Dissecting Stockfish Part 2: In-Depth Look at a chess engine
When neural networks meet hardcoded knowledge

The first part of this series demonstrates how Stockfish abstracts a chess position and how it quickly finds every possible move. Now, the engine must evaluate the quality of a move in order to pick the best one.
In the past, Stockfish only relied on a set of fixed rules that are algorithmic translations of chess concepts: tempo, material, space… But in 2018, neural networks made their way into many chess engines and Stockfish was outperformed. In order to fill the gap, Stockfish 12 integrated a neural network which took precedence over classical evaluation when the latter was known to be less performant, typically in balanced closed positions.
This article will focus first on the inner workings of the neural part and study the classical evaluation methods in a second time.
Neural network architecture
The neural evaluation function is based on Yu Nasu’s NNUE architecture (Efficiently Updatable Neural-Network-based Evaluation Functions for Computer Shogi, Yu Nasu, 2018). This tiny neural network evaluates a game position on a CPU without the need of a graphic processor: Stockfish can still be integrated easily on a lot of devices and tweaked by its large base of contributors.
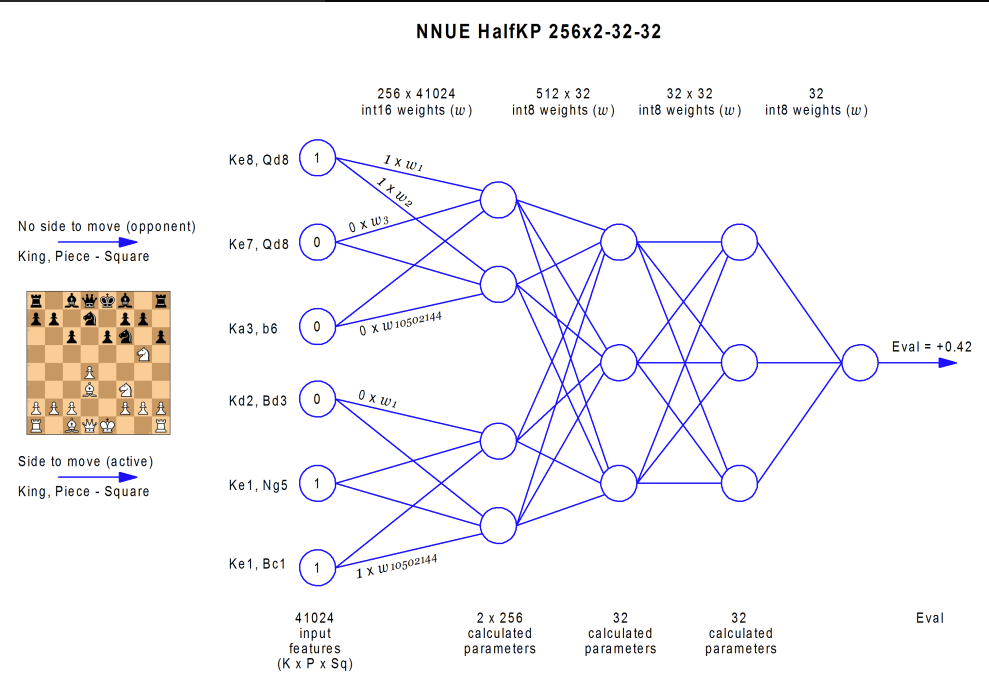
Input encoding
NNUE does not understand bitboards and the position has to be encoded first. The input parameters of NNUE represent the following boolean value, iterated for every W, X, Y and Z:
Is a king on a square X with a W[friendly|enemy] piece Y on square Z ?
That makes up to 40,960 parameters. Using this binary encoding instead of a simple “Is piece X on square Y?” encoding (768 parameters) has several benefits:
- Updating the inputs and subsequent neurons after a change in a position is quicker because this encoding allows incremental calculation, which is the strength of NNUE;
- Changing player’s turn is also quicker as the inputs simply need to be flipped;
- Providing more information than needed in the encoding is called overspecialization, and allows to input more knowledge to the network in order to decrease its training cost.
Hidden layers and training
The goal of the network is to build an evaluation function which is a combination of the neurons from the different layers separated by non-linearities. This evaluation function will be optimized (training phase) in respect to the weight of its neurons, in order to output the most accurate evaluation when given known chess games.
The basic idea for NNUE’s training is to build a huge input dataset of randomly generated positions which are evaluated at a low depth with classical Stockfish. The network is trained using this dataset, and can be then fine-tuned using specific positions and evaluations. In itself, the network is simple as it is made of 3 fully connected layers plus an output layer which can be expressed as material score.
However, what makes NNUE really unique are both its input encoding and its incremental calculation optimized for CPU evaluation.

