Understanding and Implementing Distributed Prioritized Experience Replay (Horgan et al., 2018)
Accelerating Deep Reinforcement Learning with Distributed Architectures
In the current state-of-the-art, many reinforcement learning algorithms make use of aggressive parallelization and distribution. In this paper, we will review and implement the ApeX framework (Horgan et al., 2018), also referred to as distributed prioritized experience replay. In particular, we will implement the ApeX DQN algorithm.
In this post, I try to accomplish the following:
- Discuss the motivation for distributed reinforcement learning, and introduce the predecessor to distributed frameworks (Gorila). Then, introduce the ApeX framework.
- Provide a brief review of prioritized experience replay, and refer the reader to the paper and other blog posts for an in-depth discussion of it.
- Provide a brief introduction to Ray, a cutting edge parallel/distributed computing library that I will use for implementing ApeX.
- Run through my (simplified) implementation of ApeX DQN.
Where did Distributed RL Start, and Why?
The first work in generalizing the formulation of distributed reinforcement learning architectures was Gorila (General Reinforcement Learning framework; I’ve also seen “Google Reinforcement Learning framework” somewhere, but the paper writes “General”) presented in Nair et al. (2015) at Google.

In Gorila we have a decoupled actor (data generation/collection) and learner (parameter optimization) processes. Then, we have a parameter server and a centralized replay buffer that are shared with every learner and actor processes. The actors carry out trajectory roll-outs and send it to the centralized replay buffer, from which the learner samples experiences and updates its parameters. After the learner updates its parameters, it sends its new neural network weights to the parameter server, which the actor syncs its own neural network weights. All these processes happen asynchronously, independent of each other.
The Gorila framework seems to be the underlying structure for modern distributed reinforcement learning architectures — such as ApeX. In particular, ApeX modifies the above structure by using a prioritized replay buffer (prioritized experience replay, proposed by Schaul et al. (2015); we will have a brief discussion about this in the section below).
The motivation for this kind of architecture comes from the fact that the majority of the computational time in RL is spent generating data, and not updating neural networks. Thus, we can perform more updates if we make these processes asynchronous with each other.
In addition to the speed-up from the asynchronous structure, this distributed architecture has the conceptual advantage of improved exploration; we can run each actor process on distinctly-seeded environments to allow the collection of a diverse data set. For instance, A3C (Mnih et al. 2016) credits its significant improvement over the synchronous version A2C to improved exploration. As such, distributed implementations of algorithms also benefit from this effect.
Brief Review of Prioritized Experience Replay
In reinforcement learning, not all experience data are equal: Intuitively, there are experiences that can contribute more to the agent’s learning than other experiences. Schaul et al. (2015) suggested that we prioritized the experience by its temporal difference (TD) error:

Recall the canonical q-learning algorithm; we are trying to minimize the distance between our current prediction of the Q value, and our bootstrapped target Q value (i.e. the temporal difference error). That is, the higher this error, the greater the degree of update there is to the neural network weights. As such, we can obtain faster learning by sampling experiences with higher TD error.
However, sampling purely based on TD error introduces bias to the learning. For instance, experiences with low TD error might not be replayed for a long time, curtailing the limiting of replayed memories and making the model prone to over-fitting. To remedy this, Schaul et al. (2015) using importance sampling weights for bias correction. That is, for every update step, we multiply the gradient by the importance sampling weights of the experiences, computed as:
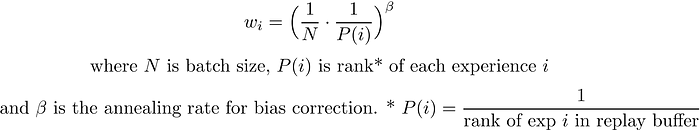
When implementing the prioritized replay buffer, we want to have two separate data structures to store the experience data and its respective priority values. To make the sampling more efficient, Schaul et al. (2015) suggest using segment trees (or sum trees) to store the priority values. We’ll use the OpenAI Baselines implementation for out ApeX implementation, but check out this blog post and the actual paper for a more detailed discussion about prioritized experience replay.
Extremely Brief Introduction to Ray
Below is an extremely brief introduction to using Ray:
This should suffice for following through the code. I recommend checking out their tutorial and documentation, especially If you would like to implement your own parallel/distributed programs with Ray.
Implementation
We will use Ray for multiprocessing, instead of the built-in python-multiprocessing module — from my personal experience, I had a lot of trouble debugging multiprocessing Queues, and had an easier time implementing ApeX with Ray.
Though the implementations run and work, I’m currently working to fix possible bottlenecks and memory leakages. To that end, my implementations are still work-in-progress — I recommend not to heavily parallelize tasks with them yet. I will update this post once the memory usage issues are fixed.
We will break down the implementation process as such: we will group actor and replay buffer together, and then the learner and parameter server. The jupyter notebook files below are simplified versions of my full implementations, just to show how ApeX can be implemented; if you are interested in the full implementation details and would like to run it on your device, take a look at my GitHub repository!
Actor & Replay Buffer
After every roll-out, the actors asynchronously send their transition data to the centralized replay buffer. The centralized buffer assigns priorities to the experiences (as outlined in prioritized experience replay), and sends batches of sampled experiences to the learner.
We will implement the actor process below and use the OpenAI Baselines implementation of prioritized replay buffer. We will have to modify the baseline implementation of the replay buffer to make it compatible with Ray:
Actor
We can make the actor process more memory efficient by having the actors keep a local buffer, and send everything to the centralized buffer periodically — I will update the code shortly.
Prioritized Replay Buffer
Learner & Parameter Server
With the experiences batches sent from the central replay buffer, the learner updates its parameters. Since we’re using prioritized experience replay, the learner also has to update the priority values of the used experiences and send that information to the buffer.
Once the learner parameters are updates, it sends its neural network weights to the parameter server. A neat thing about Ray is that it supports zero-cost reading of numpy arrays; that is, we want the learner to send numpy arrays of its network weights, instead of PyTorch objects. Then, the actors periodically pull and sync their q-networks with the stored parameter.
We will start with the parameter server, and implement the learner process:
Parameter server:
learner:
Full Implementation
To find a running implementation of ApeX DQN and ApeX DDPG, check out my GitHub repository in the link below:

