
During my tenure as a lead data analyst at Chime, three crucial SQL techniques— Window Functions, Regex, and CTEs – significantly advanced my capabilities, propelling me from intermediate proficiency to the expertise required for a lead analyst role. This article details these so you can up-level your skills and unlock new dimensions in data exploration.
Window Functions
A window function (or analytic function) makes a calculation across multiple rows that are related to the current row, and lets you calculate things like:
- Rankings
- Running totals
- 7-day moving averages (i.e. average values from 7 rows before the current row)
Creating rankings with window functions is an extremely powerful technique in Analytics and data science. Consider for this transactions dataset, where we have transactions made by customers.
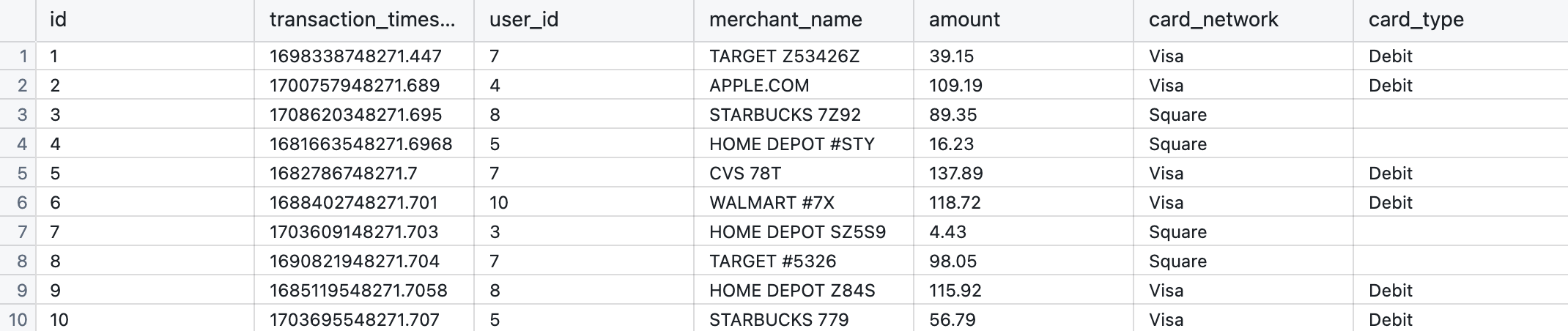
Ranking Window Functions:
A ranking window function allows us to add a column to generate a rank for each customer’s first, second, third etc. transaction. We could also add a ranking for their biggest to smallest transaction by amount
RANK()assigns a rank to each row within a partition based on specified criteria.PARTITION BYdivides the result set into partitions, and ranks are calculated separately for each partition.ORDER BYdetermines the order in which rows are ranked within each partition, with earlier rows receiving lower ranks.
SELECT *
, row_number() OVER (PARTITION BY user_id ORDER BY amount desc) AS transaction_amt_rank
FROM transactions;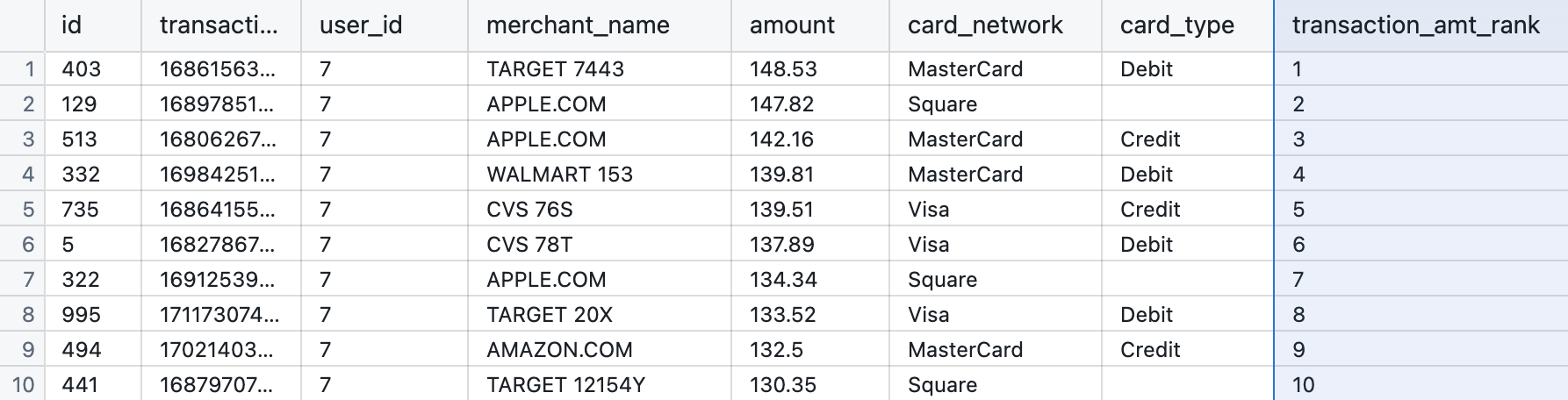
There are a variety of different window functions that you can use in SQL that have a few differences: rank(), dense_rank(), row_number() all vary, personally I like to use row_number() for it’s lack of repetition. For a full explainer, check out Data Camp’s cheat sheet
Regex
What is Regex? Regex is a type of data magic and a powerful tool for pattern matching and text manipulation.
