Deploying a Machine Learning Model as an API on Red Hat OpenShift Container Platform
From Source Code in a GitHub repository with Flask, Scikit-Learn and Docker

Machine and Deep Learning applications have become more popular than ever. As we have seen previously, the enterprise Kubernetes platform, Red Hat OpenShift Container Platform, helps data scientists and developers to really focus on the value using their preferred tools by bringing additional security controls in place and make environments much easier to manage. It provides the ability to deploy, serve, secure and optimize machine learning models at enterprise-scale and highly available clusters allowing data scientists to focus on the value of data. We can install Red Hat OpenShift clusters in the cloud using managed services (Red Hat OpenShift on IBM Cloud, Red Hat OpenShift Service on AWS, Azure Red Hat OpenShift) or we can run them on our own by installing from another cloud provider (AWS, Azure, Google Cloud, Platform agnostic). We also have the possibility to create clusters on supported infrastructure (Bare Metal, IBM Z, Power, Red Hat OpenStack, Red Hat Virtualization, vSphere, Platform agonistic) or a minimal cluster on our laptop which is useful for local development and testing (MacOS, Linux, Windows). Lot of freedom here.
In this article, we will show how to deploy a simple machine learning model developed in Python on an OpenShift cluster on the cloud. For the purpose of this article, we will create an OpenShift cluster on IBM Cloud, and show how to deploy our machine learning application from a GitHub repository and expose the application to access it publicly (with and without a Dockerfile).
We can do all of this with very few and easy steps.
Create an OpenShift Cluster Instance
We connect to our IBM Cloud account, and click on the Navigation Menu, OpenShift, Clusters:
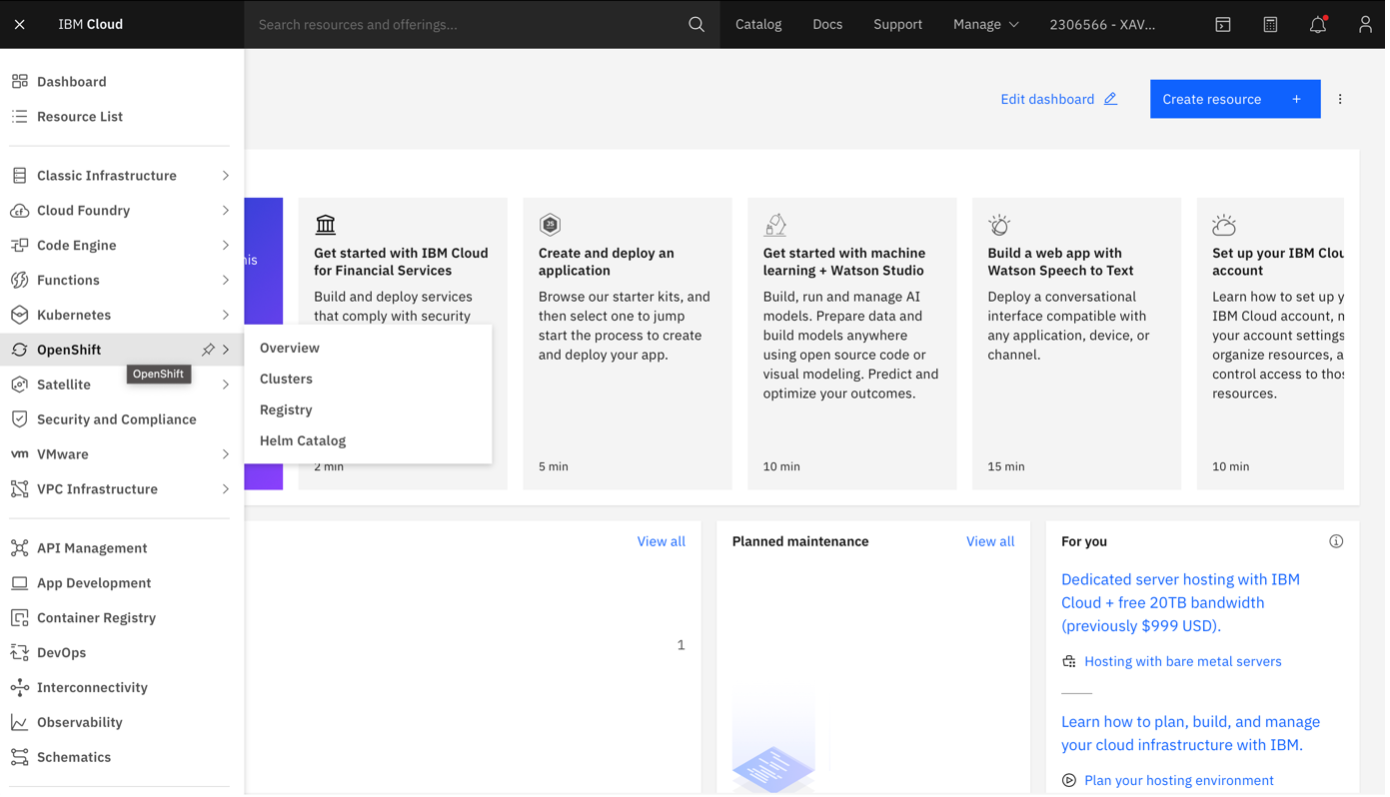
Click on Create cluster:

