Thoughts and Theory
Reinforcement Learning
A Review of the Historic, Modern, and Future Applications of this Special Form of Machine Learning
Contents
1. Introduction
2. Historic Developments (pre 1992)
— 2.1. Concurrent Developments
— — 2.1.1. Learning by Trial and Error
— — 2.1.2. The Problem of Optimal Control
— — 2.1.3. Temporal Difference Learning Methods
— 2.2. Combined Developments
3. Modern Developments (Post 1992)
— 3.1. Developments in Board Games
— 3.2. Developments in Computer Games
4. Current Developments
5. Future Developments
6. Conclusion
7. References
1. Introduction
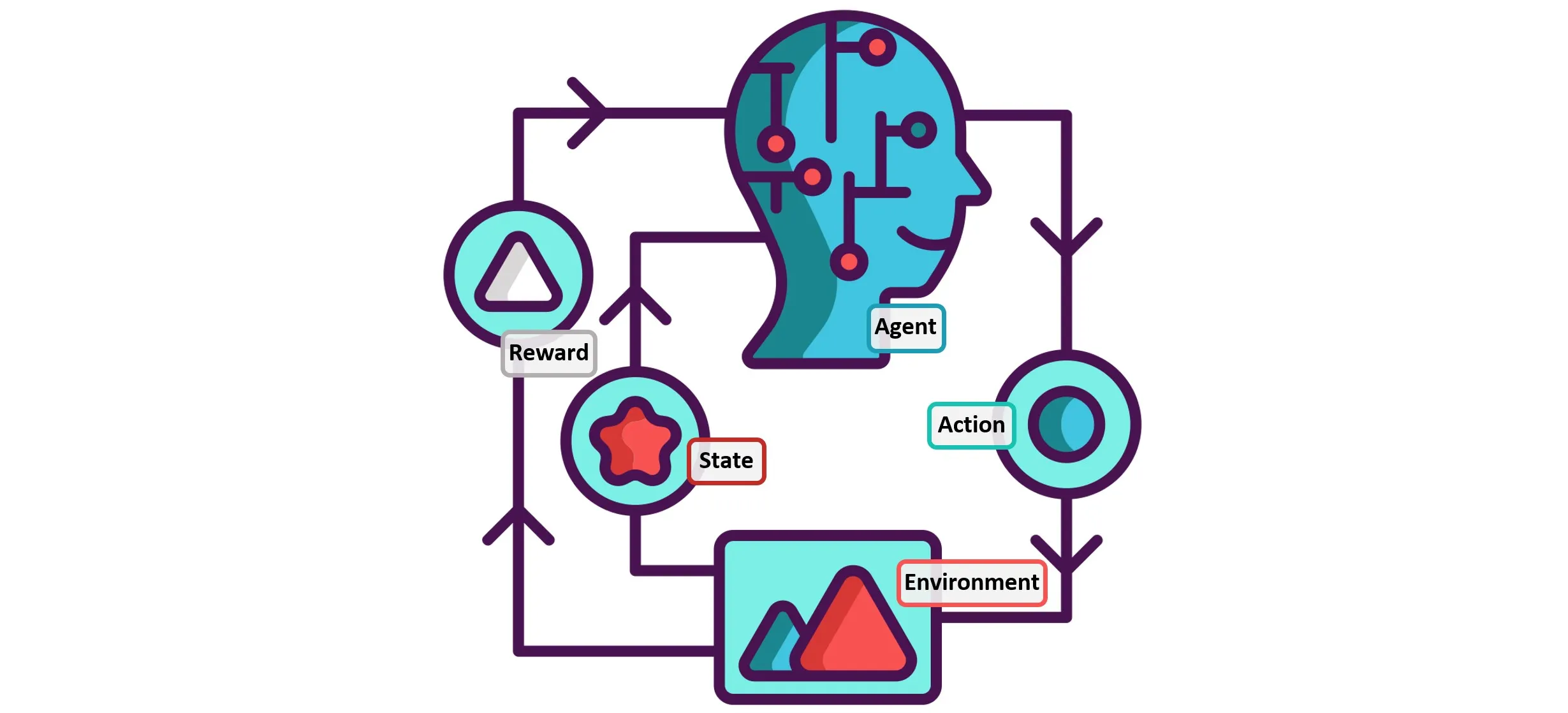
Reinforcement Learning is not a new concept, but has been developed and matured over 70 years of academic rigour. Fundamentally, Reinforcement Learning is a method of machine learning by which an algorithm can make decisions and take actions within a given environment, and learns what appropriate decisions to make through repeated trial-and-error actions. The academic discourse for Reinforcement Learning pursued three concurrent ‘threads’ of research (trial and error, optimal control, and temporal difference), before being united in the research in the 1990’s. Reinforcement Learning was then able to proceed to mastering the playing of Chess, and of Go, and of countless electronic games. The modern applications of Reinforcement Learning are enabling businesses to optimise, control, and monitor their respective processes, to a phenomenal level of accuracy and finesse. As a result, the future of Reinforcement Learning is both exciting and fascinating, as the research aims to improve the algorithm’s interpretability, accountability and trustworthiness.
