Detecting Weird Data: Conformal Anomaly Detection
An introduction into conformal prediction and conformal anomaly detection frameworks (with code)
Weird data is important. Often in data science, the goal is to discover trends in the data. However, consider doctors looking at images of tumors, banks monitoring credit card activity, or self-driving cars using feedback from a camera — in these cases, its likely more important to know whether or not the data is weird or abnormal. Weird data is more formally called anomalies and mathematically can be thought of as data that is generated from a tail-end of the distribution that is used to generate the training data. In layman’s terms, our model is unprepared to handle this weird data because it was never trained to do so, causing the model to treat this data incorrectly. The end result — the doctor might not see the malignant tumor, fraudulent credit card activity may go undetected, and self-driving cars could make incorrect decisions. The challenge then is to detect and remove these anomalies.
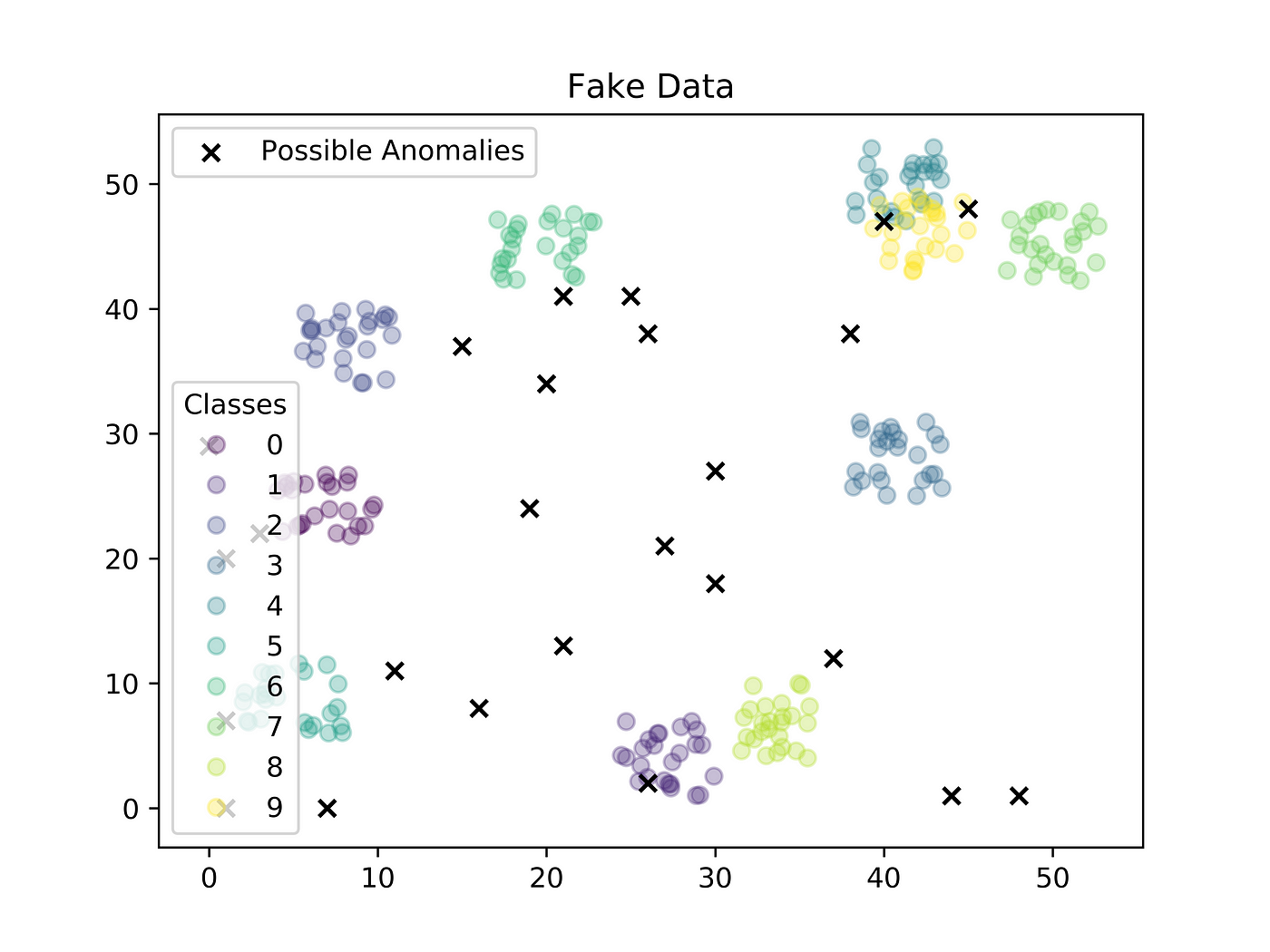
To illustrate this through an example, let’s consider the simple 2-dimensional data shown in Figure 2. where each circle represents the training data and is colored according to 10 possible classes. The black crosses are test data that have been generated uniformly at random across the 2D plane and whose label is currently unknown. How does a model know which test data points should be flagged and discarded as anomalies and which it can accurately classify? One method is to use a clustering algorithm and ignore new data that exists further than a predefined anomaly threshold from each cluster’s centroid; however, setting those thresholds requires fine-tuning and often results in many false positive anomaly detections [1]. Rather, we would prefer a method with few hyper-parameters and an easy interpretation that is independent of the data set and task at hand.
