Launched in November 2020, Apple M1 was a revolution in the world of computers dominated by Intel. These new M1 Macs showed impressive performance in many benchmarks as M1 was faster than most high-end desktop computers for only a fraction of their energy consumption.
Here are my previous benchmarks for the M1:
Benchmark M1 vs Xeon® vs Core i5 vs K80 and T4
M1 competes with 20 cores Xeon® on TensorFlow training
In January 2023, Apple announced the new M2 Pro and M2 Max. Their specs let us expect good performance increases, especially regarding the GPU.
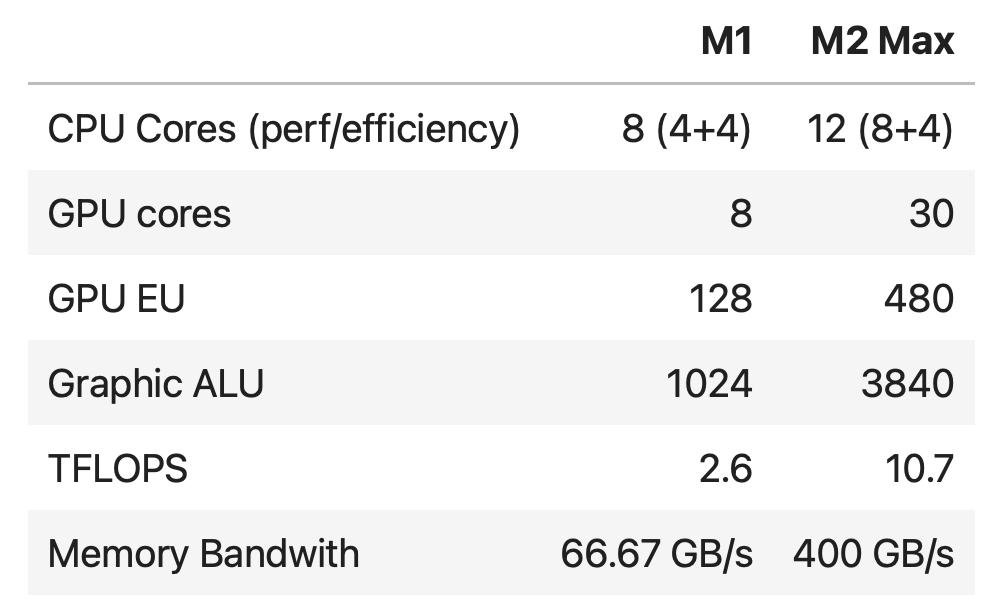
This M2 Max has 30 Gpu cores, so we estimated the 10.7 TFLOPS from the 13.6 TFLOPS of the 38 GPU cores version.
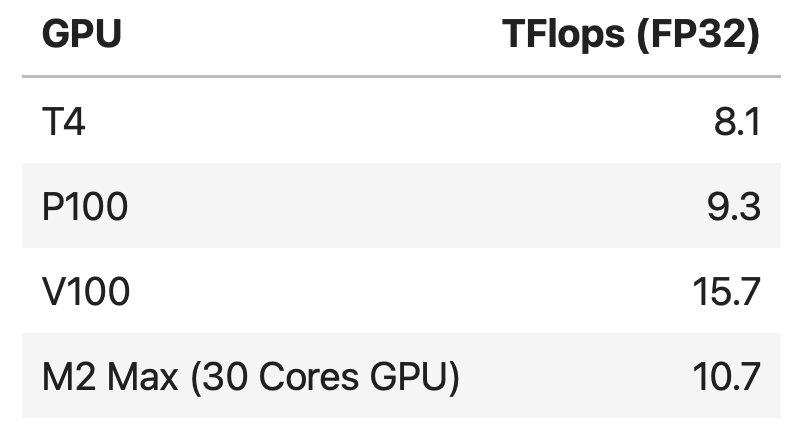
By comparison, the M2 Max 38 Cores GPU reaches 13.6 TFlops. My test below will show that the TFlops alone cannot be used to estimate the actual performances of these GPUs.
To get comparable results, I run every test with the default TensorFlow FP32 floating point precision.
You can verify this precision by running :
tf.keras.backend.floatx()
'float32'Setup
In this article, I benchmark the M2 Max GPU against Nvidia V100, P100, and T4 for MLP, CNN, and LSTM TensorFlow models.
