How I apply Continuous Integration to Machine Learning Projects
CI is highly useful in software projects, and can offer benefits to ML projects, too.
Introduction
Continuous Integration(CI) has proven to be a wonderful practice in software development. However, when it comes to Machine Learning(ML) projects, CI hasn’t been applied(or even mentioned) as much due to the different nature of the work.
From my experience, CI is highly useful in software projects and I’m certain that it could offer benefits to ML projects too. So, I’ve experimented with building a simple CI workflow for an ML project using open-source tools. In this post, I’m going to share the how it looks like and how I do it.
What is Continuous Integration?
Continuous Integration and Delivery(CI/CD) is a software development practice where software developers who work on the same code base integrate the code to main branch and deliver their product regularly so that the change made to the system is more manageable. CI/CD has become the heart of software product development because, if done appropriately, it ensures software quality and improves productivity in a sustainable way. Moreover, CI/CD also gets along well with Agile methodology which makes it even more popular in the software industry.
The workflow of CI/CD starts with a developer modifying the code on his local environment until it meets the acceptance criteria. Then, he has to ensure that the change he made doesn’t break the existing functionalities by running the tests. Once passed, developer will submit the new code to the CI/CD servers which will re-run the tests again on a neutral environment to ensure reproducibility. If everything’s alright, the new code will be merged to the main branch so the new version is available for others who contribute to the same project as well as to deliver if needed.

CI/CD challenges in Machine Learning projects
Machine Learning adoption has grown rapidly in the past few years. Usually, this is done by embedding an ML model into an application or a data pipeline that is a part of the system. This trend brings a new challenge to CI/CD because, unlike traditional software, ML applications do not only impact by a change in the code but also the data on which the model is trained.
Another key challenge is regarding quality control. In software projects, the unit/integration/regression tests ensure whether a change is safe to be integrated and delivered. If all tests are passed, it does, otherwise, it doesn’t. This isn’t suitable with an ML model due to several reasons. First, the mapping between input and output can be dynamic as some types of ML models have a non-deterministic behavior. Second, the input of ML models could be in an extremely complicated format such as a high-dimensional vector or an image. Generating the input like the way developers normally do when they write tests will be very inefficient and exhausting(if possible).
Building CI workflow for ML projects
Prerequisites
There are 2 key challenges mentioned in the previous section that has to be addressed. For data versioning, there are open-source tools available that can be used to solve the problem out-of-the-box. The one I chose is called Data Version Control(DVC) mainly because its functionalities are available through a command-line interface, no code needed. Plus, DVC is designed to work with Git intuitively and also offers other nice-to-have features such as ML pipeline.
The quality control is trickier because it isn’t a passed-or-failed question anymore. Two ML models can give a prediction on the same data, the question is which one is better(and by how much). Performance metrics such as accuracy, loss, and R-score seem to be more appropriate criteria.
Development team responsibility
Using evaluation metrics instead of tests both solves and creates a problem simultaneously. On one hand, it makes the criteria more appropriate. On the other hand, the right metrics are problem-specific and only the development team can select them. Therefore, it cannot be standardized.
The new responsibility has to be added to the development team to circumvent this issue. Since evaluation metrics are going to be used as a quality gate, the ML pipeline has to produce not only the model but also the performance report too. Moreover, the report should follow a pre-defined convention so it’s comparable across branches. For example, it has to be in JSON format under the folder named model with the file name of performance.jsonlike follow.
{
"accuracy": 0.9219429016113281,
"precision": 0.9634803263573233,
"recall": 0.9050901747682986,
"iou": 0.8753447772456544
}This way the team has the freedom to choose the right metrics for their application as well as increases the transparency in the process by adding a little extra work into their ML pipeline.
Workflow
Combining everything together, the designed workflow is as follows:
- Developer branches out from main.
- Developer makes changes and runs experiments on a local machine(or a remote server) until get the desired result.
- Developer creates a PR targeting the main branch.
- CI server re-runs the experiment branch to ensure reproducibility.
- CI server compares the performance metrics with the main branch and reports back to the PR page on GitHub so other members can review it.
- If approved, the code is then merged to main.
- CI server reruns the experiment again but this time the model is pushed to the remote storage for future deployment as well as a performance report for comparison.

Implementation
The workflow is implemented with GitHub Actions. It contains 2 key stages as follows:
Experiment reproducing
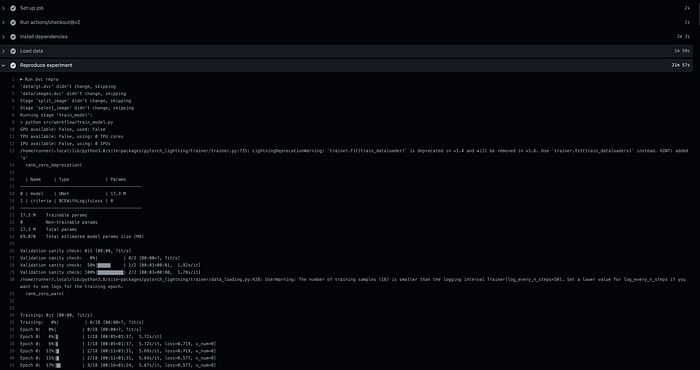
Reproducibility works consist of checking out the dataset and running the whole ML pipeline(pre-processing, training, and evaluation). These are done using 2 DVC commands: dvc pull and dvc repro.dvc pull downloads data from the configured remote storage(Google Drive in this example, but it works with all major cloud storage services), all you have to do is provide the credentials as an environment variable through the repository secrets. dvc repro runs the ML pipeline and outputs trained model and performance report(In a simple project, this might be equivalent to running train.pyscript) This is how it looks like in GitHub Actions:
Report generation
The report should show the performance comparison between the main and experiment branches so the reviewer can see how the change impacts the model. DVC provides this functionality through dvc metrics diff where you can compare metrics of the current change to any public branch. The output is in a human-readable format like this:
This output is saved to a file and made visible on the PR page using Create or Update Comment action on GitHub Actions Marketplace.
If you’re interested, the full GitHub Actions configuration is available here. The figures below show what the workflow looks like when the PR is created:


Conclusion
ML projects are like a new type of animal in the software industry. Applying CI/CD to them presents different challenges from traditional software projects, thus it requires a different approach. The method proposed in this article presents one way of applying CI/CD to data science. However, it is far from perfect and has a lot of room for improvement. Despite that, it still illustrates how useful CI/CD could be for ML works.