This article will describe a relatively new, effective, and extensible way to detect weird data through a process known as conformal anomaly detection (CAD) which is built on the conformal prediction (CP) framework. CP is suitable for any supervised tasks where each data is represented by an input-output pair; however, we do not need the label of the test input to determine if it is an anomaly. Furthermore, CP and CAD have the benefit of working with just about any family of algorithms (neural network, SVM, decision tree, etc.) and any type of task (regression or classification). The CP framework also has a nice statistical interpretation and only a single hyper-parameter making it extensible to a variety of situations. In addition to covering the basic theory, this article provides code to perform CAD. A link can be found in “Resources” below. For formal mathematical definitions of CP/CAD I recommend checking out [1].
What’s Covered in this Article
- Conformal Prediction (CP) Framework
- Conformal Anomaly Detection (CAD)
- Where to Go From Here
Resources
- Google Colab Notebook: A simple CAD implementation
Section 1. Conformal Prediction (CP)
Typically, regression or classification models predict a single output given an input — regression models return a continuous output whereas a classification models return a discrete output. It might seem strange at first, but instead of a single value, a CP framework returns a set of plausible outputs. For example, for regression, the output is a range of potential values and for classification its a subset of all the possible labels. You may be wondering how this is useful — aren’t we less certain of the output? Actually, with some basic assumptions, we can verify that the true output of our test input will fall in the predicted set of plausible outputs with an expected amount of confidence. Using this CP framework as a basis of an anomaly detection mechanism, we can be deterministically confident in labeling a new test input an an anomaly or not.
So what does it take to make a CP framework? The framework requires just three specific ingredients: a training data set, a significance level (ϵ), and a non-conformity measure that produces a non-conformity score for each of our inputs. We’ll look at each of these components one-by-one in the context of our simple classification example.
Ingredient 1: Training Data Set
In a supervised task, training data is simply the input-outputs pairs, where the input is often expressed as an m x n matrix with m samples and n independent variables or features, and the output is often expressed as an m x d matrix with m samples and d dependent variables. Our training data set consists of 250 input-output pairs — each input has 2 features and each label is a member of the set {0,…,9}. The training data is equally split across the 10 classes such that each class has 25 data points. Simple enough.
Ingredient 2: Significance Level ϵ
The significance level has a direct analogy to statistical significance which is often used as a threshold in an experiment to determine whether or not to reject the null hypothesis. To understand the significance level in a CP framework context, let’s first consider how it’s used. Remember, the CP framework computes a set of potential labels instead of producing a single output prediction for a new test input. Assuming that the training data and test data are independent and identically distributed (I.I.D), the probability of error or the probability that the true label of our test data is not in that set of potential labels is equal to the significance level. As a result, the significance level allows us to interpret the predicted set as a confidence interval. That is we are (1-ϵ)% confident that the true label is in our predicted set given our assumptions of I.I.D.
If you looked closely, you might have noticed that in Figure 1. the I.I.D assumption between the test data and the training data is violated. However, this example is used to show how CP can still be used to detect anomalies regardless of this assumption (although the statistical guarantee disappears). In real-life scenarios, assuming I.I.D between the test data and training data is rarely accurate; however this assumption is also rarely this violated. The point of mentioning the I.I.D assumption is that it allows a statistical guarantee on our predictive set. It is actually possible to test the I.I.D assumption online using exchangeability martingales [5] which take in a series of p-values instead of a single p-value and only grow due to a sequence of small p-values, meaning a lot of strange inputs coming in at once. This obviously would be uncommon if the test distribution was the same as the training distribution. The martingales can be used to reject the exchangeability assumption (also the I.I.D assumption) and detect an anomaly if it grows larger than some threshold [4].
