
Edit: As of the Spotify developer terms version 9 (8th May 2023), you may not use any content from the API to train machine learning models or AI. I leave this article solely for informative purposes.
Introduction
As someone who uses Spotify on the daily I was interested in what analysis I could do with my own music data. Spotify does a great job of recommending tracks via both daily mixes and track radios, but how do we build something like this ourselves? The aim here was to use machine learning and recommender system techniques to recommend new tracks based on tracks in my favourite playlists.
This article gives a higher level overview of this project. The code and results can be found on GitHub here.
Spotify Data
Any good Data Science project first needs data, and lots of it.
Accessing the Spotify API

In order to get started with our music data we first need to access the Spotify API:
- Create a Spotify for Developers account
- From the dashboard setup a project (needed for API access)
- Retrieve the client ID, client secret, and setup the redirect URI (as a local projects I set this to http://localhost:9001/callback)
- Review the API documentation
Music Data
Once the developer account is setup, we can access the API to pull music data. We can use the spotipy Python package for this, which needs the developer details which we setup earlier to grant permissions via OAuth.
with open("spotify/spotify_details.yml", 'r') as stream:
spotify_details = yaml.safe_load(stream)# https://developer.spotify.com/web-api/using-scopes/
scope = "user-library-read user-follow-read user-top-read playlist-read-private" sp = spotipy.Spotify(auth_manager=SpotifyOAuth(
client_id=spotify_details['client_id'],
client_secret=spotify_details['client_secret'],
redirect_uri=spotify_details['redirect_uri'],
scope=scope,)
)We can now pull data from a variety of sources in our Spotify library. The sp class has the functions to cover this such as sp.current_user_playlists() and sp.current_user_top_tracks() . From these API calls we need to pull the track details such as unique id, name, duration and genres, as well as associated artist, album, and playlist properties. I saved these as pandas dataframes for ease of analysis.
Spotify can also provide the audio features for a track. These are numerical values (mostly normalised between 0 and 1) which are useful for analysis but especially as features for traditional Machine Learning methods.

Recommender Systems
Machine Learning
With the above tabular data set it’s fairly straightforwards to formulate this as a classic regression problem by rating songs in the training set from 1–10, or as a classification problem by trying to recommend tracks similar to our favourite songs (a fairly simple approach if you have a playlist of favourite songs). Remember to remove duplicate track ids from the train and test datasets to avoid data leakage!
The XGBoost and RandomForest classifiers performed well for me here.
However, the above approach is heavily reliant on both feature engineering and on users to provide the labelling. It suffers from both mislabelling inaccuracies and the cold-start problem when a user has a fresh account or doesn’t provide any ratings, and recommender system approaches are therefore often used instead.
Popularity Recommender
A popularity recommender recommends songs ranked by their popularity regardless of user’s preferences. This is of course dependent upon the methodology used to determine the popularity metric (usually some function of time, user interactions, and user ratings).

As it doesn’t take user activity into account, solely recommending by popularity is a poor way to recommend tracks. However, as we will see later it is a good method to mix in for variety and to avoid the cold-start problem.
Content-based Recommender
A content-based recommender leverages attributes from items the user has interacted with to recommend similar items. Here the popular TF-IDF method is used to convert unstructured text (unigrams and bigrams of genres and song/artist/album/playlist name) into a sparse matrix. The cosine similarity between the user vector and the initial matrix (all users) then gives a metric to recommend new tracks.
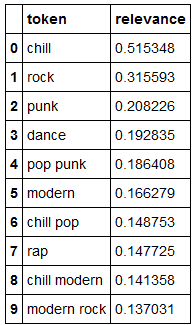
Looks like genre tends to be the strongest form of content to base track recommendations on.
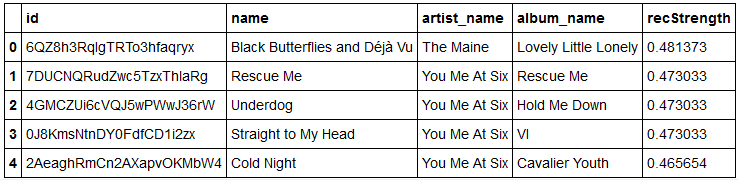
Collaborative Recommender
A collaborative recommender can be either memory-based (based on past user interactions) or model-based (e.g. clustering). Here an items×users matrix is then used to recommend items to users based on the interactions of similar users.

 Notice these are a different genre to the most relevant tokens for the content-based recommender.
Notice these are a different genre to the most relevant tokens for the content-based recommender.The collaborative approach can suffer from the sparsity problem if the user set is too small or the number of interactions is too low.
Hybrid Recommender
A hybrid recommender combines the content-based and collaborative approaches and has been shown to perform better in many studies. It avoids high variance and enables variety and weighting (e.g. genre weighting). We can also incorporate the popularity approach to give a hybrid + popularity recommender.

Subjectively this recommender appears to give the best recommendations in practice!
Final Playlist & Thoughts
We can now add our tracks to a Spotify playlist to listen to! Create the tracks_to_add array of track ids where the recommendation strength is above a certain value.
# Create a new playlist for tracks to add
new_playlist = sp.user_playlist_create(
user=spotify_details['user'],
name="spotify-recommender-playlists",
public=False,
collaborative=False,
description="Created by https://github.com/anthonyli358/spotify- recommender-systems",
)
# Add tracks to the new playlist
for id in tracks_to_add:
sp.user_playlist_add_tracks(user=spotify_details['user'],
playlist_id=new_playlist['id'],
tracks=[id],
)Hopefully the playlist is  . To improve the recommendations even more we could:
. To improve the recommendations even more we could:
- Expand the dataset to include other users
- Develop other evaluation metrics (here the Top-N accuracy metric was used)