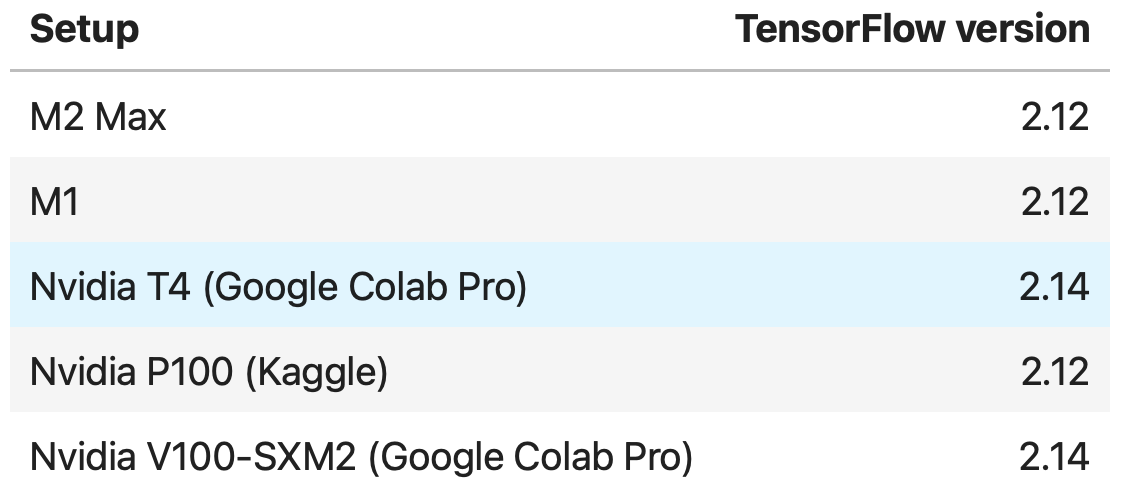
On M1 and M2 Max computers, the environment was created under miniforge. Only the following packages were installed:
conda install python=3.10
pip install tensorflow-macos==2.12
pip install tensorflow-metal==0.8.0
conda install pandasUnlike in my previous articles, TensorFlow is now directly working with Apple Silicon, no matter if you install it from pip, anaconda, or miniforge.
To enable GPU usage, install the tensorflow-metal package distributed by Apple using TensorFlow PluggableDevices. Note that Metal acceleration is also available for PyTorch and JAX.
Apple says
With updates to Metal backend support, you can train a wider set of networks faster with new features like custom kernels and mixed-precision training.
Models
This benchmark consists of a Python program running a sequence of MLP, CNN, and LSTM models training on Fashion MNIST¹ for batch sizes of 32, 128, 512, and 1024 samples.
It also uses a validation set to be consistent with the way most model training is performed in real-life applications. Then, a test set is used to evaluate the model after the training to make sure everything works well. So, the training, validation, and test set sizes are respectively 50000, 10000, and 10000.
I use the same test program as described in this previous article. As a reminder, the three models are simple and summarized below.
MLP
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=X_train.shape[1:]),
tf.keras.layers.Dense(512,activation='relu'),
tf.keras.layers.Dropout(rate=0.2),
tf.keras.layers.Dense(64,activation='relu'),
tf.keras.layers.Dense(10,activation='softmax')
])CNN
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32,(3,3),activation = 'relu',input_shape=X_train.shape[1:]),
tf.keras.layers.MaxPooling2D((2,2)),
tf.keras.layers.Conv2D(64,(3,3),activation = 'relu'),
tf.keras.layers.MaxPooling2D((2,2)),
tf.keras.layers.Conv2D(64,(3,3),activation = 'relu'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64,activation='relu'),
tf.keras.layers.Dense(10,activation='softmax')
])LSTM
model = tf.keras.models.Sequential([
tf.keras.layers.LSTM(128,input_shape=X_train.shape[1:]),
tf.keras.layers.Dense(10,activation='softmax')
])They are all using the following optimizer and loss function.
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])Note that, unlike in the previous benchmark articles, the eager mode is now working for GPU.
Results
Let’s first compare M2 Max with M1.
