
Deep Learning with Jax and Elegy
Going beyond TensorFlow, Pytorch, and Keras
In this post, we will explore how to leverage Jax and Elegy to create Deep Learning models. Along the way, we will see how Jax compares to TensorFlow and Pytorch, and similarly how Elegy compares to Keras.
What is Jax?
Without a doubt TensorFlow (2015) and Pytorch (2016) have had a big impact in the ML community, the “arms race” between them has made them converge to a similar set of features (check out State of ML Frameworks 2019 for a good summary of their struggle). Jax (2018) is the latest to join the party and it represents a nice synthesis of this convergence. But instead of directly being a Deep Learning framework, Jax created a super polished linear algebra library with automatic differentiation and XLA support that some have called Numpy on Steroids.
Here are some of the things that make Jax awesome.
The Numpy API
Jax implements the Numpy API and makes it the main way to operate with Jax arrays.
This is actually a huge deal since Numpy is the lingua franca of numerical computing in Python and every data scientist already has countless hours of experience with Numpy regardless of its particular field of practice. It makes working with Jax a true pleasure. Not only that, Jax’s ndarray base type inherits from Numpy’s ndarray type, meaning that 3rd party libraries can accept these structures. You can even start using Jax “just” to speed up your existing Numpy code with very few changes.
A Unified API
Jax has a clean and unified API for eager and JIT execution.
Nowadays TensorFlow and Pytorch have both eager and compiled execution modes, however, each added the mode it was missing late in the framework’s lifetime, this has left scars. In TensorFlow for example eager mode was added in such a way that it was not 100% compatible with graph mode, giving rise to a bad developer experience. In Pytorch’s case, it was initially forced to use less intuitive tensor formats (like NCWH on its vision API) just because they were more performant on eager mode and has kept them for compatibility reasons. Jax, on the other hand, was born with and shaped by both of these modes, it mainly focuses on using eager for debugging and JIT to actually perform heavy computations, but you can mix and match these modes where convenient.
XLA
Jax is based on next gen ML compiler technology.
Jax exclusively uses XLA instead of resorting to a mixture of device dependent C++ and CUDA code. While TensorFlow is the reason why XLA exists at all, its use is not completely wide spread within its code base and still has device dependent code. Pytorch, on the other hand, has a frustrating amount of device dependent code to the point where certain operations are only supported on specific devices (pytorch/xla is a thing but it’s only focused on TPU support).
Special Operations
Jax brings a unique set of powerful functional transformations.
Jax has some novel, easy-to-use transformations that enable users to perform complex operations that are hard or even impossible in other frameworks. grad for example makes calculating n-th order gradients extremely easy, vmap enables users to write per sample operations and automatically apply them to a whole batch, and pmap allows the user to easily distribute computation among devices. There are more transformations which you can find on Jax’s official documentation.
Compatibility
Jax is Pythonic.
This used to be Pytorch’s moto but Jax takes it another level by basing its architecture on function composition and basic python types, i.e. Jax can differentiate with respect to types like lists, tuples, and dictionaries! This isn’t just a neat trick, many Jax-based frameworks depend on this feature. Jax also implements protocols like __array__ and __array_module__ which maximizes its compatibility with the rest of the Python data science ecosystem.
Deep Learning with Elegy
While Jax has had all the pieces to create neural networks from the beginning, it didn’t have a mature framework for this purpose. In the last few months however a couple of research-oriented frameworks like Flax, Trax, and Haiku have appeared, these libraries focus on defining a layer interface while at the same time trying to come up with strategies to perform state management compatible with Jax’s functional purity restrictions.
While these efforts are a great step in the right direction if you are looking for something more practical like Keras they will make you feel a bit out of place since you will find yourself writing your own training loop, loss functions, and metrics.
Enter Elegy.
What is Elegy?
Elegy is a Deep Learning framework based on Jax and inspired by Keras and Haiku. Elegy has the following goals in mind:
- Easy-to-use: The Keras Model API is super simple and easy-to-use so Elegy ports it and tries to follow it as closely as possible. Keras users should feel at home when using Elegy.
- Flexibility: While Keras is simple it’s also very rigid for certain use cases, Elegy uses Dependency Injection to give you maximal flexibility when defining your models, losses, and metrics.
- Succinct: Elegy’s hooks-based Module System makes it easier (less verbose) to write model code compared to Keras or Pytorch since it lets you declare submodules, parameters, and states directly in your
call(forward) method.
To see Jax and Elegy in action let’s look at a simple yet non-trivial example.
Study Case: Mixture Density Networks
We will create a model in Elegy for this 1D regression problem:
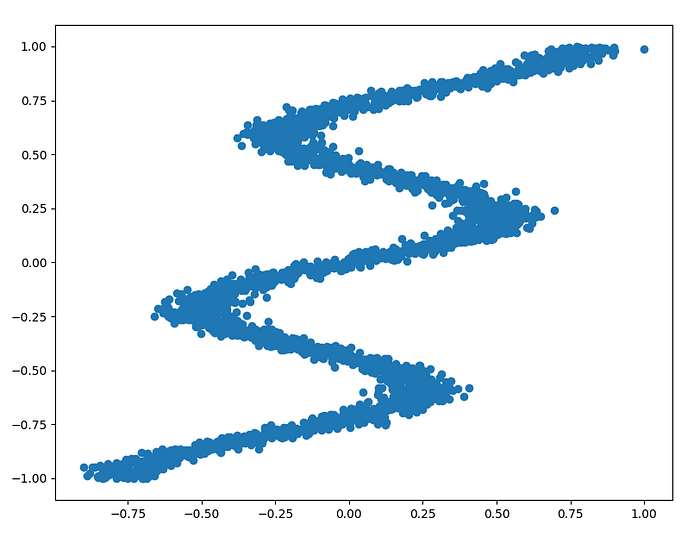
As you can see, this is an inverse problem which means there is more than one possible solution in Y for some values in X. The problem is interesting because out-of-the-box classifiers can’t handle this type of data well. If we were to give this data to a simple linear regression it would produce this model:
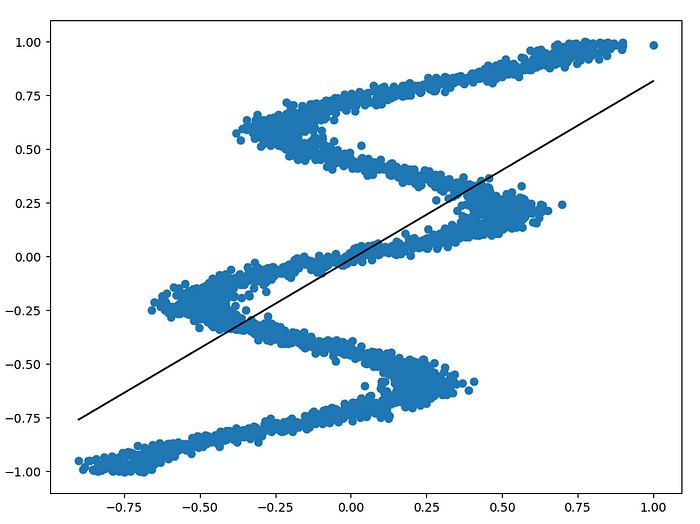
This clearly is not a good solution since most of its predictions are outside of the data distribution. A good way to model this is using a Mixture Density Network which is a type of Mixture Model. We won’t go into the details of the theory here but you can refer to A Hitchhiker’s Guide to Mixture Density Networks for more information.
Imports
We will begin by importing some of the libraries that we will use which include Numpy, Jax, and Elegy.
Defining the Architecture
Next, we will define the architecture of our model. In Elegy the basic abstraction is called a Module, this naming convention was borrowed from Haiku. Like Layer in Keras, a Module must define the call method which represents the forward computation of the network. Inside the call method you can use Jax functions and other modules to define the architecture, you can find common modules like Linear or Conv2D in elegy.nn.
