System Design of URL Shortening Service

System design is one of the most important and feared aspects of software engineering. This opinion comes from my own learning experience in an associate architecture course. When I started my associate architecture course, I had a hard time understanding the idea of designing a system.
One of the main reasons was that the terms used in Software Architecture books are pretty hard to understand at first, and there is no clear step by step guidelines. Everybody seems to have a different approach.
So, I set out to design a system based on my experience of learning architecture courses. This is part of a series on system design for beginners (link is given below). For this one, let’s design the URL shortening service.
In Medium, we can see the URLs are pretty big, especially the friend links; while sharing an article, we tend to shorten the URL. Some of the known URL shortening services are TinyURL, bit.ly, goo.gl, rb.gy, etc. We are going to design such a URL shortening service.
★ Definition of the System:
We need to clarify the goal of the system. System design is such a vast topic; if we don’t narrow it down to a specific purpose, then it will become complicated to design the system, especially for newbies. URL shortening service provides shorter aliases for long URLs. When users hit the shortened links, they will be redirected to the original URL.

★ Requirements of the System:
In this segment, we decide the features of the system. What are the requirements we need to focus on? We may divide the system requirements into two parts:
- Functional requirement:
The user gives a URL as an input; our service should generate a shorter and unique alias of that URL. When users hit the shorter link, our system should redirect them to the original link. Links may expire after a duration. Users can specify the expiration time. We are not considering custom links by the user here.
This is a requirement that the system has to deliver. It is the main goal of the system.
- Non-Functional requirement:
Now for the more critical requirements that need to be analyzed. If we don’t fulfill this requirement, it might be harmful to the business plan of the project. So, let’s define our NFRs:
The system should be highly available. If the service is down, all the URL redirections will fail. URL redirection should happen in real-time. Nobody should be able to predict the shortened links.
Performance, modifiability, availability, scalability, reliability, etc. are some important quality requirements in system design. These ‘ilities’ are what we need to analyze for a system and determine if our system is designed properly.
In this system, availability is the main quality attribute. Security is another important attribute. Normally, availability and scalability are important features for system design. Performance is by default important, nobody wants to build a system with worse performance, right?!
★ How much request does the system need to handle?
Let’s assume, one user may request for a new URL and use it 100 times for redirection. So, the ratio between write and read would be 1:100. So the system is read-heavy.
How many URL requests do we need to handle in the service? Let’s say we may get 200 URL requests per second. So, for a month’s calculation, we can have 30 days 24 hours 3600 seconds*200 =~ 500 M requests.
So, there can be almost 500M new URL shortening requests per month. Then, the redirection request would be 500M*100 = 50 Billion.
For year count you have to multiply this number by 12.
★ How much storage do we need?
Let’s assume, the system stores all the URL shortening request and their shortened link for 5 years. As we expect to have 500M new URLs every month, the total number of objects we expect to store will be 500 M (5 12) months = 30 B.
Now let’s assume that each stored object will be approximately 100 bytes. We will need total storage of 30 billion * 100 bytes = 3 TB.
If we want to cache some of the popular URLs that are frequently accessed and if we follow the 80–20 rule, meaning we keep a 20% request from the cache.
Since we have 20K requests/second, we will be getting
*20K 60 seconds 60 minutes 24 hours = ~1.7 billion per day**
If we plan to cache 20% of these requests, we will need
0.2 1.7 billion 100 bytes = ~34GB of memory.
