Since about 2 years, Reinforcement Learning has become a hobby for me. I especially enjoy training agents on games. A huge problem for me during these years, was the lack of a reliable reinforcement learning library for python and I had to either program the state of the art algorithms by myself or find a good source on github. For me that has changed the day I found the stable-baselines3 library.
What you can expect
I will walk you through the whole installation process of stable-baselines3 and the openai gym. Then I will show you, how you can train an agent in the cartpole environment and display some runs of the trained agent on the screen. Also I want you to know about saving and loading models. Stable-baselines3 also enables training on multiple environments at the same time. At the end I will show you how to train a proximal policy optimization (PPO) agent on the more complex LunarLander-v2 environment and a A2C agent on the atari breakout environment.
Installation
The stable-baselines3 library provides the most important reinforcement learning algorithms. It can be installed using the python package manager "pip".
pip install stable-baselines3I will demonstrate these algorithms using the openai gym environment. Install it to follow along.
pip install gymTesting algorithms with cartpole environment
Training a PPO agent
The stable-baslines library contains many different reinforcement learning algorithms. In the following Code, I will show, how you can train an agent that can beat the openai cartpole environment using the proximal policy optimization algorithm.
| from stable_baselines3 import PPO | |
| import gym | |
| # Parallel environments | |
| env = gym.make("CartPole-v1") | |
| model = PPO(policy = "MlpPolicy",env = env, verbose=1) | |
| model.learn(total_timesteps=25000) | |
| obs = env.reset() | |
| for i in range(1000): | |
| action, _state = model.predict(obs, deterministic=True) | |
| obs, reward, done, info = env.step(action) | |
| env.render() | |
| if done: | |
| obs = env.reset() |
 by
by You can easily exchange the algorithm I used by any other reinforcement learning algorithm offered by the stable-baselines3 library. You just need to change lines 1 and 7 and replace PPO with the algorithm of your choice.

Setting the policy to "MlpPolicy" means, that we are giving a state vector as input to our model. There are only 2 other policy options here. Use "CnnPolicy" if you provide images as input. And there is "MultiInputPolicy" for handling mutiple inputs. Since the cartpole environment cannot output images, I will show a usecase of "CnnPolicy" later on with other gym environments.
Saving and loading models
To save the model, use the following line of code.

You can load the saved model back into python

The following code shows the whole process of training, saving and loading a PPO model for the cartpole environment. Make sure, that you save your model only after training it.
| from stable_baselines3 import PPO | |
| import gym | |
| env = gym.make("CartPole-v1") | |
| model = PPO(policy = "MlpPolicy",env = env, verbose=1) | |
| model.learn(total_timesteps=25000) | |
| model.save("ppo_cartpole") # saving the model to ppo_cartpole.zip | |
| model = PPO.load("ppo_cartpole") # loading the model from ppo_cartpole.zip | |
| obs = env.reset() | |
| for i in range(1000): | |
| action, _state = model.predict(obs, deterministic=True) | |
| obs, reward, done, info = env.step(action) | |
| env.render() | |
| if done: | |
| obs = env.reset() |
Parallel Training on multiple environments
You can also very easily train an agent on mutiple environments at the same time (even when training on a cpu). This speeds up the training process of the agent.
We can create parallel environments using the make_vec_env function of the stablebaselines3 library.

We use it in the same way, we used the openai gym function to create a new environment. But we tell the function how many parallel environments we want to create.

Since you train a single agent, you can save the model in the same manner as before.