2. Historic Developments (pre 1992)
Sutton & Barto (2018) discuss the three ‘threads’ of Reinforcement Learning as being: 1) Learning by trial-and-error; 2) The problem of optimal control; and 3) Temporal difference learning methods. These threads were pursued by researchers independently before becoming intertwined in the 1980’s leading to the concept of Reinforcement Learning as we know it today.
2.1. Concurrent Developments
2.1.1. Learning by Trial and Error

When observing animal intelligence, Thorndike (1911) defined trial-and-error as the ‘Law of Effect’ as associated with a feeling of satisfaction or discomfort resulting from a given situation. This concept was integrated into the Machine Learning analogue when Minsky (1954) postulated the use of SNARCs (Stochastic Neural-Analogue Reinforcement Calculators), which was further crystallised when Minsky (1961) addressed the ‘Credit Assignment Problem’; which is how to distribute credit for success among the many decisions that may have been involved in producing it. Research in computational trial-and-error processes was generalised to pattern recognition (Clark & Farley 1955; Farley & Clark 1954) before being adapted to supervised learning by using error information to update connection weights (Rosenblatt 1962; Widrow & Hoff 1960). Due to this blurring of the distinction between traditional trial-and-error, and error-and-loss functions, there were very few publications throughout the 1960’s and 1970’s specifically addressing Reinforcement Learning. One such researcher who was continuing in this area was John Andreae who developed the STELLA system (Andreae 1963), which learns through interaction with its environment, and machines with an ‘internal monologue’ (Andreae & Cashin 1969), and then later the machines that can learn from a teacher (Andreae 1977). Unfortunately, as Sutton & Barto (2018) discuss, Andreae’s pioneering research was not well known, and did not greatly impact subsequent reinforcement learning research.
2.1.2. The Problem of Optimal Control

The research in to ‘optimal control’ began in the 1950’s, and is defined as “a controller to minimize a measure of a dynamical system’s behaviour over time” (Sutton & Barto 2018). Bellman (1957a) built upon the work of Hamilton (1833, 1834) and Jacobi (1866) to develop a method specific for Reinforcement Learning which dynamically defines a functional equation, using a dynamic system’s state, and returns an optimal value function. This “optimal return function” is now often referred to as the Bellman equation, which is technically a class of methods used for solving control problems, and is the main focus of Bellman’s book Dynamic Programming (Bellman 1957a). Bellman went on to introduce the Markovian Decision Process (1957b) — which he defines as “a discrete stochastic version of the optimal control problem” — which Howard (1960) leveraged to define a policy iteration method for Markovian Decision Processes. Through the 1960’s and 1970’s, there was not much research in the area of ‘optimal control’; however, Bryson (1996) notes that since the 1980’s, there has been many papers published in areas such as partially observable Markovian Decision Processes, along with its applications, approximation methods, asynchronous methods, and modern treatments of dynamic programming.
2.1.3. Temporal Difference Learning Methods
Taking its inspiration from mathematical differentiation, temporal difference learning aims to derive a prediction from a set of known variables. But an important difference is that it does so by bootstrapping from the current estimate of the value function. It is similar to the Monde Carlo method (Hammersley 1964), but it is able to adjust the final predictions in the later iteration stages, before the final outcome is known (which Monte Carlo cannot); as illustrated by Sutton (1988) with the example where on a given Sunday a forecast is created for the following Saturday, then updating the Saturday forecast on Friday, before the actual Saturday weather is known.
