NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
ECCV-2020 Oral Paper Review
Rendering 3D models from 2D images is a challenging problem in the computer vision area. Even though we have camera position supervision for each image, previous 3D rendering models are not sufficient to use in practice. NeRF, which is selected as an oral paper in ECCV, proposed a state-of-the-art method that constructs a 3D model with 2D images and their corresponding camera positions.
Terminologies
- Ray: Line connected from a camera center, determined by camera position parameters, in a particular direction, determined by camera angle parameters.
- Color: RGB value that each 3D volume has.
- Volume Density: Determines how much it is affecting the final color determination.
- Ray Color: RGB values that we can observe when we are following the ray. The formal definition is in Equation 1.
What is NeRF?
NeRF is the first paper that introduces neural scene representation. It is advantageous for rendering high-resolution photorealistic novel views of real objects. This paper’s key idea is to predict the color values and the opacity values along the ray, which is determined by five extrinsic camera parameters (3 camera positions, two camera angles).
Eventually, with estimated colors and opacities, NeRF determines a ray’s expected color (Equation 1). For practical implementation, NeRF approximates integral to a finite sum(Equation 2), called stratified sampling. The number of samples is 64, 128, 256 in the experiments.


NeRF architecture doesn’t need to conserve each feature; thus, NeRF is composed of MLP rather than CNN. It also uses two techniques to improve its performance: positional encoding and hierarchical volume sampling.
Positional Encoding
Rather than using five naive camera parameters, NeRF uses positional encoding, which is often used in NLP(Natural Language Processing). Using naive input often performs poorly at high-frequency variation in color and geometry. Positional encoding facilitates the network to optimize the parameters by mapping input to higher-dimensional space easily. NeRF showed that using a high-frequency function for mapping original input enables better fitting of data that contains high-frequency variation. The ablation study is evidence for this argument(Table 1).

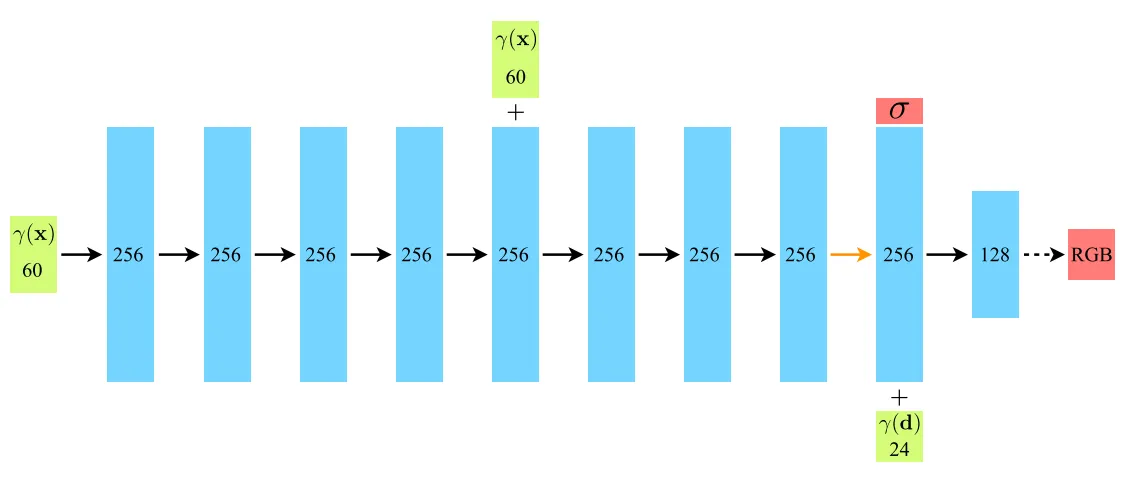

Hierarchical Volume Sampling
NeRF proposes a hierarchical structure. The overall network architecture is composed of two networks: the coarse network and the fine network.
The coarse network uses N_c sample points to evaluate the expected color of a ray. As its name reveals, it first optimizes from the coarse sampling. Equation 4 is the formal definition of the coarse network.

The fine network uses N_c + N_f = N sample points to evaluate a ray’s expected color. The equation for this is the same as Equation 2. Table 2 shows an ablation study about the effect of hierarchical structure. However, in my humble opinion, it is not a fair comparison between (4) and (7) in Table 2. It is because N_c + N_f is not the same between (4) and (7). If the N_f value in (4) is 192(=128 + 64), it might be a more fair comparison.

Loss Function
The ultimate goal of this network is to predict the expected color value for the ray correctly. Since we can estimate the ground truth ray color with the ground truth 3D model, we can use L2-distance with the RGB values as a loss. Fortunately, every step is differentiable; thus, we can optimize the network by the predicted RGB value of rays.
The authors designed the loss function to achieve two goals.
- Well optimizes the coarse network.
- Well optimizes the fine network.

Result
- Evaluation Metric
PSNR(Peak Signal-to-Noise Ratio): higher PSNR, lower MSE. Lower MSE implies less difference between the ground truth image and the rendered image. Thus, higher PSNR, the better model.
SSIM(Structural Similarity Index): Checks the structural similarity with the ground truth image model. Higher SSIM, the better model.
LPIPS(Learned Perceptual Image Patch Similarity): Determines the similarity with the view of perception; using VGGNet. Lower LPIPS, the better model.
- Experiment Result (Quantitative Result)

NeRF achieved state-of-the-art performance for all tasks.
- Visualization (Qualitative Result)

- NeRF also solved the view-dependency problem that models have different colors depending on the view. As shown in Figure 3, NeRF architecture automatically learns view-dependent color value, unlike other models.

Conclusion
NeRF demonstrated that representing scenes as 5D neural radiance fields produces better renderings than the previously-dominant approach of training deep convolutional networks to output discretized voxel representations. The authors expect that the NeRF model can be further optimized with different structures. Moreover, the interpretability of NeRF is inferior to the previous approaches, such as voxel and mesh.
Paper Link: https://arxiv.org/abs/2003.08934
Official NeRF Link: https://www.matthewtancik.com/nerf
Feel free to contact me! “ jeongyw12382@postech.ac.kr”
