R-CNN (Object Detection)
A beginners guide to one of the most fundamental concepts in object detection.
When the paper “Rich feature hierarchies for accurate object detection and semantic segmentation” came out of UC Berkely in 2014 no one could have predicted its impact. After 5 years it now has nearly 9000 citations. In this paper, the authors introduced a fundamental concept for all modern object detection networks: Combining region proposals with CNN’s. They called this method R-CNN.
This will be the first entry in a 3 part series covering R-CNN, fast R-CNN and faster R-CNN. You will need to fully understand the intuition behind the concepts here to understand the following articles. Remember, knowing the fundamentals well is much more important than “half-knowing” modern state-of-the-art approaches.
R-CNN System
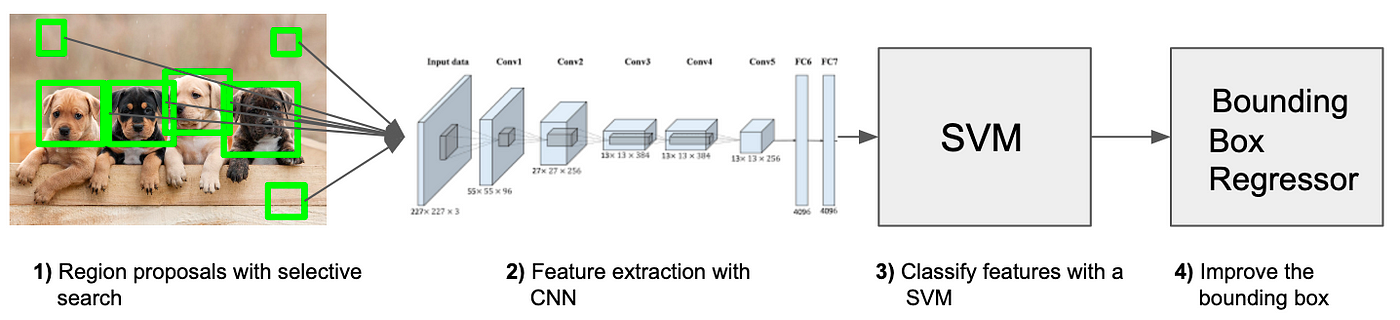
The problem the R-CNN system tries to solve it is to locate objects in an image (object detection). What do you do to solve this? You could start with a sliding window approach. When using this method you just go over the whole image with different sized rectangles and look at those smaller images in a brute-force-method. The problem is you will have a giant number of smaller images to look at. To our luck, other smart people developed algorithms to smartly choose those so-called region proposals. To simplify this concept:
Region proposals are just smaller parts of the original image, that we think could contain the objects we are searching for.
Region proposals
There are different region proposal algorithms we can choose from. These are “normal” algorithms that work out of the box. We don’t have to train them or anything. In the case of this paper, they use the selective search method to generate region proposals. I found a very good and detailed explanation on how, the algorithm works here. But keep in mind:
The R-CNN is agnostic to the region proposal method.
You can choose any method you like and it would work either way.
This will create nearly 2000 different regions we will have to look at. This sounds like a big number, but it’s still very small compared to the brute-force sliding window approach.
CNN
In the next step, we take each region proposal and we will create a feature vector representing this image in a much smaller dimension using a Convolutional Neural Network (CNN).

They use the AlexNet as a feature extractor. Don’t forget it’s 2014 and AlexNet is still kind of state-of-the-art (Oh, how times have changed…).
One question we need to answer:
If you only use the AlexNet as a feature extractor how do we train this thing?
Well, this is one fundamental issue with this R-CNN system. You can’t train the whole system in one go (This will be solved by the fast R-CNN system). Rather, you will need to train every part independently. That means that the AlexNet was trained before on a classification task. After the training, they removed the last softmax layer. Now the last layer is the fully connected 4096-dimensional one. This means that our features are 4096 dimensional.
Another important thing to keep in mind is that the input to the AlexNet is always the same (227, 227, 3). The image proposals have different shapes though. Many of them are smaller or larger than the required size. So we will need to resize every region proposal.
To summerize the task of the CNN:

SVM
We created feature vectors from the image proposals. Now we will need to classify those feature vectors. We want to detect what class of object those feature vectors represent. For this, we use an SVM classificator. We have one SVM for each object class and we use them all. This means that for one feature vector we have n outputs, where n is the number of different objects we want to detect. The output is a confidence score. How confident are we that this particular feature vector represents this class.
The thing that confused me when I read this paper for the first time, was how we trained those different SVM’s. Well, we train them on feature vectors created by the AlexNet. That means, that we have to wait until we fully trained the CNN before we can train the SVM. The training is not parallelizable. Because we know when training what feature vector represented which class we can easily train the different SVM’s in a supervised-learning way.
To summerize:
- We created different image proposals from one image.
- Then we created a feature vector from those proposals using the CNN.
- In the end we classified each feature vector with the SVM’s for each object class.
The output:
Now we have image proposals that are classified on every object class. How do we bring them all back to the image? We use something called greedy non-maximum suppression. This is a fancy word for the following concept:
We reject a region (image proposal) if it has an intersection-over-union (IoU) overlap with a higher scoring selected region.
We combine each region if there is an overlap we take the proposal with the higher score (calculated by the SVM). We do this step for each object class independently. After this ends we only keep regions with a score higher than 0.5.
Bounding Box Regressor (optional)
I want to mention the Bounding Box Regressor at the end because it is not a fundamental building block of the R-CNN System. It’s a greate idea though and the authors found that it improves the average precision by 3%. So how does it work?
When you are training the Bounding Box Regressor your input is the center, width and height in pixels of the region proposal and the label is the ground truth bounding box. The goal as stated in the paper is:
Our goal is to learn a transformation that maps a proposed box P to a ground-truth box G.
Conclusion
Another interesting discovery made in this paper is that it was highly effective to pre-train the CNN on a task with a lot of data (for example image classification) and after that to fine tune the network for the actual task, which was the object detection.
I really believe that it is necessary to fully understand the concepts presented in this paper to fully grasp more modern approaches in object detection. I hope this article helped you understand those ideas and more importantly helped you get an intuition about the different parts in the R-CNN system. The next part of this series will be about fast R-CNN which builds up directly on top of R-CNN system.
Thank you for reading and keep up the learning!
If you want more and stay up to date you can find me here:
