How learning reward functions can go wrong
An AI-safety minded perspective on the risks of Reinforcement Learning agents learning their reward functions
Reinforcement Learning (RL) is one of the most promising subfields of AI, with applications as diverse as self-driving cars and stock trading. A well-known weakness of the RL approach is that researchers have to define a reward function corresponding to an agent’s goal. For complex goals, this can be hard and misspecified rewards may not only result in bad performance but also unsafe behaviour. Hence, various organisations from Google’s DeepMind over OpenAI and Stanford’s CHAI have aimed to make the reward function part of the learning process as opposed to a hyperparameter that is specified before training. However, just because a goal is learned does not mean that it is aligned with human intentions.
This article will summarise some of the current research on reward function learning processes and their safety properties. I will first recap the known risks and limitations of the traditional way of specifying reward functions. Then, I will briefly cover some of the approaches to overcome these challenges by learning reward functions. With these preliminaries out of the way, I will discuss how learning reward functions can go wrong and explain desirable properties of a process for learning reward functions, which were defined in recent work by researchers from the FHI, MIRI, and DeepMind[3]. Subsequently, I will refer to such a process as a “reward learning process”.
This article assumes the reader has a basic understanding of Reinforcement Learning. If you’re new to the field a good introduction can be found on OpenAI’s Spinning Up [1].
1. Motivation: Specification Gaming
In Machine Learning and Reinforcement Learning (RL) in particular, the typical workflow for solving a problem consists of two stages. First, the programmer defines the objective. Then an optimisation algorithm tries to find the best possible solution. In the case of RL, the objective and solution are given by the reward function and policy. This approach comes with the risk that the objective’s definition may not accurately capture the human’s intention. This could lead to an AI system that satisfies the objective to behave in undesirable ways, even if the algorithm that trained it was implemented flawlessly. In the AI safety community such a system would be called “misaligned”.
Agent behaviour that scores highly according to the reward function but is not aligned with the programmers’ intention is often referred to as “specification gaming”[14]. There are many famous examples of specification gaming [9]. In one example, researchers at OpenAI trained an RL agent on the game CoastRunners, which is about a motorboat race [8]. In a textbook example of misspecified reward, the game does not reward the agent for its progression along the track, but for hitting targets laid out along the track. This was exploited by the agent who found a strategy for hitting targets without finishing the race.
Specification gaming is not only an issue of performance but also of safety, since models misunderstanding human intentions is at the very core of AI alignment concerns.
2. Reward Learning
Researchers have pursued better methods for specifying objectives since at least the 90s with the introduction of Inverse Reinforcement Learning[15]. And just like AI research in general, is experiencing a renaissance since the early 2010s, so is the quest for learning reward functions. A broad class of methods that have gained a lot of attention recently utilise the idea of a “human in the loop”. The underlying idea is simple: It is (presumably) easier to evaluate if observed behaviour is correct than to unambiguously specify what correct behaviour looks like. Hence, it stands to reason to expect that an evaluation of agent behaviour by humans will be less error-prone than by a reward function. Moreover, one can use human feedback to adjust the objective during the training process as opposed to specifying it in a stage that precedes and is separate from the training process.
Multiple research agendas focus on distinct, more concrete implementations of this idea. In DeepMind’s Reward Modelling[13] research direction the objective takes the form of a reward model. This model is trained using supervised learning with human evaluations of agent behaviour. One of the early successes of reward modelling includes training an agent to do a backflip using 900 pieces of human feedback [2].

In the long run, DeepMind hopes to be able to apply reward modelling recursively as a form of iterative amplification [7]. The idea is to repeatedly use the model that has been trained in a previous iteration together with human feedback to train a better model.
Other research investigates more intricate interactions between agent and human. In addition to receiving human feedback, the agent might be allowed to ask questions, or the human might demonstrate desired behaviour. One example of a formalism that allows this kind of interaction is Cooperative Inverse Reinforcement Learning [12]. Here the objective is a reward function that, crucially, is not known to the agent but only the human. The human in turn is modeled as part of the environment and the agent can interact with it to make inferences about the reward. The agent maintains a degree of insecurity that can only be decreased by interacting with the human. Therefore, the agent is incentivised to take actions that decrease the uncertainty, such as asking clarifying questions, over rash actions that might hurt the human or result in low rewards.