The origins of temporal difference methods are rooted in animal learning psychology (Thorndike 1911), particularly the notion of ‘secondary reinforcers’. Effectively, when a secondary reinforcer (eg. a stimulus) is paired with a primary reinforcer (eg. food or pain), the secondary reinforcing adopts similar properties as the first. Minsky (1954) was the first to realise the importance of temporal difference methods for reinforcement learning, though Samuel (1959) seemed to be the second to realise this importance but who did not reference Minsky in his work. Minsky (1961) built upon the work of Samuel (1959) and reinforced the importance of this concept to Reinforcement Learning theories. The temporal difference method and the trial-and-error method became entangled when Klopf (1972, 1975) investigated reinforcement learning in large systems as conceptualised by individual sub-components of the larger system, each with their own excitatory inputs as rewards and inhibitory inputs as punishments, and each could reinforce one another.
2.2. Combined Developments
Leveraging Klopf’s ideas, Sutton (1978a, 1978b, 1978c, 1984) further develops the links to animal learning theory, and further explored the rules by which learning is driven by changes in temporally successive predictions. This work virtually opened the academic floodgates for research into reinforcement learning, as the years following this saw numerous influential developments such as:
- A psychological model of classical conditioning (Barto & Sutton 1981a, 1981b, 1982; Sutton & Barto 1981a, 1981b);
- A neuronal model of classical conditioning (Klopf 1988; Tesauro 1986);
- A temporal-difference model of classical conditioning (Sutton & Barto 1987, 1990);
- The ‘Actor-Critic Architecture’ as applied to the pole-balancing problem (Barto et al. 1983);
- The extension of ‘Actor-Critic Architecture’ and integration with backpropagation neural network techniques (Anderson 1986; Sutton 1984);
- The separation of temporal-difference learning from the control decision and the introduction of the
lambda()property (Sutton 1988).
The three ‘threads’ of Reinforcement Learning genesis were finally united when Watkins (1989) developed Q-Learning (Watkins 1989), which was reinforced by Werbos (1987) who advocated for the convergence of trial-and-error learning and dynamic programming. After this, researchers explored automated electronic implementations of reinforcement learning, and was able to achieve some amazing results.
3. Modern Developments (post 1992)
3.1. Developments in Board Games
In 1992, Tesauro was able to implement these concepts in his development of the TD-Gammon program (Tesauro 1994) which was able to was able to achieve ‘Master Level’ in the game of Backgammon. Research had shifted to attempt to apply this success to the game of chess (Baxter et al. 2000, 2001; Thrun 1995). IBM developed DeepBlue for the sole purpose of playing chess. However, it suffered from the curse of dimensionality, because the algorithm took too much time to calculate, it could not ‘see’ far enough in the future, and it became notorious for very poor opening moves (Szita 2012). Nevertheless, DeepBlue won against a world champion in 1997 (King 1997; Levy 1997; Newborn 2000; Santo 1997).
Researchers then pursued a larger and even more complicated game: Go. While many attempts were made to try and learn how to play the game (Bouzy 2006a, 2006b; Bouzy & Helmstetter 2004; Coulom 2007a, 2007b; Dahl 1999; Gelly & Silver 2008; Gelly et al. 2006; Schraudolph et al. 2001; Silver et al. 2008), none were able to win against a world champion until Google’s AlphaGo took the title in 2016 (Borowiec 2016; Moyer 2016). The difference between DeepBlue and AlphaGo was that DeepBlue utilised a parallelised tree-based search methodology with customised hardware advances to effectively use ‘brute force’ to calculate all of the moves required to win the game (Borowiec 2016; Newborn 2000); but this method is not possible in Go as there are simply too many moves and possible combinations that the computational overhead would be impossible. Comparatively, AlphaGo utilised a combination of Monte Carlo simulations, Monte Carlo tree search, Bayesian optimisation, and physically watching the previous matches of world champions (Chen et al. 2018; Fu 2016; Wheeler 2017), in order to build a strong-enough model, and without needing to perform brute-force calculations of future moves. These developments mark significant advancements in the world of Reinforcement Learning, and is enabling the entire world to see what some of the possibilities are with this particular machine learning technique.
3.2. Developments in Computer Games
As children growing up in the 1980’s and 1990’s, many people played Atari video games. They were released in 1977 and contained 526 games including classics like Pong, Breakout and Space Invaders (Wikipedia 2020). The Atari emulator provided an ideal environment for a Reinforcement Learning algorithm to learn how to play the game (Hausknecht et al. 2014; Kaiser et al. 2019; Mnih et al. 2013) due to its pixel-based display and simple control options. After some time playing the games, the researchers observed some very impressive techniques being used by the algorithm; for example, in Breakout, it was able to drill a hole in order to win the game with less effort. This is indicative of the power of Reinforcement Learning, particularly that it is able to learn certain rules and practices which were not otherwise programmatically told to the model (Berges et al. nd; Patel et al. 2019; TwoMinutePapers 2015). Many other computer games have also seen developments with Reinforcement Learning, including games like Snake, Flappy Bird, Angry Birds, and Candy Crush. Modern-day computer games have made substantial advancements since the Atari games, and they provide a much more complex and dynamic environment which provides a multitude of learning opportunities for applications of Reinforcement Learning.