But one important difference to the previous case is the handling of the terminal state when we test our trained agent. If the epsiode ends in one of the environments, it is automatically reset. Before testing the agent looked like this:

Now, it get shorter:

The following code trains a PPO agent on 4 environments at the same time:
| from stable_baselines3 import PPO | |
| from stable_baselines3.common.env_util import make_vec_env | |
| # Parallel environments | |
| env = make_vec_env("CartPole-v1", n_envs=4) | |
| model = PPO("MlpPolicy", env, verbose=1) | |
| model.learn(total_timesteps=25000) | |
| model.save("ppo_cartpole") | |
| obs = env.reset() | |
| for i in range(1000): | |
| action, _state = model.predict(obs, deterministic=True) | |
| obs, reward, done, info = env.step(action) | |
| env.render() |
Using other gym environments
In order to run most of the other gym environments, you have to install the Box2D library for python. This is pretty easy on mac and linux, but painstaking on windows.
Installing Box2D
Box2D is an open-source physics engine for 2D physics and many gym environments use it for handling collisions of objects.
Linux/OSX
To the extend of my knowledge, there are no problems with directly installing Box2D on linux and mac PCs.
pip install box2d-pyWindows
On windows there are often problems with the installation process of the Box2D environment. However we can install it separately using swig.This resolves the issue. It is pretty simple to install swig using anaconda
conda install swigIf you don’t use anaconda, you can download swig here.
Microsoft Visual C++ 14.0 or greater is also required. If you don’t have it installed, the Box2d installation will fail. So head here and download the newest microsoft C++ build tools.
Here you can install the Buildtools.
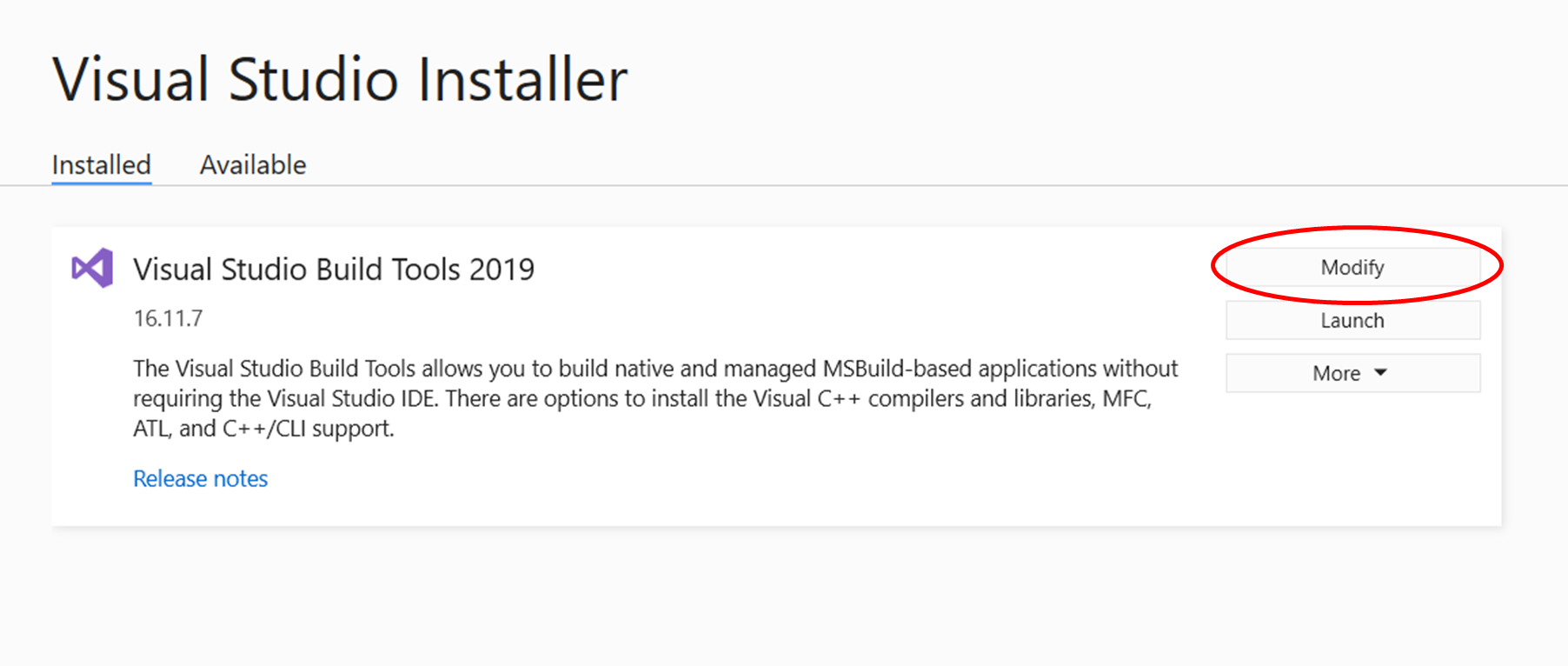
When you have installed the "buildtools", open the visual studio installer (it is probably already open after installing the "buildtools").
