Inside AI
Robotic Control with Graph Networks
Exploiting relational inductive bias to improve generalization and control

Machine learning is helping to transform many fields across diverse industries, as anyone interested in technology undoubtedly knows. Things like computer vision and natural language processing were changed dramatically due to deep learning algorithms in the past few years, and the effects of that change are seeping in to our daily lives. One of the fields that artificial intelligence is expected to make drastic changes to, is the field of robotics. Decades ago, science fiction writers envisioned robots powered by artificial intelligence interacting with human society and either helping solve humanity’s problems or trying to destroy human-kind. Our reality is far from it, and we understand today that creating intelligent robots is a harder challenge than was expected back in those days. Robots must sense the world and understand their environment, they must reason about their goals and how to achieve them, and execute their plans using their actuation means.
When we humans think about picking up a glass of water from the table we might have a general idea of the trajectory we would like our hand to travel in, but in order to actually do that our brain needs to send a very long and complex sequence of electrical signals through the nervous system to cause the right contractions in the muscles. Our sensory systems observe the effects of those electrical signals (we see how our hand moves) and our brain compensates for miscalculations using this feedback. This process is called feedback control and is one of the challenges facing robot designers and robotics researchers. Not only does our robot need to plan how its arm should move through space to grasp an object, it must also specify the voltages that need to be applied to its motors so that the proper torques and forces be achieved and the objective accomplished.
Feedback control is a vast field with a very rich theory and many applications in almost every aspect of our life. Elevators, cars, airplanes, satellites and countless other everyday objects rely on control algorithms to regulate some aspect of their internal operation. Control theory provides control engineers with tools for designing stable and reliable control algorithms to many critical systems, and these methods often rely on a solid understanding of the underlying dynamics of our system.
When designing the control system that stabilizes airplanes and their autopilot software, engineers rely heavily on decades of research and experience in aircraft dynamics. How an aircraft reacts to changes in the angles of its control surfaces is a relatively well understood process, and this provides great benefits when trying to figure out how to control such a system.

Unfortunately, not all systems are understood with this level of detail, and the process of obtaining this knowledge is often very long and requires many years of research and experimentation. As technology advances so the complexity of the systems we build increases, which creates many challenges for control engineers.
A straightforward approach in this age of machine learning would of course be to learn a model of the dynamics from data collected during experiments. For example, we can think of a robotic arm with a simple grasper. The state of the arm is comprised of the angles and angular velocities in each of its joints, and the actions we can take are the voltages in each of the motors that are built inside the joints. These voltages affect the state of the robotic arm, and we can think of it as a function:

Which means that our dynamics can be thought of as a function that maps state-actions to states, and through learning we might approximate it using some model like a neural network:

Where theta represents the parameters of our neural network. This process is also often done in model-based reinforcement learning algorithms, in which a learned model of the dynamics is used to accelerate the process of learning a policy. Disappointingly, this often fails, and the learned model tends to generalize poorly to states it has not seen before in addition to the phenomena of compounding errors that arise when using look-ahead. One of the reasons learned models fail to generalize well is because many neural network architectures are very general functions approximators and thus have a limited capacity to generalize to unseen phenomena.
Neural Networks and Inductive Bias
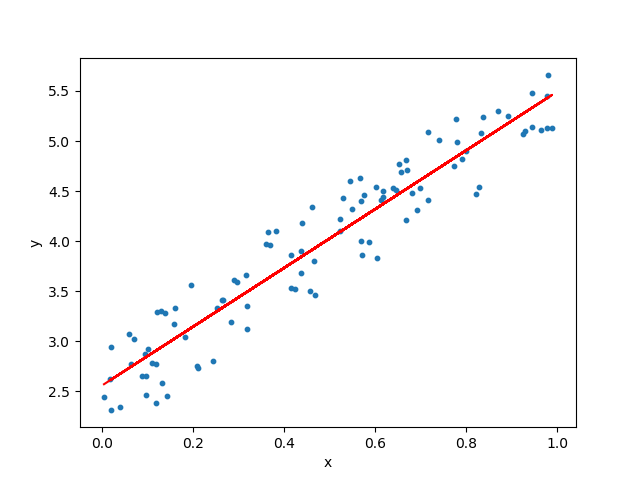
Let’s visualize this with a simple example. Suppose we sample points from a function that resembles a linear line and try to fit a learned model to this function.

