
About this article
This article is part of the supporting material for the story – ‘Understanding NLP – from TF-IDF to transformers‘
This article goes in detail on how to get started with spaCy. We will be focusing on the internals and not just writing some code and executing it. It means – we will be trying to delve a little deeper on what is happening when you execute each code snippet.
Every code snippet is broken down and explained in detail. If you just want to see the code in action, you might want to skip the detailed explanation in between and run the codes directly on your IDE.
Whom is it for ?
If you are just getting started with NLP, it would be advisable to read some articles on the basic concepts of NLP.
Some of the concepts you might want to refresh / understand before going ahead –
- Tokens
- Parts-of-Speech (POS) tagging
- Named Entity Recognition (NER)
- Lemmatization / Stemming
This article is for any one just starting out to experiment with spaCy as your choice of package. We will be using spaCy v3.0 in our examples.
A quick note about spaCy
spaCy is an industrial grade NLP package.
- It’s fast ( written in C, with language bindings for Python )
- It’s production grade
- Supported by an active community
- Has lots of active standalone projects built around it
Installation & setup
Step 1 ) Install Spacy just like any other package
> pip install spaCy
Step 2 ) Download at least one of the pre-trained pipeline models (for English language), from the command prompt
> spacy download en_core_web_sm
This downloads a small language model pipeline for English, trained on a huge sample of text found on the web. It has the weights, vocabularies etc (we don’t have to worry about these terms as yet) for the language we have downloaded. Now we are ready to try some examples.
There are 4 of these pre-trained pipelines you can download –
en_core_web_sm– A small model (13 MB)en_core_web_md– Medium sized pre-trained model(44 MB)en_core_web_lg– A large pre-trained model (742 MB)en_core_web_trf( – Transformer based pre-trained model 438 MB)
The accuracy and efficiency (speed of execution) of your output will depend on which pre-trained model you chose.
# code snippet 1 – Getting started
import spacy
nlp = spacy.load("en_core_web_md")doc = nlp("On October 23, Apple CEO Tim Cook unveiled the new iPad Mini, fourth generation iPad with Retina display, new iMac, and the 13-inch MacBook Pro with Retina display.")What’s happening here ?
- We imported a pre-trained spacy.lang object ( as mentioned earlier, this pre-trained model is based on a sample of English language text from the internet).
- Run through this
nlp()pipeline ( takes a string as parameter and returns aDoc). - Returns a spaCy
Docobject on which we can work on
What’s happening behind the scenes ?
When you wrap a text around nlp() a lot of things happen. Just to know what is happening, call the pipeline attribute and you will see what is happening.
>> nlp.pipelineGives the list of components included in the pipeline in the right order.
[('tok2vec', <spacy.pipeline.tok2vec.Tok2Vec at 0x24c8>),
('tagger', <spacy.pipeline.tagger.Tagger at 0x24c47c8>),
('parser', <spacy.pipeline.dep_parser.DependencyParser at 0x24c9ba8>),
('ner', <spacy.pipeline.ner.EntityRecognizer at 0x24c66508>),
('attribute_ruler',
<spacy.pipeline.attributeruler.AttributeRuler at 0x24c67e08>),
('lemmatizer', <spacy.lang.en.lemmatizer.EnglishLemmatizer at 0x2403a88>)]It means that when you invoke nlp() you are running a series of steps –

- Tokenizer – Converts the text into small segments comprising of words and the punctuations – these segments are called tokens.
- Tagger – This component tags each words as a corresponding parts of speech based on the language model that is used.
- Parser – Component for dependency parsing ( in other words, find the structure and relation between words in a sentence – not that important to understand in the context of this article).
- NER ( Named Entity Recognizer).
- Attribute Ruler – When you assign your own rules ( eg : word/phrase token matching), this component can set attributes to individual tokens.
- Lemmatizer – This component creates lemmas for each of the words/tokens in the doc. (Lemmas are also called the base forms of the word.)
WoW ! – As you see, a lot gets done here. And if you have a very large text, it might take a little while.
At this point we are ready to do some operations on the doc object.
# code snippet 2 – displaying the named entities
#if you want to show the named entities in the text
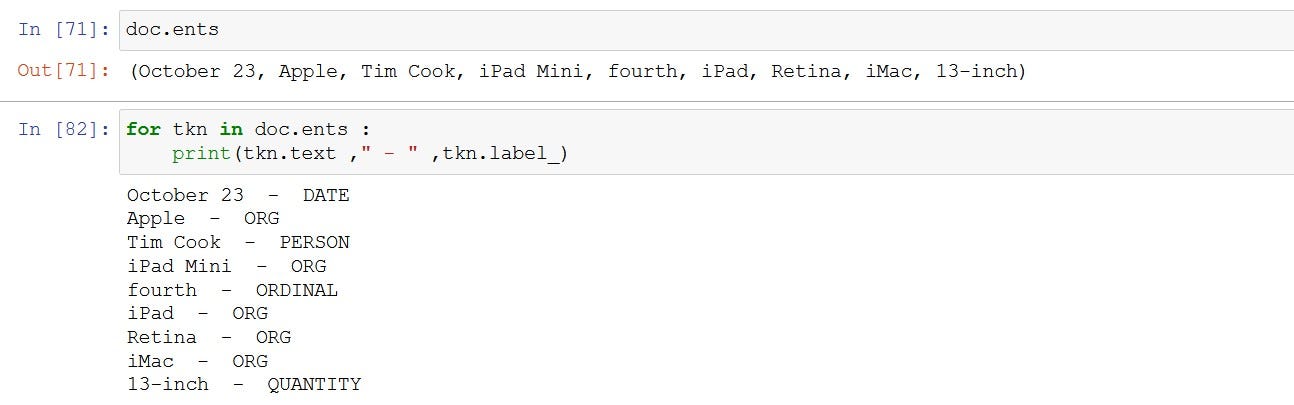
doc.ents
# if you want to display the labels associated with it
for tkn in doc.ents :
print(tkn.text ," - " ,tkn.label_)Output of the above code would look like this –
or if you want a visual display
from spacy import displacy
displacy.render(doc, style='ent')will give you the following output.