For our Mixture Density Network we will define a simple backbone structure (x), and then split it into the multiple components (y) where each component will try to model the mean and variance of a portion of the data. From the backbone we will also create a gating head (probs) which will assign probability weights to each component conditioned by x.
There is a lot happening in this piece of code, you don’t need to understand all of it right now however notice the following things:
- We are creating a Mixture Density Network with
kcomponents wherekis a hyperparameter. We will set this value to5. - We are making various inline calls to
elegy.nn.Linear, infact observe that we are even doing it directly inside a list comprehension. Compare this to Keras or Pytorch where you usually have split the code by first defining the submodules on__init__and later using them incall/forward. These inline calls are called Module Hooks and they make reading and writing model code way easier. - We are using functions from the
jax.nnmodule likereluandsoftmax, this module contains a lot of useful function for neural networks. - We used the
stackfunction from Jax’s Numpy API which we imported asjnp.
If we produce a Keras-style summary for this model (we will see how to do this later) we will get the following description:

Here we are using a batch size of 64. Notice that we have 2 outputs:
- The first one which we called
ythat contains the mean and variance for our5components which is why it has the shape[64, 5, 2]. - The second which we called
probsis the probability weight of each of our5components which is why it has the shape[64, 5].
Creating the Loss Function
Next we will define our loss function. For this kind of problem the loss should be the negative log likelihood of our model given the data if we assume that each component is modeled by a normal distribution. The loss is given by this formula:
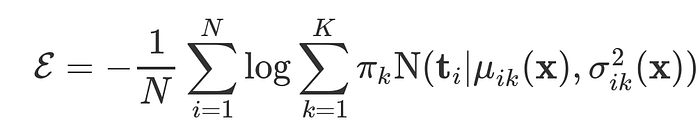
Here 𝜋k represent the probability weight of each component k, we call this probs, and the function N(…) represent the Probability Density Function of a normal distribution for each component, this will be parameterized by y. We will implement this loss by creating a class that inherits from elegy.Loss and calculates this formula using regular Jax operations.
Defining complex loss functions and metrics is a recognized pain point in Keras, thankfully Elegy gives us more flexibility and we can actually create a single loss based on multiple outputs without a matching number of labels 🥳. By default y_pred is just whatever is returned by the model, which is a tuple in this case so we destruct it as y and probs on the 3rd line, and y_true is just the labels passed by the user, in this case it’s just an array with the Y values so we don’t have to do anything.
The code more or less implements the formula above in a 1-to-1 fashion. Notice that we use jax.scipy.stats.norm.pdf to compute the probability of the data given the parameters output by our model, this is pretty cool since most Numpy users are familiar with Scipy and can leverage their knowledge of this library. safe_log is just a simple custom function for log that is numerically stable.
Training the Model
Elegy comes with a Model interface that implements most of the methods found on its Keras counterpart like fit, evaluate, predict, summary, etc, with minor changes. This makes training models in Elegy super easy! The Model’s constructor accepts a Module as its first argument and most of the arguments accepted by keras.Model.compile, we will use it to pass some instances of our MixtureModel and MixtureNLL loss plus the adam optimizer from the optax library.
Having this model instance we can use summary to print the table with the description of the architecture we saw earlier, it has the minor difference with the Keras version in that it requires you to pass a sample input as its first parameter, it also accepts an optional depth parameter which lets you control how detailed you want the summary to be.
Finally, we train the model using the fit method. While in this case the example presented is also valid in Keras, Elegy’s fit method makes slight modifications regarding the input data. In particular, Elegy remains agnostic to the data pipeline framework you use as it only supports ndarrays or structures containing ndarrays (tuple, list, dict) and generators/iterators of ndarrays or structures of these. You can easily use tf.data just by levering the Dataset.as_numpy_iterator method or Pytorch’s DataLoader by avoiding the to_tensor transform.
