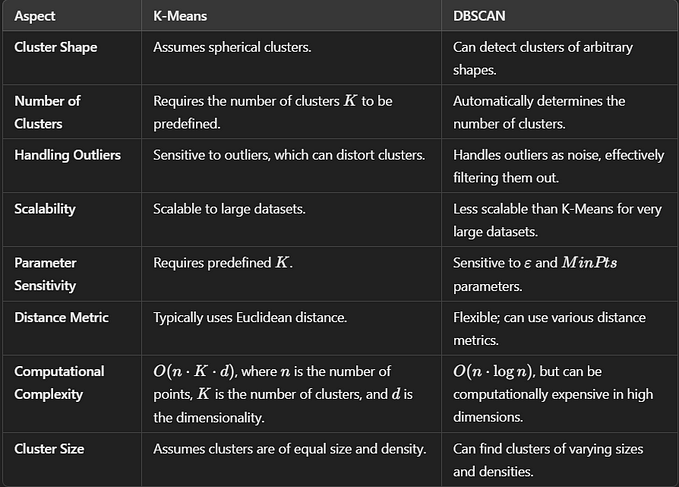
Unsupervised Machine Learning: Clustering Analysis
Published in
12 min readMar 6, 2019

Introduction to Unsupervised Learning
Up to know, we have only explored supervised Machine Learning algorithms and techniques to develop models where the data had labels previously known. In other words, our data had some target variables with specific values that we used to train our models.
However, when dealing with real-world problems, most of the time, data will not come with predefined labels, so we will want to develop machine learning models that can classify correctly this data, by finding by themselves some commonality in the features, that will be used to predict the classes on new data.
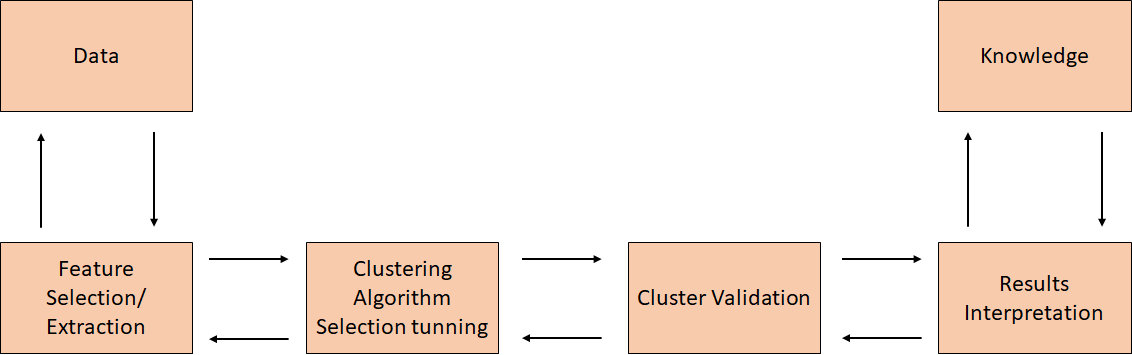
Unsupervised Learning Analysis Process
The overall process that we will follow when developing an unsupervised learning model can be summarized in the following chart:
Unsupervised learning main applications are:
- Segmenting datasets by some shared atributes.
- Detecting anomalies that do not fit to any group.
- Simplify datasets by aggregating variables with similar atributes.