code snippet 3— exploring the doc object
1.Sentences – You can get the sentences separated into an iterator object using the sents attribute in the doc object creates an iterator which holds each of the sentences.
#working with sentences txt = "Hello my dear fellow scholars ! This is Tomas from the German republic. Iam very happy to join you. How are you all feeling ?"doc = nlp(txt)for sentences in doc.sents :
print(sentences)# or you can store it as a list
list_sentences = list(doc.sents)the output of the above code looks like this
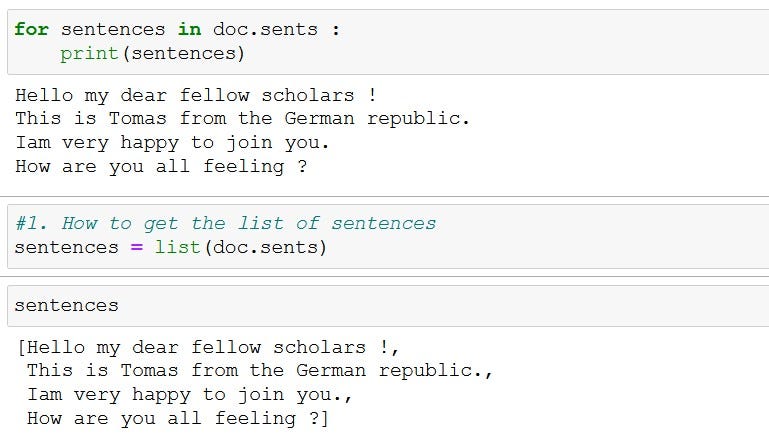
 Note : The sentences extracted from the doc object is a statistical prediction and may not be the most accurate one. It does not do a simple rule based splitting – eg: based on a ‘full stop’ / ‘period’ character )
Note : The sentences extracted from the doc object is a statistical prediction and may not be the most accurate one. It does not do a simple rule based splitting – eg: based on a ‘full stop’ / ‘period’ character )
code snippet 4— Rules & string matching ( Custom search patterns )
spaCy lets you search custom search patterns . Here’s a simple pattern applied to the earlier example .
txt_apl = "On October 23, Apple CEO Tim Cook unveiled the new iPad Mini, fourth generation iPad with Retina display, new iMac, and the 13-inch MacBook Pro with Retina display."doc = nlp(txt_apl)Now, create and add the custom search patterns:
from spacy.matcher import Matcher
mat = Matcher(nlp.vocab,validate = True)#create patterns for matching
patrn_mac = [ {'LOWER': 'ipad'}]
patrn_Appl = [ {'LOWER': {'IN': ['apple', 'appl']}}]mat.add('patrn_mac', [patrn_mac])
mat.add('patrn_Appl', [patrn_Appl])for match_id, start, end in mat(doc):
print(doc[start: end], "found at ",[start,end])output of the above code looks like this –
Apple found at [4, 5]
iPad found at [11, 12]
iPad found at [16, 17]Here’s what’s happening – broken down into steps:
- Import the relevant package ( here
Matcher). - Create a
Matcherobjectmat, by including thespacy.vocab.Vocabobject. - Define your pattern – here we want to search for any string, convert into lower case and check if it matches ‘
ipad‘ and name the pattern aspatrn_mac.Similarly we create another pattern calledpatrn_Appl. - Add these patterns to the
Matcherobject(mat)we created. - Run / check this
Matcherobject to the doc that we cretaed from the text. Themat(doc)method returns a list comprising of the matchID , start and end location of the match in the doc – something like this:
[
(4260053945752191717, 4, 5),
(4964878671255706859, 11, 12),
(4964878671255706859, 16, 17)
]Recap
- When you run
nlp(), it runs a pipeline of components –tok2vec,tagger,parser,ner,attribute_rulerandlemmatizer. doc.entslists the entities that are recognized by the pre-trained model.- You can use
displacyto visually see the NER outputs. doc.sentslists your sentences in the doc.- You can create custom string matching patterns using
Matchermodule.
Closing Notes
This was a brief introduction on getting started with spaCy . This article, however, does not do justice on the capabilities and power of spaCy as an highly extensible NLP package. More article to follow showcasing the power of spaCy as the production-ready choice of NLP package.
If you would like to read some related articles on NLP – here is one –
10 Use-Cases in everyday business operations using NLP