4. Current Developments

While the history of Reinforcement Learning has been fascinating, the applications of Reinforcement Learning in our modern times is really exciting. In a recent article, Garychl (2018) lists some examples of Reinforcement Learning being applied in industry today; including: resource management in computer clusters, traffic light control, robotics, web system configuration, chemistry, advertisement, and games. Lorica (2017) consolidates these opportunities in to three main themes of applications, which can quite literally be applied to any business in any industry: to optimize (eg. process planning, yield management, supply chain), to control (eg. autonomous vehicles, factory automation, wind turbine control), and to monitor and maintain (eg. quality control, predictive maintenance, inventory monitoring). All of these applications provide an environment, an action, a response, and a method for optimisation, therefore allow the opportunity for reinforcement learning algorithms to be applied to these specific cases.
Quite simply, businesses should seek to implement Reinforcement Learning in to their AI strategies when they face any of the below scenarios (Chahill 2017):
- They are using simulations because the system or process is too complex (or too physically hazardous) for teaching machines through trial and error; or
- They are dealing with large state spaces; or
- They are seeking to augment human analysis and domain experts by optimizing operational efficiency and providing decision support.
5. Future Developments
The future of Reinforcement Learning is a highly subjective discussion, and one in which many people may have quite diverging opinions. There are two main directions for the future of Reinforcement Learning, which can be generalised as follows:
- The future is bright, there is wide adoption and implementation of Reinforcement Learning, and it continues to have a positive impact on humanity; or
- The future is grim, people revolt against the progressive infiltration of Reinforcement Learning in their lives, and the future developments of AI are focussed on techniques other than Reinforcement Learning.
The phenomenal amount of advancement that has taken place in the world of Reinforcement Learning and the positive impact that it has already had on our society, indicates that this trend will continue and will continue into the future. Godbout (2018) discusses the bright future of Reinforcement Learning, while Kirschte (2019) discusses that Reinforcement Learning will continue to make substantial advances, and will make the day-to-day lives of businesses easier and more efficient. Of the two options, this bright future is the most likely scenario.

However, it would be remiss not to discuss some of the societal apprehension behind the rise of AI, and some of the anxiety resulting from some Hollywood movies about AI. Frye (2019) discusses some concerning issues around AI & specifically Reinforcement Learning, mentioning that Reinforcement Learning is unsafe due to task specification (difficulty in precisely specifying exactly what task the AI Agent is expected to perform), and unsafe exploration (the Agent learns from trial-and-error, implying that it must first make a mistake for it to learn what not to do), which may result in incidents and injuries (or worse) for our fellow citizens. Particularly if we consider the example of self-driving cars. Knight (2017) explicitly explores this example, focussing on the Nvidia self-driving car which has learnt to drive not through any programmatic command given to it, but instead through observation of other drivers. While this is an impressive feat unto itself, has the underlying issue to that the creators do not know how or why the computer is making decisions, and this will undoubtedly put people’s lives at risk on the roads. Therefore, there are a couple of improvements which Reinforcement Learning needs to make before it will be widely accepted and adopted by the broader community. Those being in the areas of interpretability to the creators and accountability to the users. Once these two issues are rectified, then Artificial Intelligence and Reinforcement Learning will undoubtedly become more trustworthy.
6. Conclusion
Reinforcement Learning has come a phenomenally long way since its inception in the 1950’s; and it still has a long way to go in its pathway of development and maturity. From the theoretical and conceptual advancements made up to the 1990’s, Reinforcement Learning has conquered the games of Chess and of Go, and of countless electronic computer games. Reinforcement Learning has also begun to debut in business and in industry and is continuing to prove beneficial and useful in the ever-growing challenge of our modern society. The future of Reinforcement Learning will soon infiltrate our everyday lives in many, many different ways; but not before a few fundamental issues are rectified with its interpretability, accountability, and trustworthiness. Nevertheless, the future of Reinforcement Learning appears to be long and bright, and we will continue to see many great things from this powerful area of Artificial Intelligence.
