How to Annotate PDFs and Scanned Images with UBIAI
Leveraging OCR technology

Introduction
Whether it’s receipts, contracts, financial documents, or invoices etc., automating information retrieval will help you increase your business efficiency and productivity at a fraction of the cost. However, this amazing feat will not be possible without text annotation. While NLP tasks such as NER or relation extraction have been widely used for information retrieval in unstructured text, analyzing structured documents such as invoices, receipts, and contracts is a more complicated endeavor.
First, there is not much semantic context around the entities we want to extract (i.e. price, seller, tax, etc.) that can be used to train an NLP model. Second, the document layout changes frequently from one invoice to another; this will cause traditional NLP task such as NER to perform poorly on structured documents. That being said, structured text – such as an invoice – contain rich spatial information about the entities. This spatial information can be used to create a 2-D position embedding that denotes the relative position of a token within a document. More recently, Microsoft released a new model LayoutLM to jointly model interactions between text and layout information across scanned document images. They achieved new state-of-the-art results in several downstream tasks, including form understanding (from 70.72 to 79.27), receipt understanding (from 94.02 to 95.24) and document image classification (from 93.07 to 94.42).

Scanned Images and PDF annotation
In order to fine-tune the layoutLM model for custom invoices, we need to provide the model with annotated data that contains the bounding box coordinates of each token as well as the linking between the tokens (see tutorial here for fine-tuning on FUNSD data):
{
"box": [76,129,118,139],"text": "Brand:","label": "question","words": [{"box": [76,129,118,139],"text": "Brand:"}],"linking": [[0,2]],"id": 0}]}Because most receipts and invoices are in scanned or PDF format, we need to find an annotation tool that is capable of Ocr parsing and annotation directly on native PDFs and images. Unfortunately, most annotation tools that support OCR annotation are either exorbitantly expensive or incomplete where you have to externally perform the OCR step prior to annotation.
That is why at UBIAI, we have developed an end-to-end solution to annotate directly on native PDFs, scanned images, or images from your phone without losing any of the document layout information. This is useful for invoice extraction where text sequence and spatial information are equally important. All you have to do is to upload your PDF, JPG, or PNG directly and start to annotate. Using the state of the art OCR technology from AWS Textract, UBIAI will parse your document and extract all the tokens with their bounding box. Simply highlight the token on the original document (right panel) or the parsed text (left panel) and assign a label. In addition to entity labeling, you can also perform relations annotation and document classification labeling.
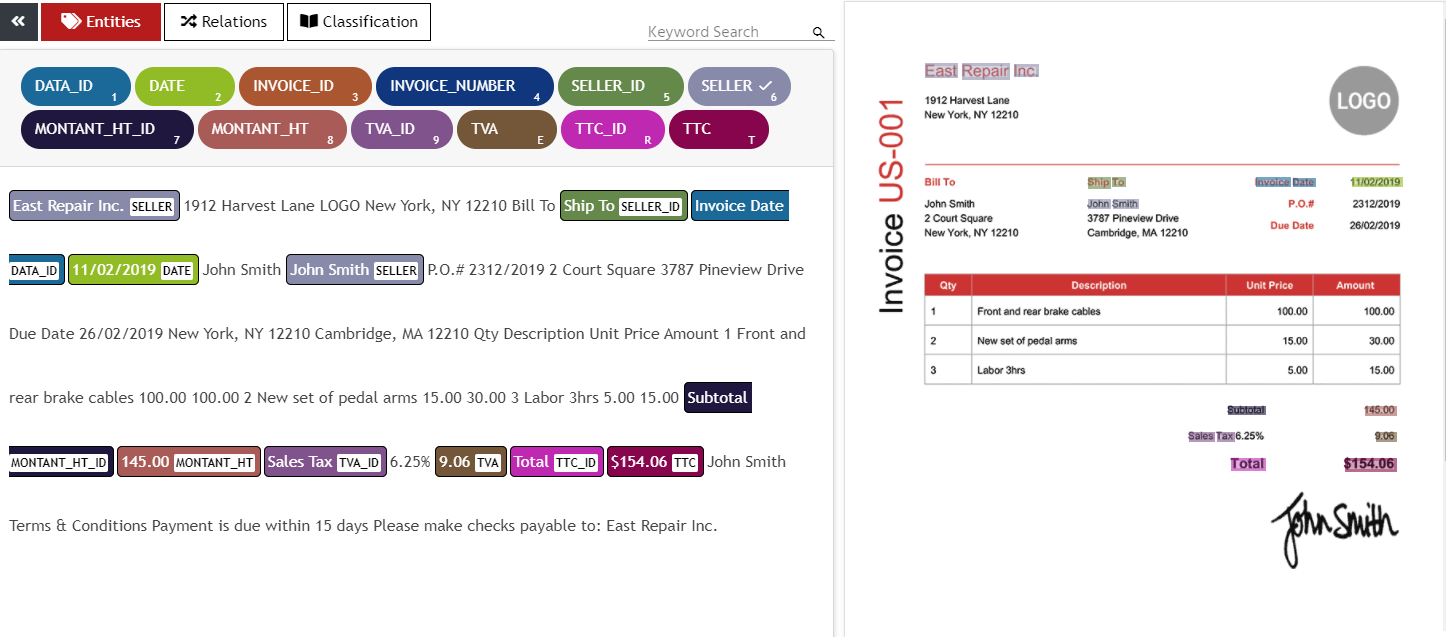
Annotating multi-words is also easy. Simply create a frame around the words you want to select and they will get automatically annotated (see below).

Invoice Pre-annotation
In addition, you can pre-annotate your invoices using dictionaries, regular expressions (for example to find dates, emails, names, etc.) or a pre-trained ML model.


Annotation Export
Once you finish the annotation, simply export the annotated documents in JSON format:

Conclusion
UBIAI’s OCR annotation allows you to train NLP models with less friction by providing an easy-to-use and accurate labeling interface. You do not have to worry about pre-processing your images using external APIs or adding rules to pre-annotate your documents. Simply upload your documents, annotate, and export. In the next part, we will show how to fine tune the layoutLM model on your own dataset for invoice recognition, stay tuned!
If you are looking to train an NLP model for your structured text, check us out at https://ubiai.tools or send us an email at admin@ubiai.tools to schedule a demo!
Follow us on Twitter @UBIAI5