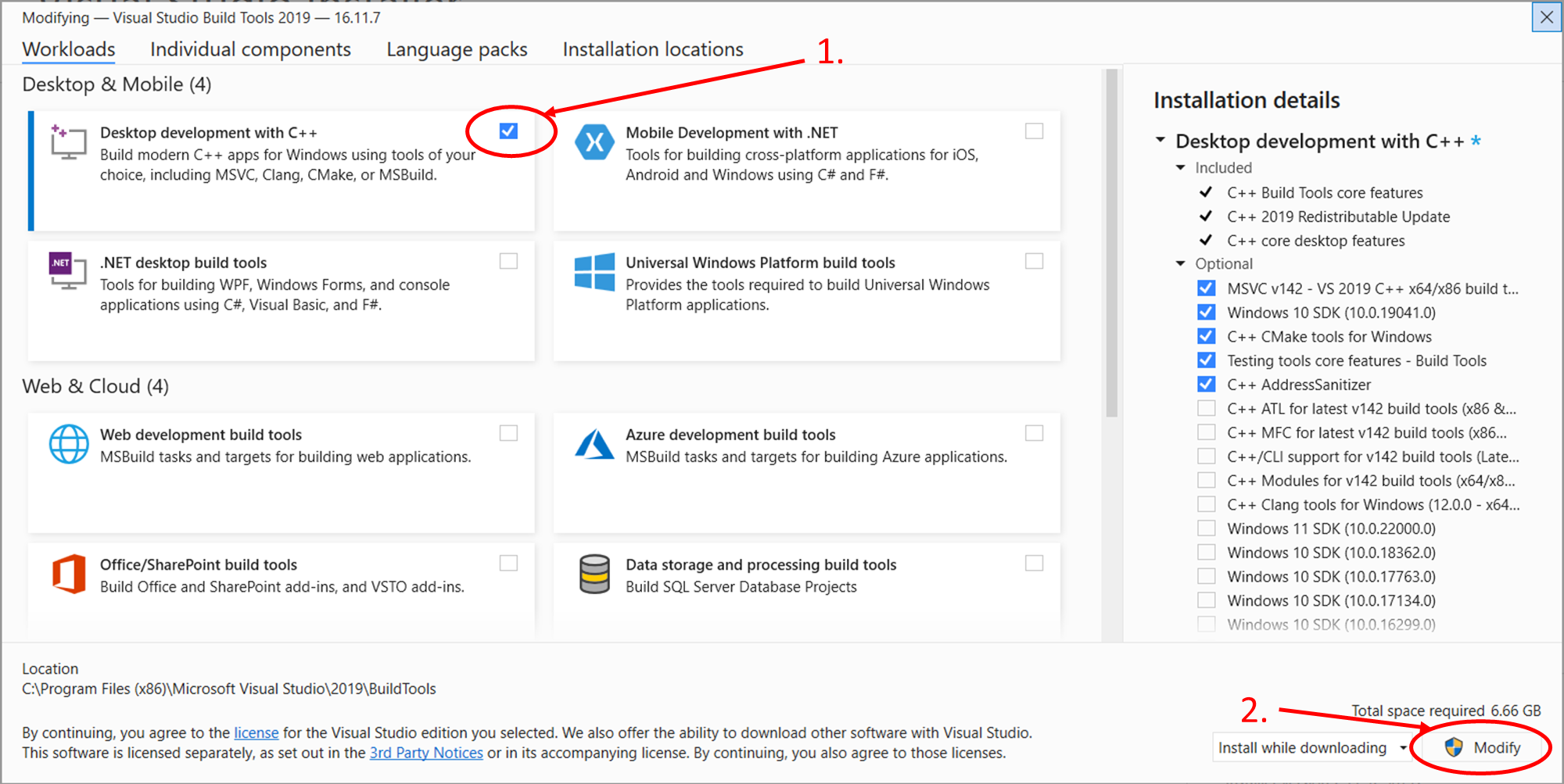
Then you can install Box2D for python using pip.