and a powerful tool for pattern matching and text manipulation.
Regex stands for "regular expressions" and is a sequence of characters, used to search and locate specific sequences of characters that match a pattern.

If we look at our dummy transaction data, we have a list of merchant names, but most of them have extra stuff tacked on, like "TARGET #5326." This issue is very common in transaction data, where each retail location is unique and merchant_name often contains extra info, but in an analysis of spending behaviour, we only care that the person went to "Target"

TL;DR want all of the "Target", regardless of the numbers or words after them, to just say "Target." That’s where regex is an extremely powerful tool to have in your arsenal.
Let’s look at the code for how we could accomplish this:
Sql">REGEXP_REPLACE(source, pattern, replacement [, flags]) REGEXP: This part is saying, "I’m going to give you a special pattern to look for," which is more flexible than saying "find the exact word ‘Starbucks.’"
REGEXP: This part is saying, "I’m going to give you a special pattern to look for," which is more flexible than saying "find the exact word ‘Starbucks.’" ️ REPLACE: This means, "Once you find the pattern, replace it with what I tell you to." It specifies that once the pattern is found in the source string, it should be replaced with the specified replacement text.
️ REPLACE: This means, "Once you find the pattern, replace it with what I tell you to." It specifies that once the pattern is found in the source string, it should be replaced with the specified replacement text.source: The string where you want to perform the replacement.pattern: The regular expression pattern to search for insource.replacement: The string to replace the matches found by thepattern.flags(optional): Additional flags that modify how the regular expression engine interprets the pattern, such as case sensitivity.
-- here we're removing any *numbers* from our merchant_name
SELECT merchant_name
, REGEXP_REPLACE(merchant_name, '[0-9]', '', 'g') as merchant_name_cleaned
, count(distinct id) as txn_cnt
FROM
transactions
group by 1 order by count(distinct id) descAnd this kind of cleans it up, and could be useful in other situations, but doesn’t do much to make the merchant_name less unique, running the above code still leaves us with a bunch of extraneous characters.
So, let’s try something more advanced with our Regex.
Below we’re searching for patterns that consist of alphanumeric characters with at least one digit sandwiched between them, and replace them with an empty string. The 'g' flag at the end indicates that it should replace all occurrences of the pattern, not just the first one.
SELECT merchant_name
, REGEXP_REPLACE(merchant_name, '[0-9]', '', 'g') as merchant_name_cleaned1
, REGEXP_REPLACE(merchant_name, '[[:alnum:]]*[[:digit:]][[:alnum:]]*', '', 'g') AS merchant_name_cleaned2
, count(distinct id) as txn_cnt
FROM
transactions
group by 1,2 order by count(distinct id) desc
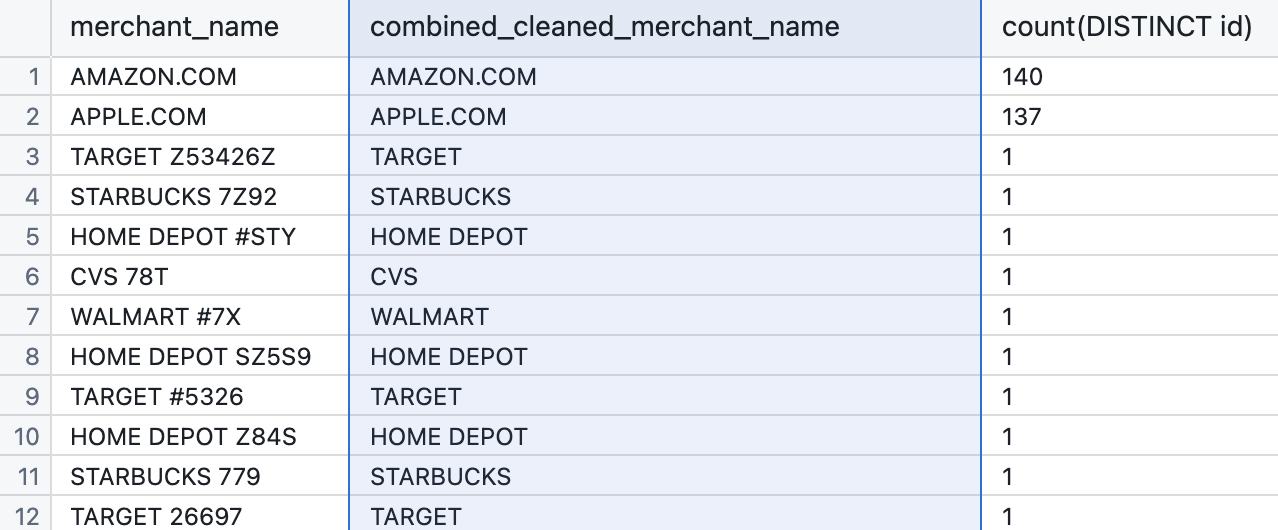
This is great, but doesn’t handle everything. Notably we’re still stuck with some pesky "#Y73" at the end of some of our merchant names.