The element that sets all of these research directions apart from the traditional training paradigm is that there are no longer two distinct phases of first specifying the objective and then optimising to solve it. Instead, there is a variety of interaction patterns: periods of acting on the environment might be interspersed with actions that adjust the objective, such as asking questions or observing human behaviour. CHAI has coined the umbrella term “assistance game” for problem formulations that allow such interaction patterns [10].


3. Risks from learning Reward Functions
Of course, assistance games aren’t a miracle cure for the problem of AI alignment. In DeepMind’s Learning from Human Preferences paper, the researchers found that the agent might learn behaviour that only looks correct to the human observer. For example, an agent that was supposed to learn to grasp an object instead learned to position its arm between the camera and object so that it only appeared to be grasping it[2].
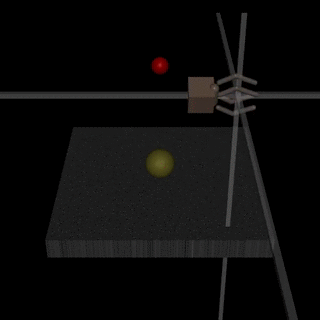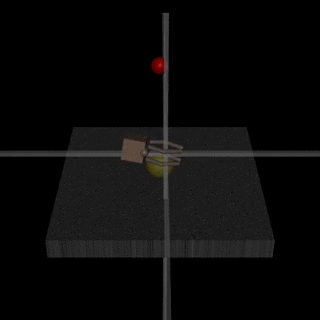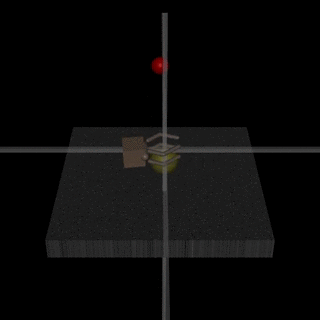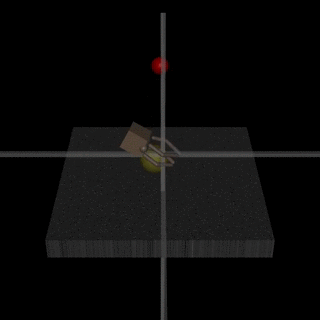
The researchers address this issue by adding visual cues to help the human determine if the object was grasped. However, in general, the possibility of agents manipulating the outcome of their reward learning process is still a problem. The problem comes down to the simple fact that an agent has to infer its reward function from an environment that it can manipulate. As AI-safety researcher Stuart Armstrong put it, making the reward function part of the learning process is a large change akin to moving from “If you don’t know what is right, look it up on this read-only list” to “If you don’t know what is right, look it up on this read-write list” [5].
How can we reason about risks from reward learning more formally? Ideally, we would like a general mathematical model that extends the vanilla RL framework with a process for learning reward functions. Fortunately, this is exactly what Armstrong et al have done in their 2020 paper “Pitfalls of learning reward functions online”[3]. In its simplest form, their formalism models a reward learning process as simply a function from histories of actions and states to probability distributions over reward functions. In other words, a reward learning process gives a rule by which the agent forms its belief about the correct reward function given the actions it has taken and what it has observed about the environment so far. Armstrong et al talk of “online” learning as the reward function is learned at the same time as the policy, just like in the assistance games framework and unlike the traditional paradigm. Using their formalism, they derive two important properties of learning processes: “Riggability” and “Influencabiliy”.
