Update : explains how to fix issue on LSTM validation accuracy.
—
As everybody already knows the new Apple Silicon M1 Macs are incredibly powerful computers. By seeing the benchmarks and all the real-life test performed everywhere, as a machine learning engineer I’m really thinking that something great happened and a dream computer line for ML was born.
A M1 based MacBook Air cannot beat training performances of a server with a high-end GPU. But even if I use Tesla K80 or V100 based instances for running big training jobs, 95% of my day-to-day work is based on small data size below 2 GB and reasonable training time not exceeding a few minutes.
So, having such powerful ML lab in a 1.29 kg fanless laptop like the MacBook Air sounds like an engineer dream.
Apple Silicon M1
- 8-core CPU (4 high performances at 3.2 GHz, 4 high efficiency at 2.06 GHz)
- 8-core GPU (128 execution units, 24 576 threads, 2.6 TFlops)
- 16-core Neural Engine dedicated to linear algebra
- Unified Memory Architecture 4 266 MT/s (34 128 MB/s data transfer)
As Apple stated, thanks to UMA "all of the technologies in the SoC can access the same data without copying it between multiple pools of memory". In addition, M1 memory speed exceed by far most of the best available computers today. For instance, M1 memory transfer is 60% faster than the most recent iMac 27" released a few months ago equipped with a 2 666 MT/s RAM. And due to the Unified Memory Architecture, it eliminates memory transfers between CPU, GPU and Neural Engine even more increasing the performances gap with Intel architectures.
Running ML Tools on Apple Silicon
For my day-to-day ML research and engineering I need Python 3, pandas, numpy, scikit-learn, matplotlib, tensorflow and jupyterlab as a bare minimum.
Even if it reports surprisingly good performances, I don’t want to use Rosetta 2 for the moment. Instead, I’m only looking for native versions compiled for Apple Silicon even if they are not still using all its power (GPU, Neural Engine).
Two weeks after the launch of Apple Silicon, Anaconda 2020.11 is not yet compatible. The installer asks for Rosetta. On the other hand installing Python 3 is quite easy. Simply open a terminal and call python3. This installs the XCode command line tools including Python 3.8.2 compiled for Apple Silicon. But this is quite useless for the moment as trying to install numpy fails with a compilation error. JupyterLab can be installed but fails to run any notebook, causing kernel issues.
Conda
The solution is to use miniforge an open source conda distribution, from conda-forge , sponsored by numfocus and identical to miniconda but providing the packages compiled for various platform including Apple Silicon osx-arm64.
Scikit-Learn
I first installed pandas, numpy, scikit-learn, matplotlib and jupyterlab from miniforge conda. After a few testing on a dummy random forest classifier running from a Jupyter notebook, everything seems to work perfectly.
XGBoost
At the moment gradient boosting packages like XGBoost, LightGBM and CatBoost cannot be installed. Trying to compile them from a pip installation under conda environment fails.
TensorFlow
Regarding TensorFlow an alpha version for Apple Silicon is available. This is a fork from TensorFlow by Apple that is planned to be merged in the master by Google as stated here.
As it was compiled for Python 3.8 it cannot be installed under the miniforge conda environment. Instead, it needs to use the Python 3.8.2 release installed with XCode command line tools. It creates a dedicated virtual environment that can be used for experiments. When looking at the delivered packages, it includes numpy wheel, so we can guess this version is the one optimized for Apple Silicon as stated by Apple in the list of open-source project they helps the community to port.