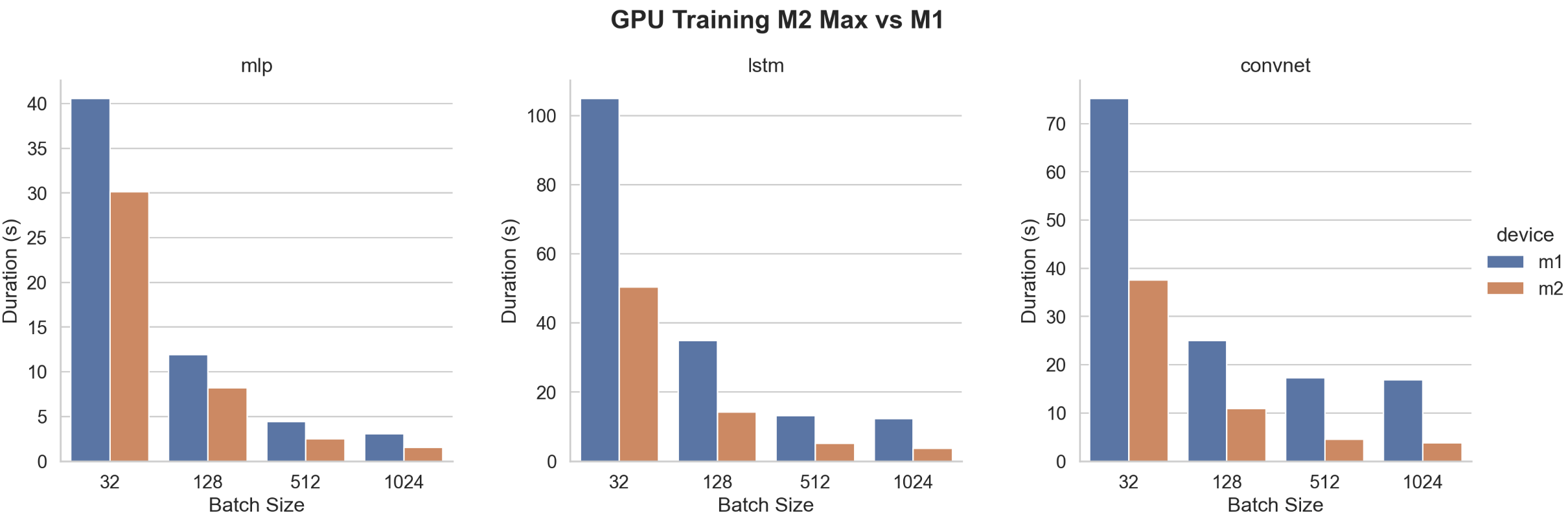
As expected, the M2 Max is always faster than the M1. The following shows how many times.
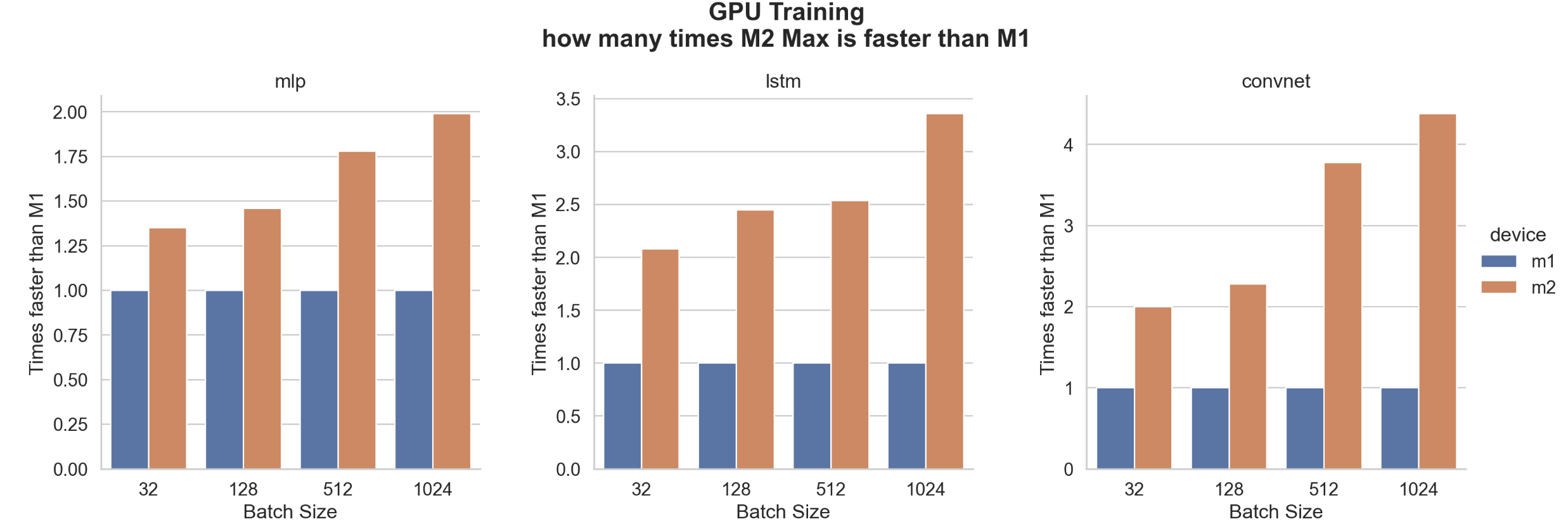
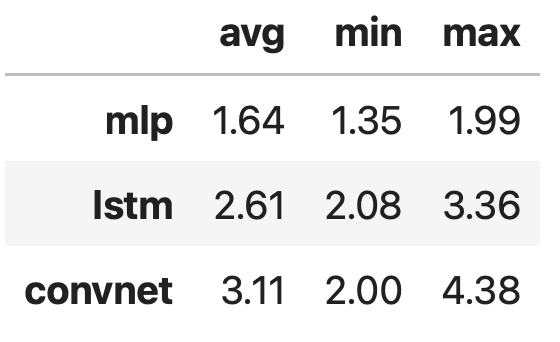
Here are the average, minimum, and maximum increases in