in the 1-hop neighborhood of Einstein, so their anchor distances are 1’s. As a relational context, we randomly sample 4 unique outgoing relation types, e.g., place of birth , award received , occupation , academic degree . Therefore, our Einstein entity is tokenized using 7 atoms . Naturally, the bigger the KG, the more anchors you’d want to use to ensure the sequence is more unique, although we found there is a saturation point around 20 anchors per node even in million-node graphs.

An encoder function f is applied to the tokenized sequence, and we reconstruct a unique node embedding of Einstein.
 This node embedding can be sent to your favorite model in any downstream task, e.g, node classification, link prediction, or relation prediction, or something else in both transductive or inductive settings.
This node embedding can be sent to your favorite model in any downstream task, e.g, node classification, link prediction, or relation prediction, or something else in both transductive or inductive settings.
What are the immediate benefits of NodePiece?
- Dramatic vocabulary and embedding size reduction
 : only |A| anchor nodes instead of all |E| nodes. Depending on a task, we experiment with 10x, 100x, 1000x reduction rate and still observe competitive results (more on that below);
: only |A| anchor nodes instead of all |E| nodes. Depending on a task, we experiment with 10x, 100x, 1000x reduction rate and still observe competitive results (more on that below); - Saved parameter budget can now be invested into an expressive encoder which builds node representations;
- Inductive capabilities out of the box! Any new unseen incoming node that attaches to a seen graph can be "tokenized" using the same vocabulary and encoded through the same encoder. That is, there is no need to invent sophisticated approaches or scoring functions for that – you can still use TransE / ComplEx / RotatE / (put your fav model) as a scoring function!
Experiments: Some numbers 
We conducted a number of experiments including transductive and inductive link prediction on standard benchmarks like FB15k-237 and YAGO 3–10, but here let’s focus on particularly interesting phenomena.
First, what happens if we reduce the vocabulary size by a factor of 10? That is, we only keep 10% of original nodes as anchors (enjoying 10x parameter reduction), the rest are reconstructed from them through an MLP. We employ the NodePiece vocabulary and encoder together with several state-of-the-art task-specific decoder models (e.g., RotatE on relation prediction and CompGCN on node classification, respectively)

On relation prediction, 10x node vocabulary reduction is, in fact, quite competitive on all datasets being either on par or better than the baseline in terms of Hits@10.
The ablation study reveals an interesting phenomenon -having 0 anchors does not affect the performance on relation-rich graphs like FB15k-237 and YAGO 3–10, so you don’t need node/anchor embeddings at all  ! Just a few relations in the relational context with the encoder are pretty much enough for a very good performance.
! Just a few relations in the relational context with the encoder are pretty much enough for a very good performance.
Is it something unique for the relation prediction task?
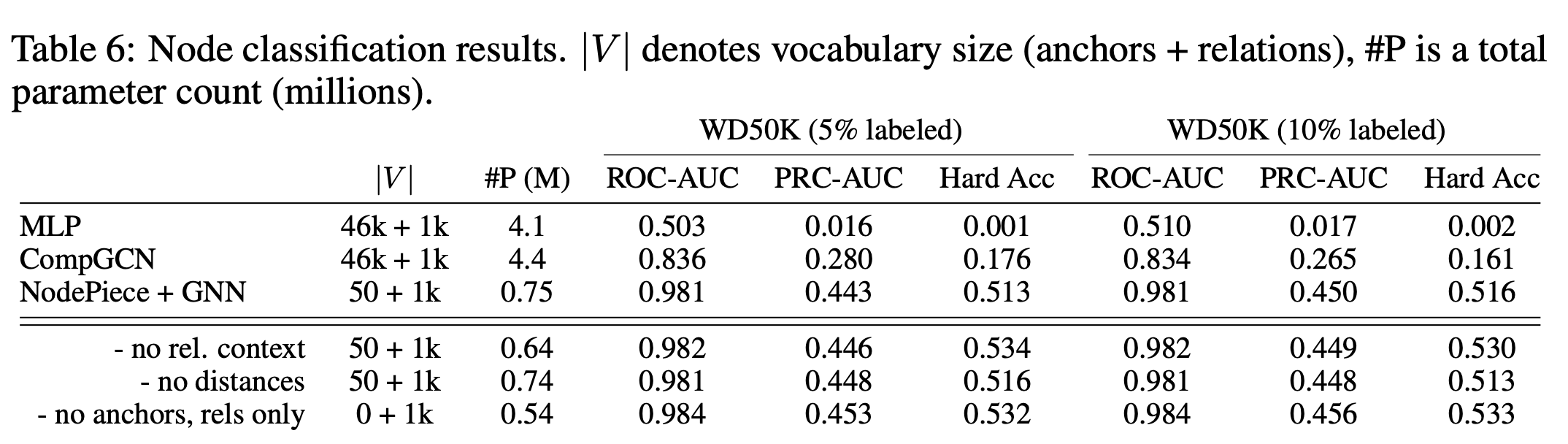
Turns out, it is not! In node classification (here it is a multi-class multi-label problem with ~500 labels), we reduce the vocabulary size by almost 1000x (50 anchors in a 46K nodes graphs) and observe an actual improvement along all metrics which might suggest that the baselines are already quite overparameterized.
And again, if we completely drop the vocabulary of node embeddings having 0 anchors, the numbers get slightly better. That is, just a relational context seems to be enough for node classification, too!
This finding corresponds well to a recently started research trend:
The contirbution of relations is still underestimated in KG representation learning.
KGs are multi-relational graphs and this is yet to be fully leveraged. We think that even more relation-aware encoding approaches (being them 1-hop context, relational paths, or a new Neural Bellman-Ford framework) will appear in the near future.
Takeaways and Resources
- Compositional encoding of entities akin to "tokenization" works on KGs!
- Compositional encoding is inductive by design – we can build an infinite amount of combinations (entities) from a finite vocabulary.
- Vocabulary reduction allows investing more parameters into powerful encoders.
- NodePiece tokenization can augment any existing downstream KG task.
- Almost no performance drop: the overall performance level is comparable to much bigger shallow embedding models.
- In relation-rich graphs, just a few relations with 0 anchors can be sufficient for certain tasks.
Paper: Pre-print on Arxiv Code: Github repo