Ingredient 3: Non-Conformity Measure (NCM) and Non-Conformity Scores (α)
The non-conformity measure (NCM) is our way of measuring strangeness. Theoretically, the NCM can be any real-valued function that assigns a non-conformity score α to each input. This can even be a function that simply returns a random non-conformity score; however, we tend to evaluate an NCM based on its efficiency — its ability to return small, discriminative predictive sets. A random NCM would likely return an uninformative prediction set when given a new input. Instead, we would prefer an NCM that can meaningfully measure the similarity and dissimilarity between objects.
An NCM computes a non-conformity score by calculating a value that takes into account a specific input relative to a subset of other inputs. This subset can include the rest of the training data and the test input (i.e. everything but the input in consideration). We interpret larger non-conformity scores as being more strange i.e. more likely to be an anomaly.
An example of a possible NCM is the k-nearest neighbor function which computes the average of the distances (e.g. Euclidean distances) to the k-nearest neighbors of an input. For example, if the mean distance of input 1 to its 5-nearest neighbors of class 0 is 25 and the mean distance of input 2 to its its 5-nearest neighbors of class 0 is 100, we would consider input 2 to be more strange to class 0 than input 1. Often, a popular NCM is the ratio of the average distance to the k-nearest neighbors in the same class to the average distance to the k-nearest neighbors in a different class such that both intra and inter-class similarities and dissimilarities are captured.
Compute the P-Values
Once a suitable NCM has been selected, the CP framework can be used to predict a set of potential labels for a new test input. To do so, the CP framework computes a p-value for each possible label. The p-value is the normalized proportion of the training inputs that have as least as large non-conformity measure as that of the test input. Eq. 1 shows how a single p-value is computed.

Finally, the label corresponding to each p-value is included in the prediction set if that label’s p-value is greater than or equal to the specified significance level. In other words, a label is added to our prediction set if a significant portion of our training set is stranger than our test input according to our conformal score [1].
Some Useful and Not Useful Properties of Conformal Prediction
Already mentioned was the useful property that CP produces a confidence interval where we are (1-ϵ)% confident that the true label exists in our predicted set. Another useful property is that the CP framework is well-calibrated under the I.I.D assumption, meaning that even if the training set is updated with the test input (i.e. the test input’s true label is determined) and a new test input is gathered, the errors of these two prediction sets will be independent. Therefore, given enough test inputs, our error rate will approach ϵ. If our training data is large enough to begin with and I.I.D is true, the law of large numbers tells us that the true error rate may already be accurately estimated by ϵ.
An obvious drawback of the CP framework is that it has to re-compute the conformal scores for each new test input which can be time-consuming especially if our non-conformity measure is complex. One work-around is to use an inductive conformal prediction (ICP) framework which uses a separate training set (known as a calibration data set) that doesn’t require recalculations per new input and is more practical to use for large data sets.
Section 2. Conformal Anomaly Detection (CAD)
Conformal anomaly detection (CAD) is built on the CP framework and can be used to perform anomaly detection. If you followed along in the previous section, CAD should be straightforward to understand. Let’s look at the algorithm.
Conformal Anomaly Detection (CAD) Algorithm
Inputs/Outputs: The inputs to the CAD algorithm are the significance level ϵ and a set of inputs that include the training set and the new test input. The output is a boolean variable that indicates if the test input is an anomaly or not.
- The NCM assigns a non-conformity score to each input where this non-conformity score is a metric of the similarity between this input and the rest of the inputs.
- CAD computes a p-value for our test input which is the normalized proportion of the the number of non-conformity scores that are greater than or equal to the non-conformity score of our test-input (Eq. 2).
- The test input is labelled as an anomaly if the computed p-value is less than our significance level ϵ. In other words, an input is labelled an anomaly if it is stranger than a significant portion of our training set.

Eq. 2 should look familiar to Eq. 1 which was used to compute p-values for the CP framework. A major difference between the p-values in CP and the p-values in CAD is that CP produces a set of p-values, one for each possible label, and CAD only provides a single p-value per test input.