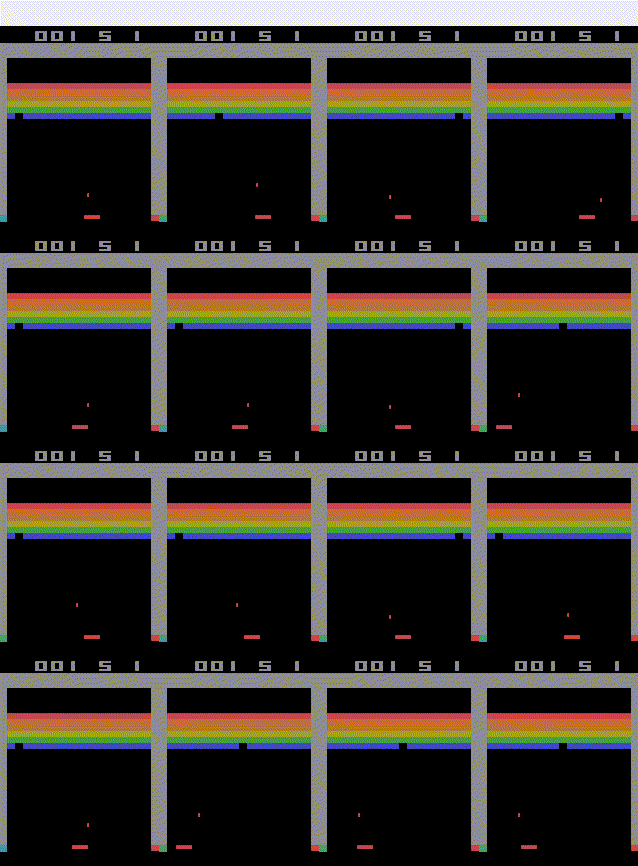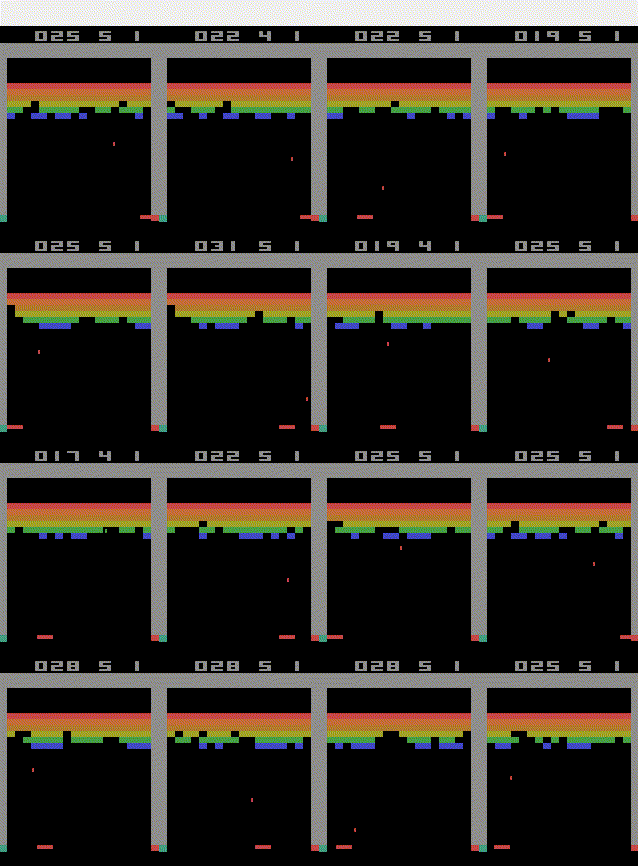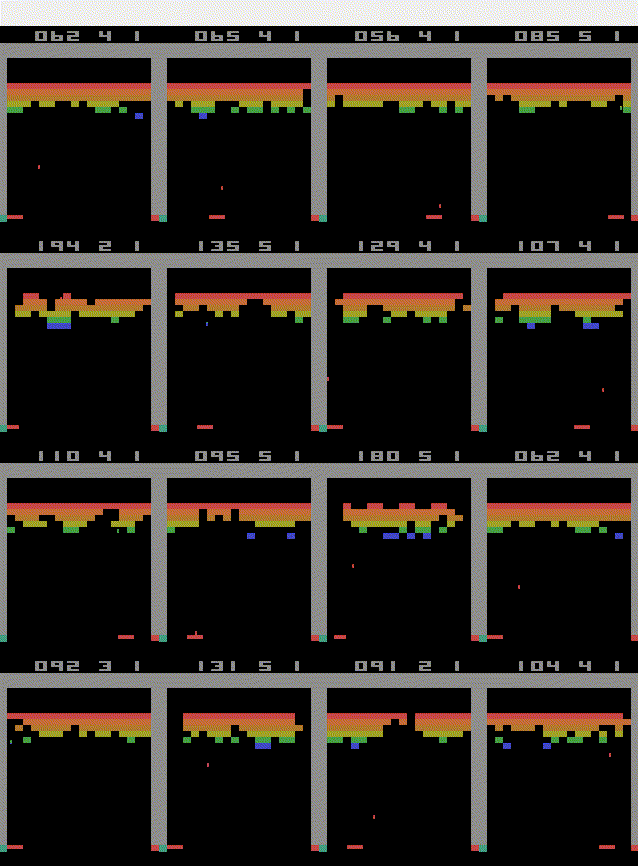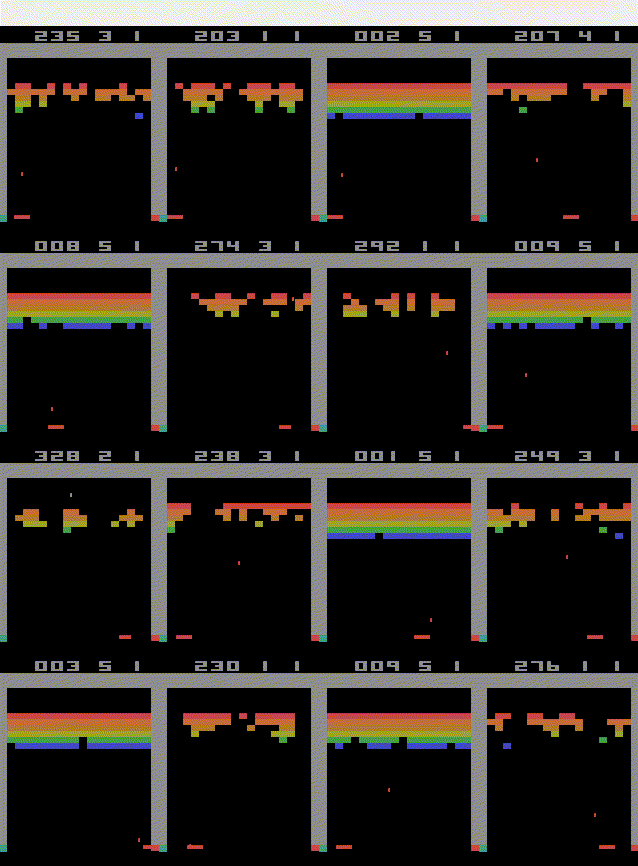
pip install box2d-pyBeating LunarLander-v2
I will now show you, how to beat the lunarLander-v2 environment using the stable_baselines3 library. The agents task is to land a landing module between the two yellow goal posts.
