Supervised Fine-Tuning (SFT) with Large Language Models
Understanding how SFT works from idea to a working implementation…
Large language models (LLMs) are typically trained in several stages, including pretraining and several fine-tuning stages; see below. Although pretraining is expensive (i.e., several hundred thousand dollars in compute), fine-tuning an LLM (or performing in-context learning) is cheap in comparison (i.e., several hundred dollars, or less). Given that high-quality, pretrained LLMs (e.g., MPT, Falcon, or LLAMA-2) are widely available and free to use (even commercially), we can build a variety of powerful applications by fine-tuning LLMs on relevant tasks.
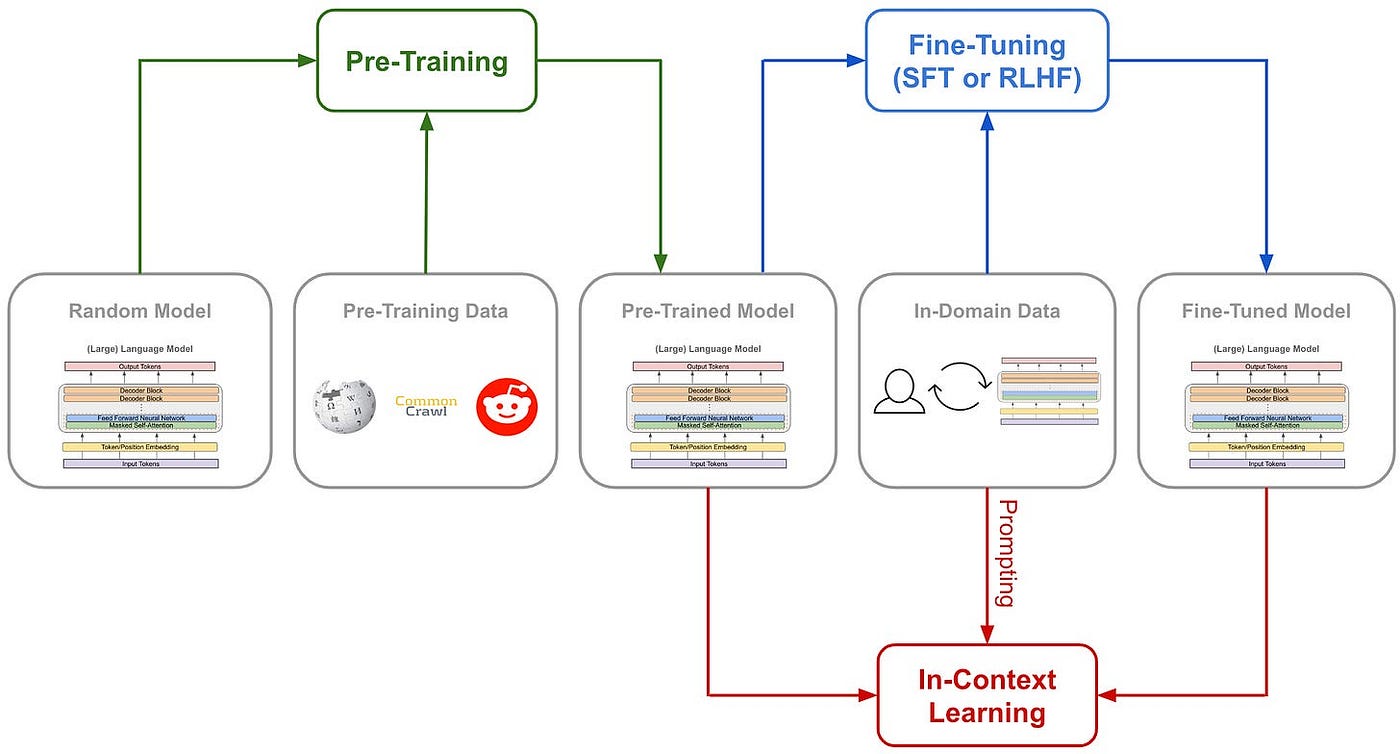
One of the most widely-used forms of fine-tuning for LLMs within recent AI research is supervised fine-tuning (SFT). This approach curates a dataset of high-quality LLM outputs over which the model is directly fine-tuned using a standard language modeling objective. SFT is simple/cheap to use and a useful tool for aligning language models, which has made is popular within the open-source LLM research community and beyond. Within this overview, we will outline the idea behind SFT, look at relevant…