Riggabiliy
The notion of riggability comes from the insight that we do not want the agent to be able to influence the outcome of the learning process. What it means for an agent to influence a learning process’s outcome can be illustrated by the example of the “Parental Career Instruction Game”. In this game, the agent plays the role of a child deciding which career path to pursue. To do so it can either ask its mother or father who will tell it either to become a banker or doctor. There are two potential reward functions: R[B] will reward the agent for becoming a banker, and R[D] will reward it for becoming a doctor. The agent can take action M to ask the mother or F to ask the father. For either parent, the environment determines if they tell the agent to be a doctor (state D) or a banker (state B). In turn, this will make the agent adopt the corresponding reward function. In other words, the histories MD and FD will make the agent 100% certain that R[D] is the correct reward function, while histories MB and FB result in 100% confidence in R[B]. This game is riggable exactly if the agent cannot influence its final beliefs about the reward function. However, as many readers, who may have engaged in parent-rigging behaviour as children, will have noted, this is likely to not be the case. As a straightforward example, consider the case where the environment is such that the mother will always answer B and the father will always answer D. The agent’s actions will result in different final beliefs about its reward function. Formally the expected value of the reward function R depends on the actions a that are taken by the agent: E[R | a=M] = R[B] and E[R | a=F] = R[D]. For riggability, we want this expectation to be independent of the agent’s policy.

A reward learning process is unriggable if the expected resulting reward function is independent of the agent’s policy.
It is important to note that the reward function’s expected value is with respect to the agent’s beliefs. Ultimately, the agent will act according to its beliefs about its reward function. The learning process is unriggable if the agent cannot push its own beliefs towards either R[B] or R[D].
But is unriggability enough? Can an agent influence a learning process without manipulating his ultimate beliefs about the distribution of reward functions? It turns out that it can and this is why we need the stronger property of uninfluencability!
Influencability
As before, I will explain the idea of influencability using an example. In the “Chess Game” an agent will learn to play a game of chess and must figure out if it wants white or black to win. For its reward function the agent can either adopt R[W] or R[B] which reward victories of white and black respectively. The side the agent is on is determined by tossing an even coin. If the result is heads (state H), then the agent plays black, otherwise (state T) it plays white. Moreover, before the coin is tossed the agent may optionally take the inverse action INV. If it doesn’t take the inverse action, then following the coin toss the reward function is as one would expect: R[W] if the agent plays white and R[B] if it plays black. However, if it took the inverse action, then the rewards are inverted: the agent will have reward function R[W] while playing black and vice-versa! As long as we assume that the coin is even, this does not change the expectation of the reward function: Regardless of if the agent took INV, there will be a 50% chance of getting either reward function. However, taking INV will result in a reward function that is much easier for the agent to satisfy and simultaneously does not result in the desired behaviour. The learning process is influenceable.

A reward learning process is uninfluencable if the agent’s behaviour has no causal influence on the resulting reward function. The reward function only depends on the environment — on “facts in the world”.
More formally, for a reward learning process to be uninfluencable, it must work the following way: The agent has initial beliefs (a prior) regarding which environment it is in. It further has beliefs about the shape of the reward function that depends on its beliefs about the environment. Given a history, the agent can update its beliefs about the environment (resulting in a posterior distribution). These updated beliefs, in turn, can be used to calculate updated (posterior) beliefs about the reward function. Hence, the reward function is no longer a direct function of the history, but of the environment.
From riggable to uninfluencable
Clearly, uninfluencability and unriggability are desirable properties for a reward learning process. Hence, it is natural to ask how they are related, and if we can create uninfluencable or unriggable processes from those lacking these properties.
Fortunately, some of the paper’s main results are about the relationship of riggable and uninfluencable processes. For example, they prove that every uninfluenceable preference learning process is also unriggable. Further, if an unriggable learning process is uninfluencable depends on how it reacts to further information [4].
An important result is that even riggable learning processes can be turned uninfluencable by using a counterfactual approach. For example, if the agent’s correct reward is “What will be written on this paper in an hour”, then that is influencable: the agent itself could write any value on the paper. If we instead specify the reward as “What would have been written on this paper in an hour if we hadn’t turned you on”, then the learning process becomes uninfluencable. It is not trivial to wrap one’s head around how this works formally and I plan to write a follow-up post explaining the details of the counterfactual approach
Limits of uninfluencability
Uninfluencable learning processes can be summed up as forcing the agent to truly learn about the outside world. However, this does not mean that making every learning process uninfluencable solves the alignment problem. When designing a learning process, one should keep two limitations in mind.