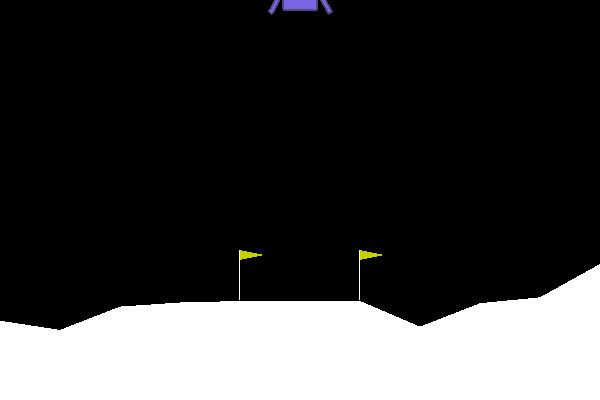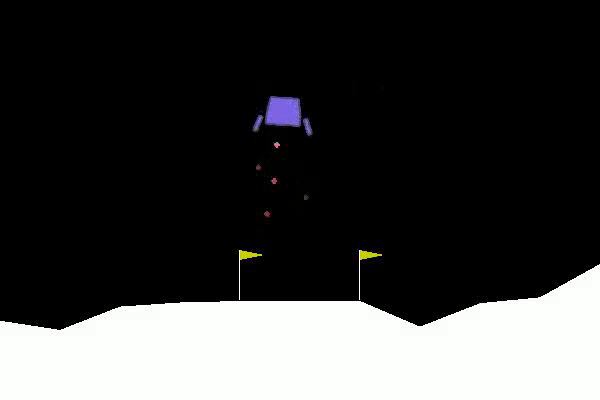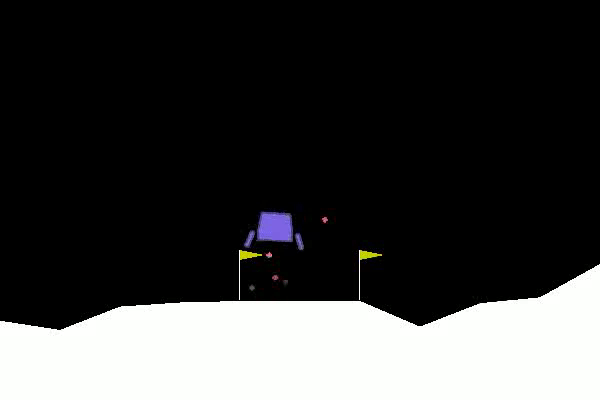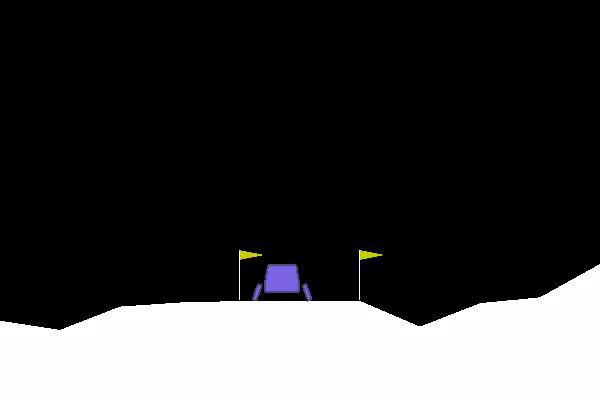
It is a more complex task than the cartpole environment. The agent is given the following information in form of a vector.
- (Continuous): X distance from target site
- (Continuous): Y distance from target site
- (Continuous): X velocity
- (Continuous): Y velocity
- (Continuous): Angle of ship
- (Continuous): Angular velocity of ship
- (Binary): Left leg is grounded
- (Binary): Right leg is grounded
So we have to use the MlpPolicy as well.