7. References
Anderson, C. 1986, Learning and Problem-Solving with Multilayer Connectionist Systems (Adaptive, Strategy Learning, Neural Networks, Reinforcement Learning), PhD thesis, University of Massachusetts Amherst.
Andreae, J. 1963, ‘Stella: A Scheme for a Learning Machine’, IFAC Proceedings Volumes, vol. 1, no. 2, pp. 497–502, ISSN: 1474–6670, DOI: 10.1016/S1474–6670(17)69682–4.
Andreae, J. 1977, Thinking with the Teachable Machine, ISBN: Academic Press, London.
Andreae, J. & Cashin, P. 1969, ‘A Learning Machine with Monologue’, International Journal of Man-Machine Studies, vol. 1, no. 1, pp. 1–20, ISSN: 0020–7373, DOI: 10.1016/S0020–7373(69)80008–8.
Barto, A. & Sutton, R. 1981a, Goal Seeking Components for Adaptive Intelligence: An Initial Assessment.
Barto, A. & Sutton, R. 1981b, ‘Landmark Learning: An Illustration of Associative Search’, Biological Cybernetics, vol. 42, no. 1, pp. 1–8, ISSN: 0340–1200, DOI: 10.1007/BF00335152.
Barto, A. & Sutton, R. 1982, ‘Simulation of Anticipatory Responses in Classical Conditioning by a Neuron-Like Adaptive Element’, Behavioural Brain Research, vol. 4, no. 3, pp. 221–35, ISSN: 0166–4328, DOI: 10.1016/0166–4328(82)90001–8.
Barto, A., Sutton, R. & Anderson, C. 1983, ‘Neuronlike Adaptive Elements That Can Solve Difficult Learning Control Problems’, IEEE Transactions on Systems, Man, and Cybernetics, vol. SMC-13, no. 5, pp. 834–46, ISSN: 0018–9472, DOI: 10.1109/TSMC.1983.6313077.
Baxter, J., Tridgell, A. & Weaver, L. 2000, ‘Learning to Play Chess Using Temporal Differences’, Machine Learning, vol. 40, no. 3, p. 243, ISSN: 0885–6125, DOI: 10.1023/A:1007634325138.
Baxter, J., Tridgell, A. & Weaver, L. 2001, ‘Reinforcement Learning and Chess’, Machines That Learn to Play Games, pp. 91–116.
Bellman, R. 1957a, Dynamic Programming, ISBN: 069107951x, Princeton University Press.
Bellman, R. 1957b, ‘A Markovian Decision Process’, Journal of Mathematics and Mechanics, vol. 6, no. 5, pp. 679–84, ISSN: 00959057.
Berges, V., Rao, P. & Pryzant, R. nd, ‘Reinforcement Learning for Atari Breakout’, Stanford University, <https://cs.stanford.edu/~rpryzant/data/rl/paper.pdf>.
Borowiec, S. 2016, Alphago Seals 4–1 Victory over Go Grandmaster Lee Sedol, The Guardian, viewed 31/May/2020, <https://www.fbe.hku.hk/f/page/75261/Reading%201_AlphaGo%20seals%204-1%20Victory%20over%20Go%20Grandmaster%20Lee%20Sedol.pdf>.
Bouzy, B. 2006a, ‘Associating Shallow and Selective Global Tree Search with Monte Carlo for Go’, Computers and Games, vol. 3846, pp. 67–80, DOI: 10.1007/11674399_5, Springer Berlin Heidelberg, Berlin, Heidelberg.
Bouzy, B. 2006b, ‘Move-Pruning Techniques for Monte-Carlo Go’, Advances in Computer Games, vol. 4250, pp. 104–19, DOI: 10.1007/11922155_8.
Bouzy, B. & Helmstetter, B. 2004, ‘Monte-Carlo Go Developments’, Advances in Computer Games, pp. 159–74, Springer.
Bryson, A. 1996, ‘Optimal Control’, IEEE Control Systems, vol. 16, no. 3, pp. 26–33, ISSN: 1066–033X, DOI: 10.1109/37.506395.
Chahill, D. 2017, Why Reinforcement Learning Might Be the Best Ai Technique for Complex Industrial Systems, viewed 31/May/2020, <https://www.bons.ai/blog/ai-reinforcement-learning-strategy-industrial-systems>.