During training, you will see the usual Keras progress bar showing you the values for the losses and metrics 😊. In general, you will find that training is much simpler in Elegy compared to other Jax libraries which are more research oriented since it provides implementations of common losses, metrics, and most of the callbacks available in Keras that give support for things like creating checkpoints, early stopping, TensorBoard, etc.
Check out Elegy’s documentation for more information.
Results
Once trained we can inspect the distribution learned by each component by plotting their predictions overlayed over the data.
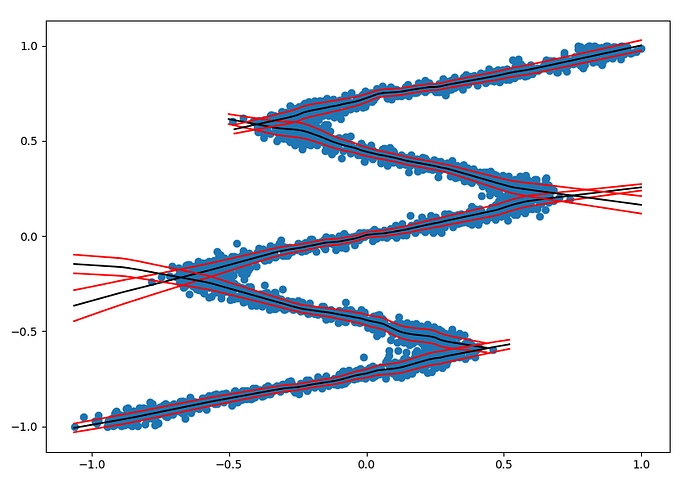
Here the black lines are the predicted means of the components and the red lines represent the estimated standard deviation of the data. We restrict the plot of each component to regions where it has probability above a certain threshold to get a sense of its distribution along the data. However, we can also visualize the probability weight of each component for each point in X independently:
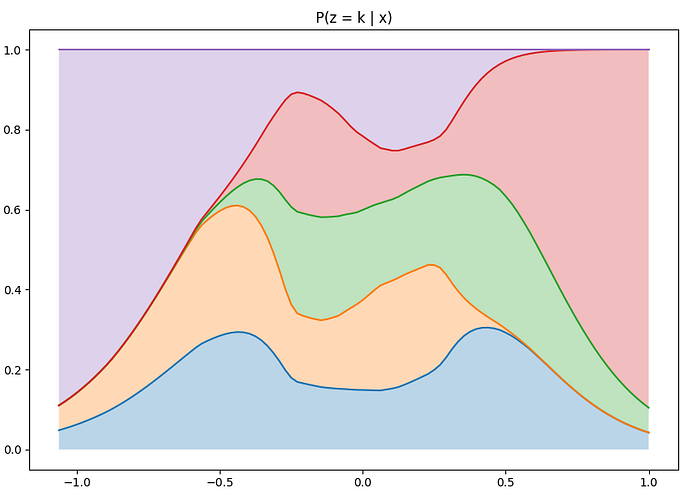
As expected there is one component which dominates for points where X < -0.75 (component near the bottom-left) and another that dominates for points where X > 0.75 (component near the top-right). The rest of the points distribute its probability among different components but vary a bit depending on the density of the data at different points.
The Code
If you want a more detailed view of the code or run it yourself you can check it out at cgarciae/simple-mixture-models.
Recap
- Jax is a clean Linear Algebra library with builtin Automatic Differentiation implemented on top of XLA that takes all the lessons learned from its predecessors.
- Jax is very Pythonic, it’s Numpy API is awesome and it’s very compatible with the rest of the data science ecosystem.
- Elegy offers a Keras-like experience for creating Deep Learning models and it tends to be much easier to use than alternatives such as Flax, Trax and Haiku.
- Elegy introduces some mechanisms which make it easier/less verbose to define model code and gives more flexibility in the definition of losses and metrics compared to Keras.
We hope you enjoyed this post. If you liked it please share it, if you liked Elegy give it a star on Github. Feedback is welcomed.
I’d like to thank David Cardozo and Carlos Alvarez for their feedback and support.