speed. We found that Convnet training with M2 Max can be up to 4.38 times faster than with M1 GPU.
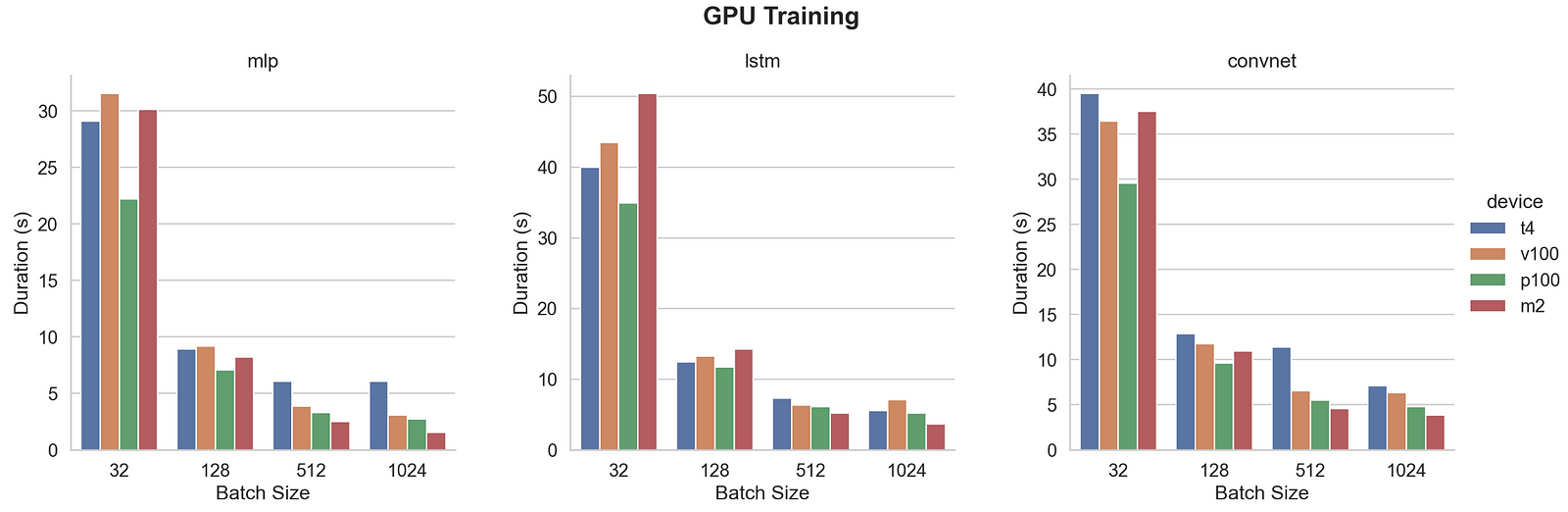
Now let’s compare M2 Max with the other Nvidia High-End GPUs found on Google Cloud, AWS, Google Colaboratory, or Kaggle platforms.