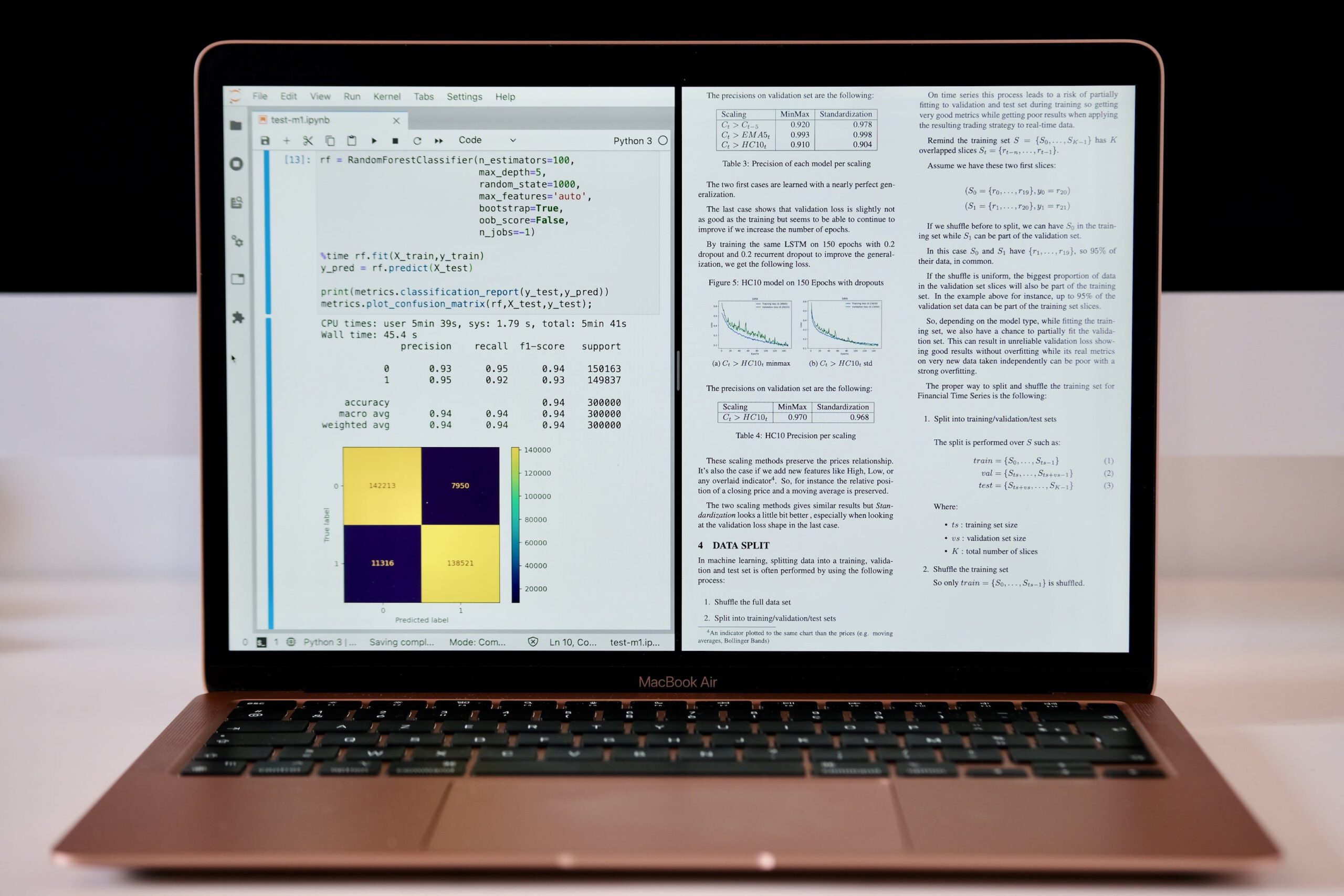
I have first tested MLP, CNN and LSTM models on MNIST. MLP and CNN works perfectly with a decreasing loss as expected, similar to the one observed on the current TensorFlow master release running on my Intel iMac. LSTM has an issue. While reporting a decreasing loss, the test set shows a very low accuracy while such extreme overfit does not appears when training the same network on 4 other configurations (CPU and GPU). I’ve reported the issue to Apple on GitHub.
Update: a workaround exists by setting the evaluation batch size to a value greater or equal to the training batch size. For instance if the training batch size was 128, you must evaluate it with the same size.
model.evaluate(X_test,y_test,verbose=2,batch_size=128)There are also some other bugs, like an exception raised when trying to disable the eager execution mode to avoid a huge slowdown when using the GPU. For now, only the CPU mode works quite well in most of the situations despite a strange underutilization. These issues are also reported to apple on GitHub.
So what about the performances ?
Regarding the miniforge release, it’s unclear today if numpy was optimized or just compiled for Apple Silicon. On the other hand, we can assume that numpy release delivered with TF 2.4 alpha takes benefit from M1 linear algebra computation capacity, at least partially. I will try to make it clearer with some tests in another article.
Regarding TensorFlow, it’s too early for doing any reliable testing today as there is still too many issues, especially on GPU. Even on CPU we observe a strange underutilization with only 4 cores used at 50% or less each.
I will soon publish an article on performances relative to ML on M1.
I can disclose one more thing … it’s already really fast.
Thank you for reading.
Sources