We can select a couple of options such as location, compute environment to run our cluster or worker pool (number of vCPUs, memory, encrypt local disk …) and click create. One interesting option is that we can for example choose Satellite which allows to run our cluster in our own Data Center. For the purpose of this article, we chose Classic.

Done !

You can also create clusters using CLI: https://cloud.ibm.com/docs/openshift?topic=openshift-clusters
Deploying an Application from Source Code in a GitHub repository
We can create a new OpenShift Enterprise application from source code, images, or templates and we can do it through the OpenShift web console or CLI. A GitHub repository was created with all the sources and a Dockerfile in order to assemble a Docker image and later deploy it to the OpenShift cluster: https://github.com/xaviervasques/OpenShift-ML-Online.git
First of all, let’s see and test our application. We clone our repository:
git clone https://github.com/xaviervasques/OpenShift-ML-Online.gitIn the folder, we should find the following files:
Dockerfile
train.py
api.py
requirements.txt
OpenShift will automatically detect whether the Docker or Source build strategy is being used. In our repository, there is a Dockerfile.OpenShift Enterprise will generate a Docker build strategy. The train.py is a python script that loads and split the iris dataset which is a classic and very easy multi-class classification dataset consisting of 3 different types of irises’ (Setosa, Versicolour, and Virginica) petal and sepal length, stored in a 150x4 numpy.ndarray. We used scikit-learn for both the dataset and model creation (Support Vector Machine classifier). requirements.txt (flask, flask-restful, joblib) is for the Python dependencies and api.py is the script that will be called to perform the inference using a REST API. The API will return the classification score of the svm model on the test data.
The train.py file is the following:
The api.py file is the following:
The Dockerfile:
And finally, the requirements.txt file:
In order to test if everything is fine, let’s build and run the docker image on our local machine:
cd OpenShift-ML-Online
docker build -t my-ml-api:latest .
docker run my-ml-apiThe output is the following:

and you can use the API with a curl:
curl http://172.17.0.2:8080/We should get the following output:

We are now ready to deploy.
To create a new project, we can use both CLI (using IBM Shell or our own terminal) or the OpenShift web console. With the console, to create a new project, from the OpenShift clusters console, we select our cluster (mycluster-par01-b3c.4x16) and we click on OpenShift web console.


From the perspective switcher, we select Developer to switch to the Developer perspective. We can see that the menu offers items such as +Add, Builds and Topology.

We click on +Add and create the Project:
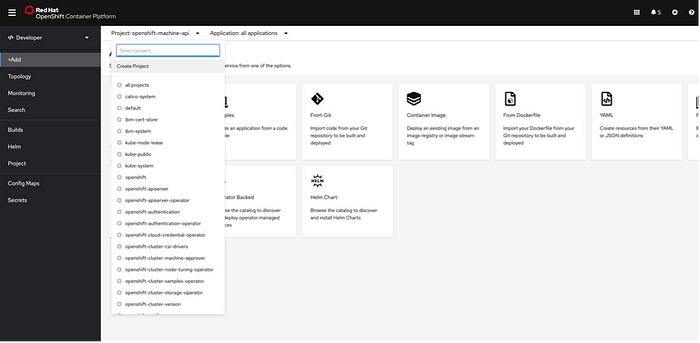
In this chapter, we will use CLI in our local machine. As we installed our OpenShift cluster on IBM Cloud, if not already done, it is necessary to install:
- IBM Cloud CLI (https://cloud.ibm.com/docs/cli?topic=cli-install-ibmcloud-cli)
- OpenShift Origin CLI (https://docs.openshift.com/container-platform/4.2/cli_reference/openshift_cli/getting-started-cli.html)
We need then to log in to OpenShift and create a new project. In order to do this, we need to copy the Login Command:

We login into our account:
ibmcloud loginAnd we copy/paste the log in command:
oc login — token=sha256~IWefYlUvt1St8K9QAXXXXXX0frXXX2–5LAXXXXNq-S9E — server=https://c101-e.eu-de.containers.cloud.ibm.com:30785The new-app command allows to create applications using source code in a local or remote Git repository. In order to create an application using a Git repository we can type the following command in our terminal:
oc new-app https://github.com/xaviervasques/OpenShift-ML-Online.gitThis command has several options such as using a subdirectory of our source code repository by specifying a — context-dir flag, specifying a Git branch or setting the — strategy flag to specify a build strategy. In our case, we have a Dockerfile that will automatically genera a Socker build strategy.

The application is deployed ! The application needs to be exposed to the outside world. As specified by the previous output, we can do this by executing the following command:
oc expose service/openshift-ml-online
We can check the status:
oc status
We can find in the output the route of our API:
curl http://openshift-ml-online-default.mycluster-par01-b-948990-d8688dbc29e56a145f8196fa85f1481a-0000.par01.containers.appdomain.cloudwhich provide the expected output from it (the classification score of the svm model on the test data)

oc get pods --watch
We can also find all information about our service in the OpenShift web console:




From the perspective switcher, if we select Developer to switch to the Developer perspective and click on Topology, we can see the following screen:

At the bottom right of the screen, the panel displays the public URL at which the application can be accessed. You can see it under Routes. If we click on the link, we also obtain the expected result from our application.

We can create unsecured and secured routes using the web console or the CLI. Unsecured routes are the simplest to set up and the default configuration. However, if we want to offer security for connections to remain private, we can for example use the create routecommand and provide certificates and a key.
If we want to delete the application from OpenShift, we can use the oc delete all command:
oc delete all — selector app=myappIn the case where there is no Dockerfile, the OpenShift Source to Image (S2I) toolkit will create a Docker image. The source code language is auto-detected. We can follow the same steps. OpenShift S2I uses a builder image and its sources to create a new Docker image that is deployed to the cluster.
Conclusion
It becomes simple to containerize and deploy a machine/deep learning application using Docker, Python, Flask and OpenShift. When we start to migrate workloads into OpenShift, the application is containerized into a container image which will be deployed in the testing and production environments decreasing the amount of missing dependencies and misconfiguration issues that we can see when we deploy applications in the real life.
Real life is what it is all about. MLOps requires cross collaboration between data scientists, developers, IT operations which can be time consuming in terms of coordination. Building, testing and training ML/DL models on Kubernetes hybrid cloud platforms such as OpenShift allows to be consistent, scale application deployments, and helps to deploy/update/redeploy as often as needed into our production environment. The integrated DevOps CI/CD capabilities in Red Hat OpenShift allow us to automate integration of our models into the process of the development.
Sources
https://developer.ibm.com/technologies/containers/tutorials/scalable-python-app-with-kubernetes/
https://cloud.google.com/community/tutorials/kubernetes-ml-ops
https://docs.openshift.com/enterprise/3.1/dev_guide/new_app.html
https://github.com/jjasghar/cloud-native-python-example-app/blob/master/Dockerfile
https://docs.openshift.com/container-platform/3.10/dev_guide/routes.html
https://docs.okd.io/3.11/minishift/openshift/exposing-services.html
https://docs.openshift.com/container-platform/4.7/installing/index.html#ocp-installation-overview
https://www.openshift.com/blog/serving-machine-learning-models-on-openshift-part-1
https://scikit-learn.org/stable/modules/generated/sklearn.datasets.load_iris.html