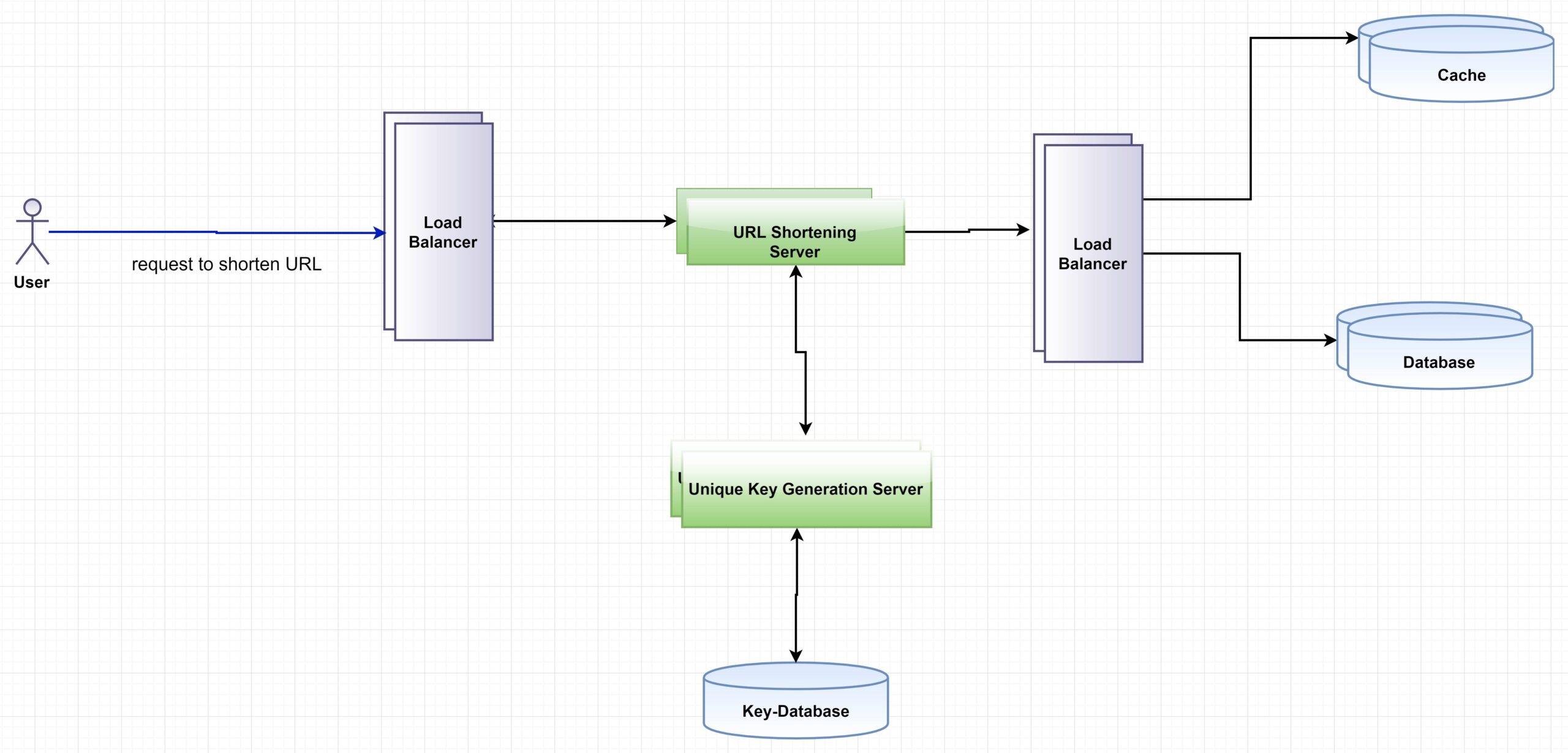
★ Data flow:
For newbies to system design, please remember, "If you are confused about where to start for the system design, try to start with the data flow."
Now, one of the main tasks of the server-side components is generating a unique key for an input URL. Here, our input data is only a URL. So, we need to store them as a string. The output is another shortened version of the URL. If somebody clicks on that shortened URL, it will redirect to the original URL. Now, each output URL needs to be unique.
★ Generate a short – unique key for a given URL
For example, we may take a random shortened URL "rb.gy/ln9zeb". The last characters should form a unique key. So, our input is a long URL given by users.
We need to compute a unique hash of the input URL. If we use base64 encoding, 6 characters long key will give us 64 ^(6)= ~68.7 billion possible strings, which should be enough for our system.
Problem: If multiple users enter the same URL, the system should not provide the same shortened URL. What if some strings are duplicated, what would be the system’s behavior?
Solution: We may append the input URL with an increasing sequence number to each request URL. It should make the URL unique. But, the overflow of sequence numbers might be a problem. We may append user-id to the input URL assuming user-id be unique.
★ Unique Key Generation:
In the system, user-id should be unique so that we can compute a unique hash. We can have a standalone Unique-key Generation Service(UGS) that generates random id beforehand and stores them in a database.