I chose the PPO algorithm to train the agent because I found it to be learning very fast in the LunarLander environment. It took the agent 2 million training steps to get to an average score of 233. The game is considered beaten at an average score of 200.
| import gym | |
| from stable_baselines3 import PPO | |
| # Parallel environments | |
| #env = make_vec_env("LunarLander-v2", n_envs=8) | |
| # Create environment | |
| env = gym.make('LunarLander-v2') | |
| # Instantiate the agent | |
| model = PPO('MlpPolicy', env, verbose=1) | |
| # Train the agent | |
| model.learn(total_timesteps=int(2e6)) | |
| # Save the agent | |
| model.save("ppo_lunar2") | |
| # Load the trained agent | |
| #model = PPO.load("ppo_lunar", env=env) | |
| # Enjoy trained agent | |
| obs = env.reset() | |
| for i in range(10000): | |
| action, _states = model.predict(obs, deterministic=True) | |
| obs, rewards, dones, info = env.step(action) | |
| env.render() | |
| if dones: | |
| obs = env.reset() |
Atari breakout from pixels
Now it is time for our agent to tackle "atari breakout" using only the pixels on the screen.

The breakout environment is not included in the standard installation of gym, so you have to install a gym version, that has the atari collection included.
pip install gym[atari]Given only a single image, the agent is not able to tell the speed and direction of the ball. Using the VecFrameStack wrapper, we give the agent a number of frames as input at the same time, so he can learn the movement of the ball.


Also be aware of the fact, that you have to know use "CnnPolicy" now. I trained the agent for 5 million timesteps with the A2C algorithm and used 16 parallel environments.
| from stable_baselines3.common.env_util import make_atari_env | |
| from stable_baselines3.common.vec_env import VecFrameStack | |
| from stable_baselines3 import A2C | |
| # There already exists an environment generator | |
| # that will make and wrap atari environments correctly. | |
| # Here we are also multi-worker training (n_envs=4 => 4 environments) | |
| env = make_atari_env('BreakoutNoFrameskip-v4', n_envs=16) | |
| # Frame-stacking with 4 frames | |
| env = VecFrameStack(env, n_stack=4) | |
| model = A2C("CnnPolicy", env, verbose=1) | |
| model.learn(total_timesteps=int(5e6)) | |
| obs = env.reset() | |
| #model = A2C.load("A2C_breakout") #uncomment to load saved model | |
| model.save("A2C_breakout") | |
| while True: | |
| action, _states = model.predict(obs) | |
| obs, rewards, dones, info = env.step(action) | |
| env.render() |
As you can see, the agent has learned the trick of making a hole in the bricks and shooting the ball behind the wall. However it has difficulties with shooting the last few bricks and is therefore not able to finish the game. This is most likely caused, because the agent was not trained sufficiently on situations with few bricks. By increasing the training duration, the agent should be able to beat the environment.
Conclusion
I want to take a brief moment the most important pieces of information about the stable-baselines3 library. When your environment provides a vector with information to the agent, then use the MlpPolicy. If it instead gives whole images, then use the CnnPolicy. You can use multiple environments in parallel to speed up the training. But they all train the same one agent. The cartpole environment can be beaten easily with a few thousand time steps of data. The LunarLander-v2 environment is more complex required 2 million timesteps to beat with PPO. Atari breakout will be solved with pixels and this makes it an even harder task. With 5 million timesteps, I was almost able to beat the environment using A2C.
Want to connect and support me?
Linkedin https://www.linkedin.com/in/vincent-m%C3%BCller-6b3542214/ Facebook https://www.facebook.com/profile.php?id=100072095823739 Twitter https://twitter.com/Vincent02770108 Medium https://medium.com/@Vincent.Mueller Become medium member and support me (part of your membership fees go directly to me)
Related stories
Deep Q learning is no rocket science






