
Convolutional Neural Networks(CNNs) and other deep learning networks have enabled unprecedented breakthroughs in a variety of computer vision tasks from image classification to object detection, semantic segmentation, image captioning and more recently visual question answering. While these networks enable superior performance, their lack of decomposability into intuitive and understandable components makes them hard to interpret. Consequently, when today’s intelligent systems fail, they fail spectacularly disgracefully without warning or explanation, leaving a user staring at an incoherent output, wondering why.
Interpretability of Deep Learning models matters to build trust and move towards their successful integration in our daily lives. To achieve this goal the model transparency is useful to explain why they predict what they predict.
Broadly speaking, this transparency is useful at three stages of Artificial Intelligence(AI) evolution.
First, when the AI is relatively weaker than the human and not yet reliably ‘deployable’, the goal of transparency and explanations is to identify the failure mode.
Second, when the AI is on par with humans and reliably ‘deployable’, the goal is to establish appropriate trust and confidence in users.
Third, when the AI is significantly stronger than humans, the goal of the explanations is in machine teaching i.e teaching humans how to take better decisions.
In the previous article, we discussed the problem of interpretability in Convolutional Neural Networks and discussed a very popular technique known as Class Activation Map or CAM used to solve the problem to some extent. Though CAM is a good technique to demystify the working of CNN and build customer trust in the applications developed, they suffer from some limitations. One of the drawbacks of CAM is that it requires feature maps to directly precede the softmax layers, so it is applicable to a particular kind of CNN architectures that perform global average pooling over convolutional maps immediately before prediction. (i.e conv feature maps → global average pooling →softmax layer). Such architectures may achieve in inferior accuracies compared to general networks on some tasks or simply be inapplicable to new tasks.
In this post, we discuss a generalization of CAM known as Grad-Cam. Grad-Cam published in 2017, aims to improve the shortcomings of CAM and claims to be compatible with any kind of architecture. The technique does not require any modifications to the existing model architecture and this allows it to apply to any CNN based architecture, including those for image captioning and visual question answering. For fully-convolutional architecture, the Grad-Cam reduces to CAM.
APPROACH:
Several previous works have asserted that deeper representations in a CNN capture the best high-level constructs. Furthermore, CNN’s naturally retrain spatial information which is lost in fully-connected layers, so we can expect the last convolutional layer to have the best tradeoff between high-level semantics and detailed spatial information.
Grad-Cam, unlike CAM, uses the gradient information flowing into the last convolutional layer of the CNN to understand each neuron for a decision of interest. To obtain the class discriminative localization map of width u and height v for any class c, we first compute the gradient of the score for the class c, yc (before the softmax) with respect to feature maps Ak of a convolutional layer. These gradients flowing back are global average-pooled to obtain the neuron importance weights ak for the target class.
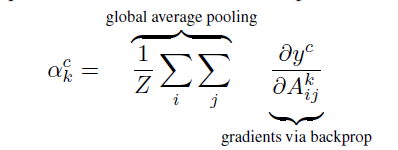
After calculating ak for the target class c, we perform a weighted combination of activation maps and follow it by ReLU.
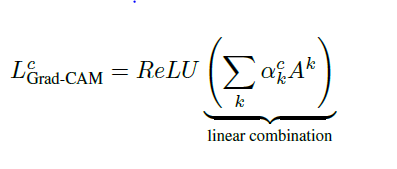
This results in a coarse heatmap of the same size as that of the convolutional feature maps. We apply ReLU to the linear combination because we are only interested in the features that have a positive influence on the class of interest. Without ReLU, the class activation map highlights more than that is required and hence achieve low localization performance.
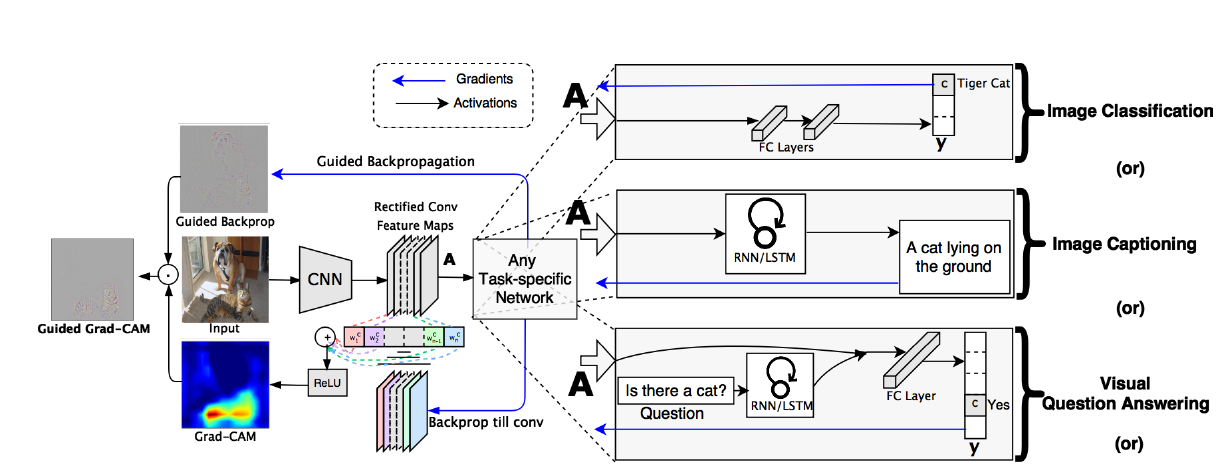
The complete pipeline for each computer vision task is shown in Figure 2 to gain more clarity about this important concept.
Implementation of Grad Cam Using Keras :
The implementation is divided into the following steps:-
-
To begin, we first need a model to run the forward pass. We use VGG16 pre-trained on Imagenet. You can use any model because GradCam unlike CAM doesn’t require a specific architecture and is compatible with any Convolutional Neural Network.
-
After we define the model, we load a sample image and preprocess it so that it is compatible with the model.