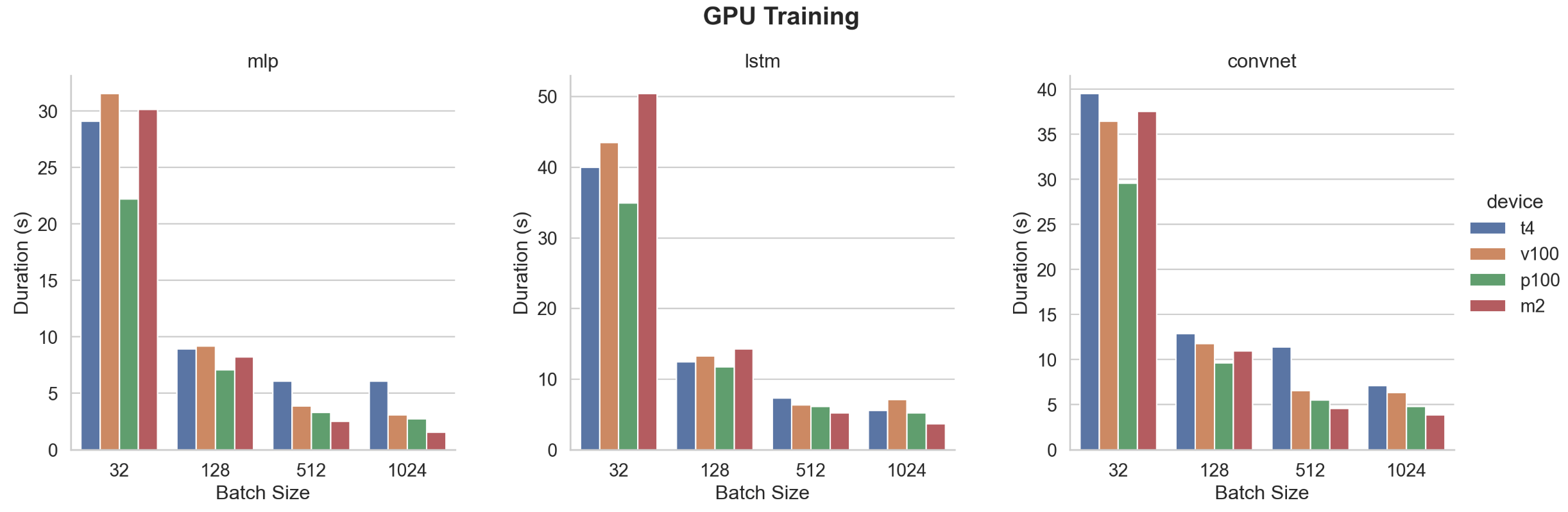
While training performances look quite similar for batch sizes 32 and 128, M2 Max is showing the best performances over all the GPUs for batch sizes 512 and 1024.
The P100 is the fastest of the other GPUs while when looking at the specifications V100 was expected. This can be due to the instance itself as the characteristics of the three different versions of each card cannot explain it. When checking the details, Kaggle P100 instance has 4 vCPU while Colab V100 proposes 2 vCPU only. Maybe this can impact global performances and should be checked further.
Here we compare how many times M2 Max is faster than Nvidia P100.