Back to the Example
Let’s revisit our classification example from before. Let’s allow ϵ to be 0.025 and consider our training data set with 250 input-output pairs. Let’s select one of those black crosses as a new test input. We can assign a non-conformity score to each of our 251 inputs using its 10-nearest neighbors. To do so, we can compute a 251 x 251 distance matrix and sort along the rows such that the nearest distance is in the first column (the first column of this distance matrix is ignored because it will always be 0 as the Euclidean metric always produces non-negative values and is 0 when the two inputs are the same). We then calculate an array of non-conformity scores of size 251 x 1 by computing the average of the next 10 elements in each row of our distance matrix. Then, we sum up the number of times the elements in this average k-nearest neighbor array are greater than the non-conformity score of our test input. Next, our normalized p-value is computed by dividing the sum by 251. Finally, the test input is considered an anomaly if the p-value is less than 0.025.
Figure 2. shows the result of using CAD with this specific parameterization to determine whether or not our fake test data was an anomaly. The red crosses are considered anomalies and the blue crosses are considered valid inputs according to CAD.

Fortunately, we can see that the results in Figure 2. make sense. CAD tends to label all test inputs that are distanced away from a class cluster as an anomaly and all test inputs that are positioned in a class cluster as valid test data. For higher-dimensional data, although we cannot visualize the results without performing dimensionality reduction, the same principles apply.
Useful Properties of CAD
There are many reasons why CAD is preferred over typical anomaly detection techniques. Unlike many anomaly detection techniques, CAD only has one threshold hyper-parameter ϵ which represents a statistical significance level rather than an anomaly threshold. In practice, specifying a confidence threshold rather than an anomaly threshold reduces the number of false positives and fine-tuning required to perform anomaly detection. Secondly, CAD can be interpreted as a null hypothesis test in which ϵ controls the sensitivity of the anomaly detector. That is, if we can reasonably assume that the training inputs and the test input are I.I.D, then ϵ is the rate at which the null hypothesis should be rejected i.e. the rate at which CAD is expected to label a randomly generated test input as an anomaly. This is useful in practice because for security-related tasks, like credit card fraud detection or self-driving applications, we can increase ϵ to increase the sensitivity of CAD. Because it is built on the CP framework, the same restrictions apply when I.I.D cannot be assumed. In this case, martingales can be used to test I.I.D and determine anomalies from a sequence of p-values [5].
Section 3. Where To Go From Here
Hopefully, you found this discussion informative and interesting. If you’d like to know more, there are several research papers that have continued to work on CP frameworks used in anomaly detection. Already mentioned was the informal conformal prediction (ICP) framework which is more efficient than the CP framework. However, one disadvantage of ICP is that it may not produce as accurate prediction sets as CP and it requires separating the training data into a calibration and training data set which may be difficult if you have limited data. A paper that explains using CP and ICP frameworks with anomaly detection can be found here [1]. Also, although I didn’t really get into it, for high-dimensional data it is common to use a model to produce the conformal scores as found in this paper that used a neural network to produce the conformal scores [2] or this paper that used a random forest in the context of medical diagnosis [3]. This is one reason why conformal prediction is so useful — it can be used in addition to and alongside just about any type of model, so long as you can extract meaningful non-conformity scores.
Another great paper written at Vanderbilt, my alma mater, sampled the latent space of a variational autoencoder (VAE) to provide not just one p-value for a given test input but several to use in the martingale test [4]. I heavily encourage you checking that one out as it also provides a good, succinct explanation of CP/ICP.
Thank you for reading! Like always, for any questions or concerns, feel free to leave a comment below. The goal of all my articles is to help make this technology understandable and accessible, so I’d be happy to help out. Cheers!
Citations
[1] Laxhammar, Rikard, and Göran Falkman. “Inductive conformal anomaly detection for sequential detection of anomalous sub-trajectories.” Annals of Mathematics and Artificial Intelligence 74.1–2 (2015): 67–94.
[2] Papadopoulos, Harris, Volodya Vovk, and Alex Gammermam. “Conformal prediction with neural networks.” 19th IEEE International Conference on Tools with Artificial Intelligence (ICTAI 2007). Vol. 2. IEEE, 2007.
[3] Devetyarov, D., and I. Nouretdinov. “Prediction with confidence based on a random forest classifierlearning for medical diagnosis.” Proceedings of 6th IFIP WG. Vol. 12.
[4] Cai, Feiyang, and Xenofon Koutsoukos. “Real-time Out-of-distribution Detection in Learning-Enabled Cyber-Physical Systems.” arXiv preprint arXiv:2001.10494 (2020).
[5] Fedorova, Valentina, et al. “Plug-in martingales for testing exchangeability on-line.” arXiv preprint arXiv:1204.3251 (2012).