Input Image -
Then we use the model to make predictions on the sample image and decode the top three predictions. As you can see in the images below that we are just considering the top three predictions from the model, the top model prediction being boxer.
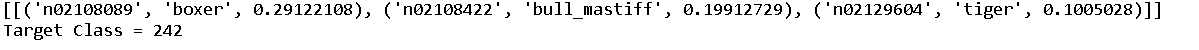
Decoded predictions and Target Class -
In the next step, we find the gradients of the target class score yc with respect to the feature maps Ak of the last convolutional layer. Intuitively it tells us how important each channel is with regard to the target class. The variable grads return a tensor which will be used in the following steps.
-
The gradients thus obtained are then global average pooled to obtain the neuron important weights ak corresponding to the target class as shown in Figure 1. This returns a tensor that is passed to the Keras function that takes the image as input and returns the pooled_grads along with activation maps from the last convolution layer.
-
After that, we multiply each activation map with corresponding pooled gradients which acts as weights determining how important each channel is with regard to the target class. We then take the mean of all the activation maps along the channels and the result obtained is the final class discriminative saliency map.

Class Discriminative Map -
Then we apply ReLU on the resulting heatmap in order to only keep the features that have a positive influence on the output map. But we see that we don’t have many negative intensities in the heatmap and hence there isn’t much change in the heatmap after applying ReLU.
Class Discriminative Map after ReLU -
We then divide each intensity value of the heatmap with the maximum intensity value in order to normalize the heatmap such that all values fall between 0 and 1.
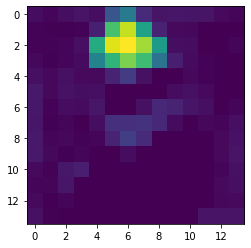
Class Discriminative Saliency Map after Normalization -
Finally, we upsample the resulting heatmap to match the dimensions of the input image and overlay it on the input image in order to see the results.

Final Saliency Map with Bull Dog as Target Class
Conclusion:
In this article, we learned a new technique for interpreting the Convolutional Neural Networks which are a state of art architecture, especially for image-related tasks. Grad Cam improves on its predecessor CAM and provides better localization and clear class discriminative saliency maps which guide us demystifying the complexity behind the black-box like models. The research in the field of interpretable Machine Learning is advancing at a faster pace and is proving to be very crucial in order to build customer trust and helps to improve the models.
In the upcoming articles, I will explore more recent research in this field related to Convolutional Neural Networks and will demystify the complex concepts with the help of intuitive visualizations and easy implementation. If you liked the article motivate me by leaving a clap and if you have any suggestions, comments feel free to connect with me on Linkedin or follow me on twitter.