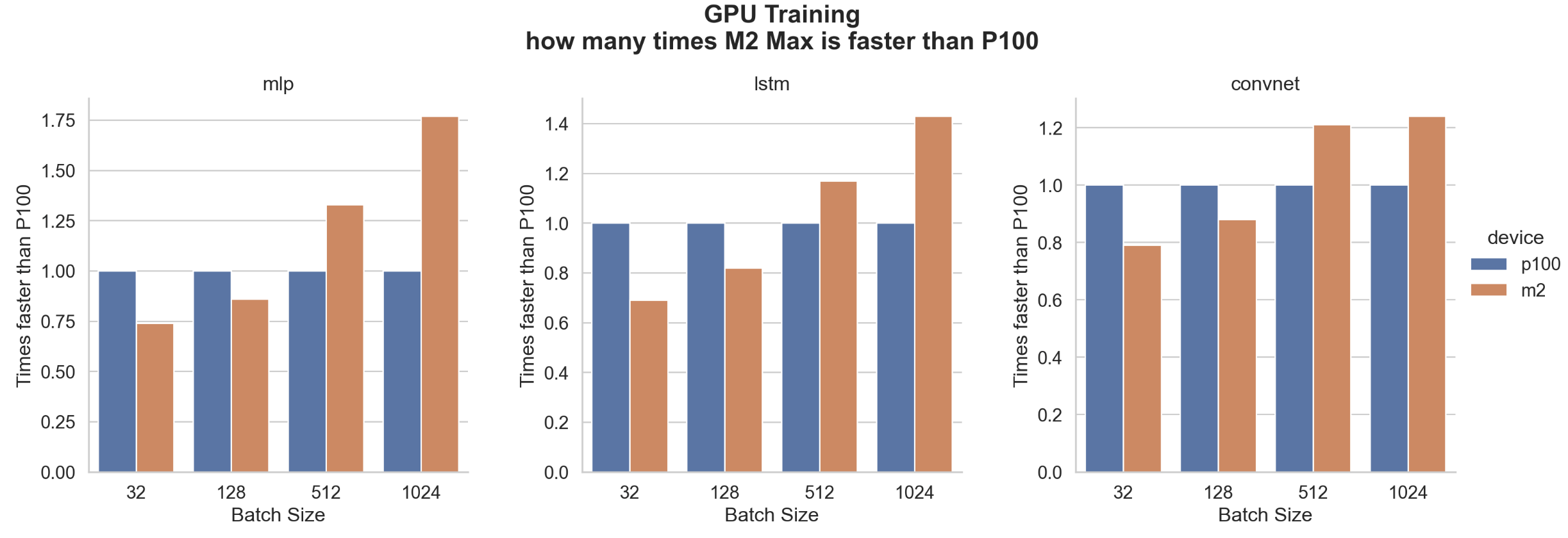
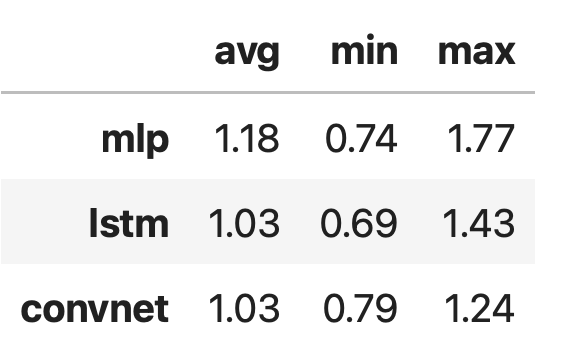
Here are the average, minimum, and maximum increases in speed. We found that on average the M2 Max is identical to a P100 and that while it’s slower for a batch size of 32 and 128 it can be faster up to 1.77 times for MLP, 1.43 times for LSTM or 1.24 times for CNN with a batch size of 1024.
Benefit of GPU vs CPU on M2 Max
In the past, with the previous version of TensorFlow, it was often observed that MLP and LSTM were more efficiently trained on the CPU than GPU. Only CNN benefits from GPU. But now, with the recent version of TensorFlow things have changed for LSTM.
So a last interesting test is to check when models training benefit from the GPU compared to the CPU.