Chen, Y., Huang, A., Wang, Z., Antonoglou, I., Schrittwieser, J. & Silver, D. 2018, ‘Bayesian Optimization in Alphago’, arXiv.org, ISSN: 2331–8422, <https://arxiv.org/pdf/1812.06855.pdf>.
Clark, W. & Farley, B. 1955, ‘Generalization of Pattern Recognition in a Self-Organizing System’, Proceedings of the March 1–3, 1955, Western Joint Computer Conference, pp. 86–91, DOI: 10.1145/1455292.1455309, <https://dl.acm.org/doi/abs/10.1145/1455292.1455309>.
Coulom, R. 2007a, ‘Computing Elo Ratings of Move Patterns in the Game of Go’, Computer Games Workshop, <https://hal.inria.fr/inria-00149859/document>.
Coulom, R. 2007b, ‘Efficient Selectivity and Backup Operators in Monte-Carlo Tree Search’, in H. Herik, P. Ciancarini & H. Donkers. (eds.), Computers and Games, vol. 4630, pp. 72–83, Springer.
Dahl, F. 1999, ‘Honte, a Go-Playing Program Using Neural Nets’, Machines that learn to play games, pp. 205–23, <http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.50.2676&rep=rep1&type=pdf>.
Farley, B. & Clark, W. 1954, ‘Simulation of Self-Organizing Systems by Digital Computer’, Transactions of the IRE Professional Group on Information Theory, vol. 4, no. 4, pp. 76–84, ISSN: 2168–2690, DOI: 10.1109/TIT.1954.1057468.
Frye, C. 2019, The Dangers of Reinforcement Learning in the Real World, viewed 31/May/2020, <https://faculty.ai/blog/the-dangers-of-reinforcement-learning-in-the-real-world/>.
Fu, M. 2016, ‘Alphago and Monte Carlo Tree Search: The Simulation Optimization Perspective’, in 2016 Winter Simulation Conferences, IEEE, pp. 659–70, <https://doi-org.ezproxy.lib.uts.edu.au/10.1109/WSC.2016.7822130>.
Garychl 2018, Applications of Reinforcement Learning in Real World, viewed 31/May/2020, <https://towardsdatascience.com/applications-of-reinforcement-learning-in-real-world-1a94955bcd12>.
Gelly, S. & Silver, D. 2008, ‘Achieving Master Level Play in 9 X 9 Computer Go’, in AAAI, vol. 8, pp. 1537–40, <https://www.aaai.org/Papers/AAAI/2008/AAAI08-257.pdf>.
Gelly, S., Wang, Y., Munos, R. & Teytaud, O. 2006, Modification of Uct with Patterns in Monte-Carlo Go, <https://hal.inria.fr/inria-00117266v3/document>.
Godbout, C. 2018, The Bright Future of Reinforcement Learning, viewed 31/May/2020, <https://medium.com/apteo/the-bright-future-of-reinforcement-learning-a66173694f88>.
Hamilton, W. 1833, On a General Method of Expressing the Paths of Light, & of the Planets, by the Coefficients of a Characteristic Function, ISBN: Printed by P.D. Hardy.
Hamilton, W. 1834, On the Application to Dynamics of a General Mathematical Method Previously Applied to Optics, ISBN: Printed by P.D. Hardy.
Hammersley, J. 1964, Monte Carlo Methods, ISBN: Methuen, London.
Hausknecht, M., Lehman, J., Miikkulainen, R. & Stone, P. 2014, ‘A Neuroevolution Approach to General Atari Game Playing’, IEEE Transactions on Computational Intelligence and AI in Games, vol. 6, no. 4, pp. 355–66, ISSN: 1943–068X, DOI: 10.1109/TCIAIG.2013.2294713.
Howard, R. 1960, ‘Dynamic Programming and Markov Processes’.
Jacobi, K. 1866, Vorlesungen Über Dynamik Nebst Fünf Hinterlassenen Abhandlungen Desselben Herausgegeben Von A. Clebsch: Unter Beförderung Der Königlich Preussischen Akademie Der Wissenschaften.
Kaiser, L., Babaeizadeh, M., Milos, P., Osinski, B., Campbell, R., Czechowski, K., Erhan, D., Finn, C., Kozakowski, P., Levine, S., Mohiuddin, A., Sepassi, R., Tucker, G. & Michalewski, H. 2019, ‘Model-Based Reinforcement Learning for Atari’, in ICLR, arXiv.org, https://arxiv.org/pdf/1903.00374.pdf>.