Whenever we need a new key, we can take one of the already generated IDs. This approach can make things faster as while a new request comes, we don’t need to create an ID, ensure its uniqueness, etc. UGS will ensure all the IDs are unique, and they can be stored in a database so that the IDs don’t need to be generated every time.
As we need one byte to store one character, we can store all these keys in:
6 (characters) * 68.7B (unique keys) ~= 412 GB.
★Availability & Reliability:
If we keep one copy of UGS, it’s a single point of failure. So, we need to make a replica of UGS. If the primary server dies, the secondary one can handle the requests of the users.
Each UGS server can cache some keys from key-DB. It can speed things up. But, we have to be careful; if one server dies before consuming all the keys, we will lose those keys. But, we may assume, this is acceptable since we have almost 68B unique six-letter keys.
For ensuring availability, we need to ensure to remove a single point of failure in the system. Replication for Data will remove a single point of failure and provide backup. We can keep multiple replications to ensure database server reliability. And also, for uninterrupted service, other servers also need copies.
★DataStorage:
In this system, we need to store billions of records. Each object we keep is possibly less than 1 KB. One URL data is not related to another. So, we can use a NoSQL database like Cassandra, DynamoDB, etc. A NoSQL choice would be easier to scale, which is one of our requirements.
★ Scalability:
For supporting billions of URLs, we need to partition our database to divide and store our data into different DB servers.
i) We can partition the database based on the first letter of the hash key. We can put keys starting with ‘A’ in one server, ‘B’ in another server. This is called Range Based Partitioning.
The problem with this approach is that it can lead to unbalanced partitioning. For example, there are very few words starting with ‘Z.’ On the other hand; we may have too many URLs that begin with the letter ‘E.’
We may combine less frequently occurring letters into one database partition.
ii) We can also partition based on the hash of the objects we are storing. We may take the hash of the key to determine the partition in which we can store the data object. The hash function will generate a server number, and we will store the key in that server. This process can make the distribution more random. This is Hash-Based Partitioning.
If this approach still leads to overloaded partitions, we need to use Consistent Hashing.
★ Cache:
We can cache URLs that are frequently accessed by the users. The UGS servers, before making a query to the database, may check if the cache has the desired URL. Then it does not need to make the query again.
What will happen when the cache is full? We may replace an older not used link with a newer or popular URL. We may choose the Least Recently Used (LRU) cache eviction policy for our system. In this policy, we remove the least recently used URL first.
★ Load balancer:
We can add a load balancing layer at different places in our system, in front of the URL shortening server, database, and cache servers.
We may use a simple Round Robin approach for request distribution. In this approach, LB distributes incoming requests equally among backend servers. This approach of LB is simple to implement. If a server is dead, LB will stop sending any traffic to it.
Problem: If a server is overloaded, the LB will not stop sending a new request to that server in this approach. We might need an intelligent LB later.
★ Link expiration after a duration:
If the expiration time is reached for a URL, what would happen to the link?
We can search in our datastores and remove them. The problem here is that if we chose to search for expired links to remove them from our data store, it would put a lot of pressure on our database.
We can do it another way. We can slowly remove expired links periodically. Even if some dead links live longer, it should never be returned to users.
If a user tries to access an expired link, we can remove the link and return an error to the user. A periodical clean up process can run to remove expired links from our database. As storage is getting cheaper, some links might stay there even if we miss while clean up.
After removing the link, we can put it back in our database for reuse.
★ Security:
We can store the access type (public/private) with each URL in the database. If a user tries to access a URL, which he does not have permission, the system can send an error (HTTP 401) back.
Conclusion:
In this system, we did not consider the UI part. And as this is a web service, so no client part is also discussed either. The unique key generation is an important part of this system. So, we added an extra service to create and store unique keys for URLs. For ensuring the availability of services, we used replication of servers so that if one goes down, others can still give service. Databases are also replicated to ensure data reliability. The cache server is used to store some popular queries to speed up the latency. And load balancer is added to distribute incoming requests equally among backend servers.
Source: Grokking the System Design Interview Course.
Thank you for reading the article. Have a good day 
This article is part of a series of system design for beginners. Here is the link.








