
In data science, datasets with positive and unlabeled data, known as positive-unlabeled (PU) datasets, present a common yet challenging problem. PU datasets are characterised by the presence of unlabeled data, where the positive instances are not explicitly identified as positive. PU datasets are often encountered in business scenarios where only a small proportion of data is labelled. The remaining unlabelled samples could belong to either the positive or negative class. Such scenarios include fraud detection, product recommendation, cross-selling, or customer retention. The goal is to accurately classify the unlabelled data as positive or negative, leveraging the available labelled data.

Naive approach
When dealing with this task, the first approach to binary Classification that comes to mind is the naive one. It involves treating the unlabelled data as samples of the negative class. However, this approach has a limited performance when dealing with imbalanced datasets, i.e. datasets with a large number of unknown positive samples. Furthermore, it relies on the assumption that the proportion of positive samples in the unlabelled data is small enough to not significantly impact the model’s performance. Despite being simple to implement, the naive approach may not be suitable for all scenarios and often results in suboptimal performance in practice.
Elkan and Noto’s approach
A much more sophisticated method for positive-unlabelled classification is Elkan and Noto’s (E&N) approach. Within this method, we usually train a classifier to predict the probability that a sample is labelled and further use the model to estimate the probability that a positive sample is labelled. Then the probability that an unlabeled sample is labelled is divided by the probability that a positive sample is labelled to get the actual probability that the sample is positive. You can find a perfect explanation of how it works here.
While the E&N approach is effective in practice, it requires a significant amount of labelled data to accurately estimate the likelihood of a sample being positive, which may be impractical in real-world scenarios where marked data is scarce.
Custom self-training approach
However, our team has developed a custom ImPULSE (stands for Imbalanced Positive-Unlabelled Learning with Self-Enrichment) solution that addresses this issue and has shown improved performance compared to the E&N approach on both balanced and imbalanced datasets, even with a high proportion of unknown positive labels.
ImPULSE Classifier is a modification of any (potentially) supervised classification method that can work in a semi-supervised manner. We use LightGBM (as a base estimator) and a modified workflow that incorporates all predicted probabilities as weights for each sample in the training set. This allows us to not only add new pseudo-labels for the next iteration of the model’s training but also make it pay attention to the most promising (valid) negative samples, allowing the model to be retrained on a larger and more diverse set of data more confidently. Additionally, we provide adjusted class weights at each iteration to deal with imbalanced data.
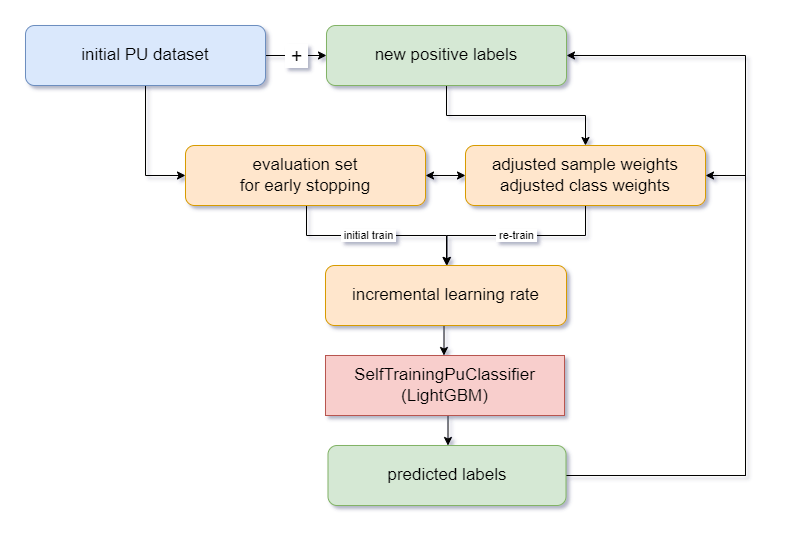
Our approach generally involves training a classifier on available data and using it to make predictions on unlabelled data (in a self-training manner). We start by splitting the data into a training set and a hold-out evaluation set. Then, we train the model while monitoring its performance on the evaluation set to prevent overfitting.
Next, we use the trained model to predict the labels of the unlabelled data and select the samples with high-confidence predictions as positive examples. We use these positive examples to update the labelled data and retrain the model iteratively. To prevent overfitting, we have implemented custom early stopping based on metrics for average precision.
To speed up convergence, we increase the learning rate at each iteration, allowing the model to learn more quickly from the updated set of labelled data and make better predictions on the unlabelled data. This iterative process continues until a stopping criterion is met. Overall, our approach focuses on updating the labelled data with informative positive examples and effectively preventing overfitting to improve the model’s performance.
Experimental runs
Further, we would like to explain how we evaluated the performance of all three mentioned approaches for classifying positive-Unlabeled Data. To achieve this, we developed an experiment pipeline that utilised the LightGBM classifier, a standalone naive estimator, the Python implementation of the E&N Noto method, and our custom self-training algorithm.
To create a controlled environment, we generated a synthetic dataset using Scikit-learn’s _makeclassification function, which we then split into training and testing sets. We defined the number of iterations we wanted to perform, corresponding to the proportion of positive labels to be hidden, and then iteratively modify the training set by removing the corresponding labels at each iteration.
At each iteration, we fit all the models on the (modified) training data and get predictions on the testing set. We calculated the F1-score, a metric that combines precision and recall, using the predicted and test labels. By doing so, we were able to more rigorously evaluate the performance of each approach and compare them under different conditions.
Here is the result of all experimental runs:
You can find the corresponding demo notebook on Jovian and the full code in the GitHub repo.
Conclusion
Thus, we have developed a custom solution for positive-unlabeled classification that has shown improved performance compared to the E&N approach on both balanced and imbalanced datasets. Our approach involves training a classifier on available data and using it to make predictions on unlabelled data in a self-training manner. This solution is utilised as a core classification algorithm in a bunch of our applied analytical tools for cross-selling and customer churn. Despite not being as robust and well-generalised (yet) as the known Python implementation of the E&N approach, our method may be considered a practical choice for the classification of PU data in real business scenarios.
Reference Reading
- Bekker Jessa, and Davis Jesse. "Learning from Positive and Unlabeled Data: a Survey.", 2018
- Kiyomaru Hirokazu, a collection of notebooks with algorithms introduced in "Learning from Positive and Unlabeled Data: a Survey.", 2020
- Dobilas Saul. "Self-Training Classifier: How to Make Any Algorithm Behave Like a Semi-Supervised One.", 2021
- Dorigatti, Emilio, et al. "Robust and Efficient Imbalanced Positive-Unlabeled Learning with Self-Supervision.", 2022
- JointEntropy. "Awesome ML Positive Unlabeled Learning.", 2022
- Agmon Alon. "Semi-Supervised Classification of Unlabeled Data (PU Learning).", 2022
- Holomb, Volodymyr. "A Practical Approach to Evaluating Positive-Unlabeled (PU) Classifiers in Business Analytics.", 2023