King, D. 1997, ‘Kasparov Vs. Deeper Blue: The Ultimate Man Vs. Machine Challenge’, Machine Challenge, Trafalgar Square.
Kirschte, M. 2019, What to Expect from Reinforcement Learning?, viewed 31/May/2020, <https://towardsdatascience.com/what-to-expect-from-reinforcement-learning-a22e8c16f40c>.
Klopf, A. 1972, Brain Function and Adaptive Systems: A Heterostatic Theory.
Klopf, A. 1975, ‘A Comparison of Natural and Artificial Intelligence’, ACM SIGART Bulletin, no. 52, pp. 11–3, ISSN: 0163–5719, DOI: 10.1145/1045236.1045237.
Klopf, A. 1988, ‘A Neuronal Model of Classical Conditioning’, Psychobiology, vol. 16, no. 2, pp. 85–125, ISSN: 0889–6313, DOI: 10.3758/BF03333113.
Knight, W. 2017, The Dark Secret at the Heart of Ai, viewed 31/May/2020, <https://www.technologyreview.com/2017/04/11/5113/the-dark-secret-at-the-heart-of-ai/>.
Levy, S. 1997, ‘Man Vs. Machine’, Newsweek, vol. 129, no. 18, pp. 50–6, ISSN: 00289604.
Lorica, B. 2017, Practical Applications of Reinforcement Learning in Industry: An Overview of Commercial and Industrial Applications of Reinforcement Learning, viewed 31/May/2020, <https://www.oreilly.com/radar/practical-applications-of-reinforcement-learning-in-industry/>.
Minsky, M. 1954, Theory of Neural-Analog Reinforcement Systems and Its Application to the Brain-Model Problem, PhD thesis, Princeton University.
Minsky, M. 1961, ‘Steps toward Artificial Intelligence’, Proceedings of the IRE, vol. 49, no. 1, pp. 8–30, ISSN: 0096–8390, DOI: 10.1109/JRPROC.1961.287775.
Mnih, V., Kavukcuoglu, K., Silver, D., Graves, A., Antonoglou, I., Wierstra, D. & Riedmiller, M. 2013, ‘Playing Atari with Deep Reinforcement Learning’, ArXiv.org, <https://arxiv.org/pdf/1312.5602.pdf>.
Moyer, C. 2016, How Google’s Alphago Beat a Go World Champion, The Atlantic, viewed 31/May/2020, <https://www.theatlantic.com/technology/archive/2016/03/the-invisible-opponent/475611/>.
Newborn, M. 2000, ‘Deep Blue’s Contribution to Ai’, Annals of Mathematics and Artificial Intelligence, vol. 28, no. 1, pp. 27–30, ISSN: 1012–2443, DOI: 10.1023/A:1018939819265.
Patel, D., Hazan, H., Saunders, D., Siegelmann, H. & Kozma, R. 2019, ‘Improved Robustness of Reinforcement Learning Policies Upon Conversion to Spiking Neuronal Network Platforms Applied to Atari Breakout Game’, Neural Networks, vol. 120, pp. 108–15, ISSN: 0893–6080.
Rosenblatt, F. 1962, Principles of Neurodynamics: Perceptrons and the Theory of Brain Mechanisms, ISBN: Spartan Books, Washington, D.C.
Samuel, A. 1959, ‘Some Studies in Machine Learning Using the Game of Checkers’, IBM Journal of Research and Development, vol. 3, no. 3, pp. 210–29, ISSN: 0018–8646, DOI: 10.1147/rd.33.0210.
Santo, B. 1997, ‘IBM Tweaks Deep Blue for Man-Machine Rematch’, Electronic Engineering Times, no. 946, pp. 111–2, ISSN: 0192–1541.
Schraudolph, N., Dayan, P. & Sejnowski, T. 2001, ‘Learning to Evaluate Go Positions Via Temporal Difference Methods’, Computational Intelligence in Games, pp. 77–98, Springer, https://snl.salk.edu/~schraudo/pubs/SchDaySej01.pdf>.
Silver, D., Sutton, R. & Müller, M. 2008, ‘Sample-Based Learning and Search with Permanent and Transient Memories’, in International Conference on Machine Learning, pp. 968–75.
Sutton, R. 1978a, Learning Theory Support for a Single Channel Theory of the Brain, ISBN.
Sutton, R. 1978b, ‘Single Channel Theory: A Neuronal Theory of Learning’, Brain Theory Newsletter, vol. 3, no. 3, pp. 72–4.