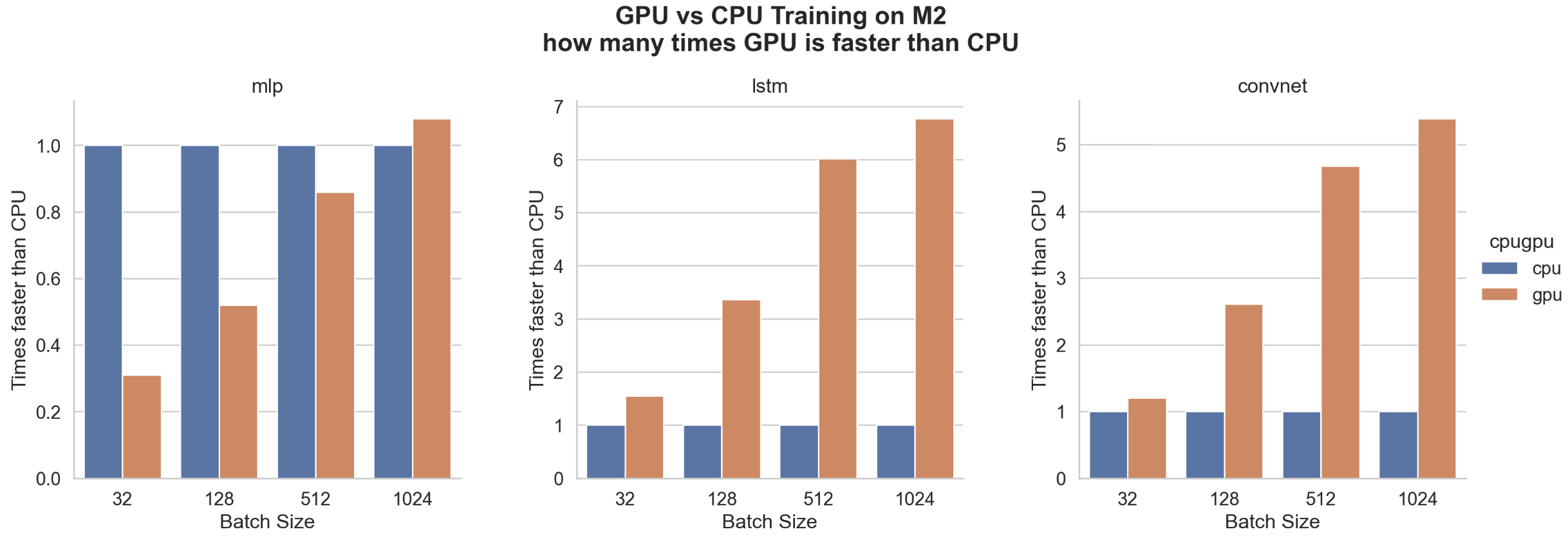
MLP does not benefit from GPU acceleration. As expected CNN benefits for every case but from a batch size of 128 the difference is huge and goes up to about 5 times faster.
But the really good surprise comes from LSTM which shows by far the biggest benefit from training on GPU which is up to 6.77 times faster for a batch size of 1024
Conclusion
From these tests, it appears that
- M2 Max is by far faster than M1, so Mac users can benefit from such an upgrade
- Compared to T4, P100, and V100 M2 Max is always faster for a batch size of 512 and 1024
- Performance differences are not only a TFlops concern. M2 Max is theoretically 15% faster than P100 but in the true test for a batch size of 1024 it shows performances higher by 24% for CNN, 43% for LSTM, and 77% for MLP
Of course, these metrics can only be considered for similar neural network types and depths as used in this test.
A new test is needed with bigger models and datasets.
Now TensorFlow is easy to install and run efficiently on Apple Silicon. The GPU can now be used for any model and increase a lot the training performances for any type of model. That’s especially true for LSTM.
We can conclude that M2 Max is a very good platform for Machine Learning engineers. It enables training models on GPU with very good performances, even better than a T4, P100, or V100 commonly found on cloud instances. It also includes 12 CPU cores, making it more flexible than these GPU instances, and all of this for only a fraction of their energy consumption.
Update (12/11/2023): The last versions of tensorflow-metal (> 0.8.0) has a bug making some models unable to converge. To avoid this issue, I’ve updated the installation instructions in the article by setting the TensorFlow and tensorflow-metal versions. Then, I replayed the test with this new package combination to ensure the benchmark was unchanged. I confirm that it does not change anything to the performance results.
Sources
Images and Code : All images and codes in this work are by the author unless explicitly stated otherwise.
Datasets Licences : Fashion-MNIST is licenced under the MIT Licence
[1] Han Xiao and Kashif Rasul and Roland Vollgraf, Fashion-MNIST: a Novel Image Dataset for Benchmarking Machine Learning Algorithms (2017)