Classical Evaluation
Apart from very balanced positions, Stockfish still relies on classical evaluation.
The idea is to build an evaluation function as a combination of chess concepts, made of several criterias which are weighted and added altogether. This function can then be scaled in order to express a material advantage in standard pawn units.

The concepts and associated criterias are the following:
- Material imbalance: count of pieces for every player
- Positional advantage: having specific pieces on specific squares
- Material advantage: strength of every piece, having a bishop pair
- Strategical advantage for pawns: doubled pawns, isolated pawns, connected pawns, pawns supported by pieces, attacked pawns
- Strategical advantage for other pieces: pieces blocked, pieces on good outposts, bishop X-ray attacks, bishops on long diagonals, trapped pieces, exposed queen, infiltrated queen, rooks on open files, rooks and queen batteries, enemy king attacked
- Incoming threats: attacked pieces, hanging pieces, king threats, pawn push threats, discovered/slider attack threats, squares where your pieces could move but would get exchanged, weakly protected pieces
- Passed pawns: blocked or unblocked passed pawns
- Space: squares controlled by all of your pieces
- King safety: attacked king, incoming checks, king in a ‘pieces shelter’, position of defenders
This huge resulting evaluation function is actually calculated up to the 2nd order, to compute a bonus/malus based on the known attacking/defending status of the players.
A lot of the pull requests in Stockfish GitHub repository consist of small changes in the weights of the aforementioned criterias, which lead to small ELO score improvements.
Tapered scaling
The weighting of the different criterias are different whether we are still in the opening, middle-game or end-game. For instance, a passed pawn might get more valuable in the late-game than in the middle-game. Hence, Stockfish has two weighting sets for every criteria: one for the middle-game and one for the end-game. Stockfish then computes a Phase factor ranging from 0 (game finished) to 128 (game not started), which helps to interpolate the between two different weightings.

The evaluation is then scaled again to fit the fifty-move rule: as this rule is close to be reached, the evaluation comes closer to a draw.
Case study
To clarify the classical evaluation approach, we will study a known position from a match between Kasparov and Topalov:

This example will focus on a positional advantage criteria: having specific pieces on specific squares. For every square of the board, a score is assigned depending on the piece that occupies this square (e.g. in the middle-game, the exposed black king on a5 is worth less than on g8 which is a safer square). This score bonus comes from two hardcoded square score tables: one for the pieces and one for the pawns. The reason for having two distinct score tables is that the score bonus for the pieces is symmetrical upon the vertical axis but not for the pawns (psqt.cpp).
if (typeof(piece) == PAWN) {
bonus += PBonus[rank][file];
}
else {
file = file < 4 ? file : 8 - file;
bonus += Bonus[piece][rank][file];
}The score tables are the same for black and white as the bitboard just needs to be flipped to compute black’s score. For instance, the white queen on D4 is worth +8 in the middle-game and+24 in the end-game (as shown below) and would be the same than having a queen on D5 for black.


The piece-square score is summed for all of the pieces on the board and is calculated with both the middle-game and the end-game piece-square score table (see above). Then, the phase factor for tapered evaluation is computed based on the amount of non-pawn material on the board. Here, the phase factor is equal to 83. At last, the final bonus interpolated between the middle-game and end-game piece-square score is computed using this phase factor.
# MG: middle-game score
# EG: end-game score
# P: phase factorFINAL_BONUS = (MG * P + (EG * (P_MAX - P)) / (P_MAX-P_MIN))
The final score is +247 for white and +46 for black: from Stockfish point of view, this board leads to a clear positional advantage for white.
Conclusion
The first part of this series presented how to read a position and how to generate candidate moves given this position. Now, this second part explained how to evaluate any given position in order to output a score for every player.
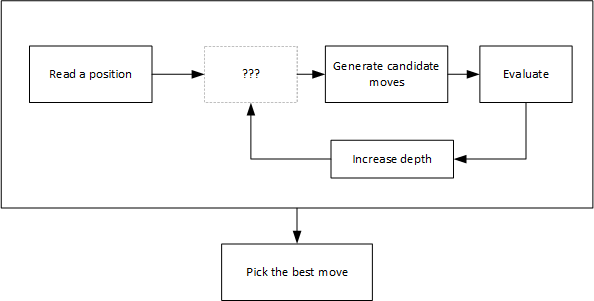
However, generating every possible combination of candidate moves and evaluating them at once is inconceivable performance-wise: the amount of candidates moves grow exponentially as we increase the depth of our search. Stockfish needs to select them wisely, which will be the topic for the next part of this series.