Sutton, R. 1978c, A Unified Theory of Expectation in Classical and Instrumental Conditioning, ISBN.
Sutton, R. 1984, Temporal Credit Assignment in Reinforcement Learning, PhD thesis, ProQuest Dissertations Publishing.
Sutton, R. 1988, ‘Learning to Predict by the Methods of Temporal Differences’, Machine Learning, vol. 3, no. 1, pp. 9–44, ISSN: 0885–6125, DOI: 10.1023/A:1022633531479.
Sutton, R. & Barto, A. 1981a, ‘An Adaptive Network That Constructs and Uses an Internal Model of Its World’, Cognition and Brain Theory, vol. 4, no. 3, pp. 217–46.
Sutton, R. & Barto, A. 1981b, ‘Toward a Modern Theory of Adaptive Networks: Expectation and Prediction’, Psychological Review, vol. 88, no. 2, pp. 135–70, ISSN: 0033–295X, DOI: 10.1037/0033–295X.88.2.135.
Sutton, R. & Barto, A. 1987, ‘A Temporal-Difference Model of Classical Conditioning’, in Proceedings of the Ninth Annual Conference of the Cognitive Science Society, Seattle, WA, pp. 355–78.
Sutton, R. & Barto, A. 1990, ‘Time-Derivative Models of Pavlovian Reinforcement’, in M. Gabriel & J. Moore (eds.), Learning and Computational Neuroscience: Foundations of Adaptive Networks, pp. 497–537, The MIT Press, Cambridge, MA.
Sutton, R. & Barto, A. 2018, Reinforcement Learning: An Introduction, Second edn., ISBN: 9780262039246, The MIT Press, Cambridge, Massachusetts, <https://web.stanford.edu/class/psych209/Readings/SuttonBartoIPRLBook2ndEd.pdf>.
Szita, I. 2012, ‘Reinforcement Learning in Games’, in M. Wiering & M. van Otterlo (eds.), Reinforcement Learning: State-of-the-Art, pp. 539–77, DOI: 10.1007/978–3–642–27645–3_17, Springer Berlin Heidelberg, Berlin, Heidelberg, <https://doi.org/10.1007/978-3-642-27645-3_17>.
Tesauro, G. 1986, ‘Simple Neural Models of Classical Conditioning’, Biological Cybernetics, vol. 55, no. 2–3, pp. 187–200, ISSN: 0340–1200, DOI: 10.1007/BF00341933.
Tesauro, G. 1994, ‘Td-Gammon, a Self-Teaching Backgammon Program, Achieves Master-Level Play’, Neural computation, vol. 6, no. 2, pp. 215–9, ISSN: 0899–7667.
Thorndike, E. 1911, Animal Intelligence: Experimental Studies, ISBN: 9780765804822, The Macmillan Company.
Thrun, S. 1995, ‘Learning to Play the Game of Chess’, in Advances in Neural Information Processing Systems, pp. 1069–76, <http://papers.neurips.cc/paper/1007-learning-to-play-the-game-of-chess.pdf>.
TwoMinutePapers 2015, Google Deepmind’s Deep Q-Learning Playing Atari Breakout, viewed 31/May/2020, <https://www.youtube.com/watch?v=V1eYniJ0Rnk>.
Watkins, C. 1989, Learning from Delayed Rewards, PhD thesis, https://www.researchgate.net/publication/33784417_Learning_From_Delayed_Rewards>.
Werbos, P. 1987, ‘Building and Understanding Adaptive Systems: A Statistical/Numerical Approach to Factory Automation and Brain Research’, IEEE Transactions on Systems, Man, and Cybernetics, vol. 17, no. 1, pp. 7–20, ISSN: 0018–9472, DOI: 10.1109/TSMC.1987.289329, <https://www.aaai.org/Papers/Symposia/Fall/1993/FS-93-02/FS93-02-003.pdf>.
Wheeler, T. 2017, Alphago Zero — How and Why It Works, viewed 31/May/2020, <http://tim.hibal.org/blog/alpha-zero-how-and-why-it-works/>.
Widrow, B. & Hoff, M. 1960, ‘Adaptive Switching Circuits’, 1960 Wescon Convention Record Part Iv, pp. 94–104, MIT Press, Cambridge, MA.
Wikipedia 2020, Atari 2600, viewed 31/May/2020, <https://en.wikipedia.org/wiki/Atari_2600>.

{kind=link}