So how can we fix that and really clean up our Merchant Names? By
select merchant_name,
--- **NEST** our previous two regex into one
REGEXP_REPLACE(
REGEXP_REPLACE(merchant_name, '#[[:alnum:]]*', '', 'g'),
'[[:alnum:]]*[[:digit:]][[:alnum:]]*',
'','g'
) AS combined_cleaned_merchant_name
, count(distinct id)
from transactions
group by 1,2
order by 3 descLet’s break down our final clean-up code (above):
- The first
REGEXP_REPLACEfunction targets segments with a hash#followed by alphanumeric characters, a common pattern we’ve identified as ‘noise’ in our data. - The second
REGEXP_REPLACEfunction looks for any sequence containing digits, whether they’re alone or mixed with letters, and eliminates them.
This two-pronged approach helps us remove extraneous characters effectively, leaving us with clean merchant names like "TARGET" instead of "TARGET #5326" and leaves us with a really lovely clean & workable new Merchant Name, which I’ve named combined_cleaned_merchant_name
CTEs
Common Table Expressions (CTEs) are a feature of SQL that allow you to define a temporary result set which you can then reference. CTEs are a powerful way to simplify complex logic and queries by breaking them down into more manageable parts. This process simplifies ordinarily complex queries by splitting them into basic parts that can be used and reuse in query rewriting.
tl;dr CTEs are how you get to the next level of SQL

How CTEs Work:
CTEs are defined with the WITH keyword, followed by the CTE name and an AS clause that contains a query. The CTE is then available to the main query and can be treated much like a regular table or subquery.
WITH x AS (
SELECT
[Your Query Here]
)
SELECT * FROM x;Here’s a basic structure of how a CTE (named "x") is written in SQL, using our learnings from before, we can easily create and access a subset of transactions that is each user’s first purchase, with our newly cleaned Merchant Name, that we can reference it with other queries.
with x as (select id, transaction_timestamp, user_id, amount
, REGEXP_REPLACE(
REGEXP_REPLACE(merchant_name, '#[[:alnum:]]*', '', 'g'),
'[[:alnum:]]*[[:digit:]][[:alnum:]]*',
'','g') AS merchant_name_cleaned
, row_number () over (partition by user_id order by transaction_timestamp) as user_txn_rank
from transactions
)
select *
from x
where user_txn_rank = 1Grasping the concept of CTEs is like unlocking a new level in your SQL journey – think of it as moving from being a skilled apprentice to a wizard. With CTEs in your spellbook, you can effortlessly segment and dissect your data, laying it out for in-depth analysis or combining it with other queries in ways that were once cumbersome or downright mystifying.
CTEs don’t just make your queries more readable and organized; they open doors to analyses that were previously tucked away in the realm of "too hard" or "too complex."
In conclusion, embracing Window Functions, Regex, and CTEs transforms SQL from a mere querying language into a powerful tool for crafting intricate data stories
This article offers a gateway to advanced SQL techniques, and by mastering these techniques, you not only sharpen your analytical skills but also unlock new dimensions in data exploration.
Thanks for reading!
Sources + Recommended Resources:
- Atlassian. "Using Common Table Expressions." Retrieved from https://www.atlassian.com/data/sql/using-common-table-expressions.
- DataCamp. "SQL Window Functions Cheat Sheet." Retrieved from https://www.datacamp.com/cheat-sheet/sql-window-functions-cheat-sheet.