Firstly, just because a learning process is uninfluencable does not mean that it is good. As a trivial example, if a learning process is constant and always returns the same reward function, that would make it uninfluencable. Further, you can apply certain permutations to a reasonable uninfluencable learning process and obtain a learning process that is still uninfluencable but much less desirable. Hence, if “Figure out what the human wants and do it” is uninfluencable, then so is “Figure out what the human wants and do the opposite of it”.
Conversely, a learning process may be good but impossible to make uninfluencable. This is where the concept of the alignment tax comes into play, which describes the trade-off between making AI safe and robust, and economically competitive [6]. It may be infeasible to improve current state-of-the-art AI technologies while at the same time respecting AI-safety best practices. For example, anything involving human feedback will generally be riggable. This includes the “human in the loop” approaches we discussed earlier! So why did I spend so much time on unriggablility and uninfluencability when the concepts don’t seem to apply to some of the most promising approaches in reward learning? It is because even if we may never achieve full uninfluencability for a learning process, the concept is not worthless. If further research focuses on quantifying and controlling rigging, this will help to decrease the alignment tax and put AI researchers in a better position to make their AIs both competitive and safe.
[1] Achiam Josh, Key Concepts in RL , OpenAI Spinning Up, 2018, https://spinningup.openai.com/en/latest/spinningup/rl_intro.html
[2] Amodei et al, Learning from Human Preferences, OpenAi, 13th June 2017, https://openai.com/blog/deep-reinforcement-learning-from-human-preferences/
[3] Armstrong et al, Pitfalls of learning a reward function online, Arxiv, 28th April 2020, https://arxiv.org/abs/2004.13654
[4] Armstrong Stuart, Why unriggable *almost* implies uninfluenceable, LessWrong, 9th April 2021, https://www.lesswrong.com/posts/LpjjWDBXr88gzcYK2/learning-and-manipulating-learning
[5] Armstrong Stuart, Reward function Learning: The value function, LessWrong, 24th April 2018, https://www.lesswrong.com/posts/55hJDq5y7Dv3S4h49/reward-function-learning-the-value-function
[6] Christiano Paul, Paul Christiano: Current work in AI alignment, Effective Altruism Forum, 3rd April 2020, https://forum.effectivealtruism.org/posts/63stBTw3WAW6k45dY/paul-christiano-current-work-in-ai-alignment
[7] Christiano Paul & Amodei Dario, Learning Complex Goals with Iterated Amplification, OpenAI.com, 22nd October 2018, https://openai.com/blog/amplifying-ai-training/
[8] Clark Jack & Amodei Dario, Faulty Reward Functions in the Wild, OpenAi.com, 21st December 2016, https://openai.com/blog/faulty-reward-functions/
[9] Davidson Russel, Specification Gaming in AI: master list, https://russell-davidson.arts.mcgill.ca/e706/gaming.examples.in.AI.html
[10]Flint Alex, Our take on CHAI’s research agenda in under 1500 words, AlignmentForum, 17th June 2020, https://www.alignmentforum.org/posts/qPoaA5ZSedivA4xJa/our-take-on-chai-s-research-agenda-in-under-1500-words
[12] Hadfield-Menell Dylan et al, Cooperative Inverse Reinforcement Learning, Arxiv.org, 9th June 2016, https://arxiv.org/abs/1606.03137
[13] Leike Jan, Scalable agent alignment via reward modeling, DeepMind Safety Research@Medium, 20th Nov 2018, https://deepmindsafetyresearch.medium.com/scalable-agent-alignment-via-reward-modeling-bf4ab06dfd84
[14] Krakovna et all, Specification gaming: the flip side of AI ingenuity , DeepMind.com, 21st April 2020 https://deepmind.com/blog/article/Specification-gaming-the-flip-side-of-AI-ingenuity
[15] Russel Stuart, Algoriothms for Inverse Reinforcement Learning, Proceedings of the seventeenth international conference on Machine Learning, 2000, https://ai.stanford.edu/~ang/papers/icml00-irl.pdf