If we try to approximate this data using a simple feed-forward neural network, we will probably get solid performance in the range of values that our data was sampled from, and if we did a good job we might do well to some extent even somewhat beyond that range. But anyone who has worked with neural networks knows that if we trained a network on input values that range from 0 to 1 (as in the above illustration) and attempt to predict the output for something like 1000, we would get complete and utter garbage as output. However, if instead of using a neural network we would use a linear approximation as our model, we might still get decent performance even far beyond the training input range. This is because our data is sampled from a noisy linear line, and using a linear approximation reduces the hypothesis space of models we must search only to those that are good candidates in the first place. A neural network is a far more general model and can approximate functions with arbitrary structure, but this doesn’t mean that it is the best choice for the job.
A similar phenomenon was observed when convolutional neural networks were used for image processing. In principle, a feed forward neural network can approximate any function, including an image classifier, but this might require enormous models and mind-boggling amounts of data to do. Convolutional networks (or CNNs), perform these tasks much more efficiently by exploiting the structure inherent in the problem, such as the correlation between adjacent pixels and the need for the shift invariance property in the neural network.

Graph Networks
Returning to our problem of approximating the dynamics of robotic system, a common feature of conventional neural architecture for this problem is that they treat the system as a single component. For example, when modeling our robotic arm, we could have the input to our neural network be a vector containing all the angles and angular velocities of our arm.

This is the standard way in which the system is modelled in common RL benchmarks, and generally works well in tasks of policy optimization. But when trying to learn the dynamics of our robotic arm, this is insufficient, and it’s because a robotic arm is not just a vector of angles and angular velocities. A robotic arm has structure, it is built of several joints that share the same underlying physics and interact with each other in a way that has to do with how they are assembled.
Bearing this in mind, we would like our neural network architecture to address the system in such a way, and as is turns out we can do this with a special neural network that operates on graph data.
Researchers from Google’s DeepMind published a paper in 2018 titled “Relational Inductive Biases, Deep Learning and Graph Networks”. In this paper they introduced a new neural network architecture which they called graph networks, and showed that it can be used to very accurately model different physical phenomena that occur in interactions between objects, such as planets in a multi body gravitational system, interactions between rigid body particles and even sentences and molecules. The idea of neural networks that can operate on graph data predates this paper, but the graph networks architecture generalizes many previous variants of graph neural networks (GNNs) and extends them.

An obvious limitation to this approach is that we need to know something about the structure of our system in order to model it as a graph. In some cases, we might not have that knowledge, but in many other cases we do, and exploiting this knowledge could make our learning problem much easier.
So how do these graph networks work? In a nutshell, the DeepMind formulation of a graph consists of the regular nodes and edges, and in addition a global vector. In each layer of the network, each edge is updated using the node from which it begins and that in which it ends. After that, each node is updated using the aggregate of the edges that end in it, and then the global vector is updated using all the nodes and edges.

This process can be visualized in the above illustration from the paper; first edges are updated by taking their features along with those of their sender and receiver nodes and using a feedforward neural network to update the edge feature vector. After that, nodes are updated by taking their features along with an aggregation of all the incoming edges, and applying another NN on them. At last, the aggregate of all the nodes and edges is taken together with the global vector and another NN is used to update the global vector features.
Model Predictive Control with Learned Models
In another paper published simultaneously, called “Graph Networks as Learnable Physics Engines for Inference and Control”, DeepMind researchers used graph networks to model and control different robotic systems, in both simulation and a physical system. They modelled these different robotic systems as a graph and used data to learn a model of the dynamics. An example of such a graph from the paper can be seen:

Modelling the system in this way, the authors achieved very accurate predictions of future states that generalized well to systems with variations in their parameters, such as longer torsos or shorter legs.
A powerful control method used in many applications is Model Predictive Control (MPC). In MPC, our controller uses a linear model of the dynamics to plan ahead a fixed number of steps, and take the derivative of an analytical cost function with respect to the trajectory to optimize it using gradient descent. For example, suppose we have a linear model of our robotic arm, and we wish that it follows a desired trajectory, how can we find the actions needed to do so?
Suppose our cost function is of this form:

Which means that at each step we wish to minimize the distance between the reference trajectory we would like to follow and the actual trajectory, and we also wish to minimize the expenditure of energy, which is what the second term does (suppose a is the voltage we use in our motor).
Using the fact that we have a linear model of the dynamics, we can write it again as:

And since our cost function and model are both differentiable, we can take the derivative of this cost function with respect to the set of actions, and iteratively optimize it using gradient descent.

The same thing can be done with the more complex graph network model of the dynamics. It too is differentiable with respect to the actions, and we can perform Model Predictive Control in a similar manner.
As it turns out, this worked very well, and control using the learned model worked in many cases just as well as control using the real physics model behind these simulated robotic systems. This is a very big step towards the ability to learn dynamics models and control policies for complex robotic systems, with robustness to uncertainties and flexibility to system physical parameters.

{kind=link}