In a federated architecture, in which responsibilities are distributed between domains, it’s harder to oversee dependencies and obtain insights in Data usage. This is where data contracts come into play. Why do data contracts matter? Because they provide insights into who owns what data products. They support setting standards and managing your data pipelines with confidence. They provide information on what data products are being consumed, by whom and for what purpose. Bottom line: data contracts are essential for robust data management!
Before you continue reading, I encourage you to look at data product distribution and usage from two dimensions. First, there are technical concerns, such as data pipeline handling and mutual expectations on data stability. Second, there are business concerns, like agreeing on the purpose of data sharing, which may include usage, privacy, and purpose (including limitations) objectives. Typically, different roles come into play for each dimension. For technical concerns, you commonly rely on application owners or data engineers. For business concerns, you commonly rely on product owners or business representatives.
Data Contracts
Data contracts are like data delivery contracts or service contracts. They’re important because when data products become popular and widely used, you need to implement versioning and manage compatibility. This is needed, because in a larger or distributed architecture it’s harder to oversee changes. Applications that access or consume data from other applications always suffer from coupling. Coupling means that there’s a high degree of interdependence. Any change to the data structure, for example, could have a direct impact on other applications. In cases where many applications are coupled to each other, a cascading effect sometimes can be seen. Even a small change to a single application can lead to the adjustment of many applications at the same time. Therefore, many architects and software engineers avoid building coupled architectures.
Data contracts are positioned to be the solution to this technical problem. A data contract guarantees interface compatibility and includes the terms of service and service level agreement (SLA). The terms of service describe how the data can be used, for example, only for development, testing, or production. The SLA typically also describes the quality of data delivery and interface. It also might include uptime, error rates, and availability, as well deprecation, a roadmap, and version numbers.
Data contracts are in many cases part of a metadata-driven ingestion framework. They’re stored as metadata records, for example, in a centrally managed metastore, and play an important role for data pipeline execution, validation of data types, schemas, interoperability standards, protocol versions, defaulting rules on missing data, and so on. Therefore, data contracts include a lot of technical metadata.
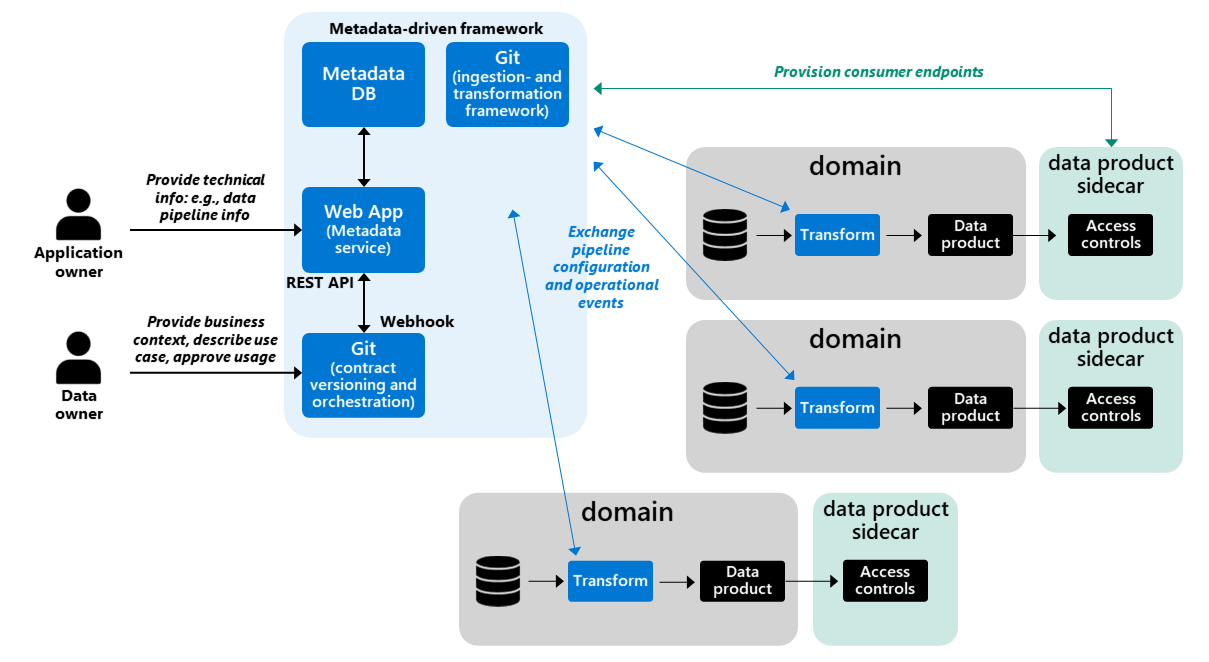
My recommendation, for a distributed architecture, is to distribute your data pipeline framework across different domains. Domains, in this approach, conform to a common way of working. Domains process data themselves, which means that the control and responsibility stay with your domains. The framework and metadata, however, remain under central governance.
Another recommendation, when implementing a federated way of working, is to start small. Start with the basics like storing metadata for schema validation, enterprise identifiers and references to other datasets in a shared metadata repository. Add data lineage support for visualizing data movements. Next, bootstrap your processes and implement controls using libraries like Great Expectations for validating technical data quality. A best practice for building dynamic data pipelines using Azure Synapse and Purview can be found here: https://piethein.medium.com/modern-data-pipelines-with-azure-synapse-analytics-and-azure-purview-fe752d874c67
All your controls should be part of your continuous integration procedures. You should capture all runtime information, such as metrics and logging, and make it part of your metadata foundation. This approach provides visibility over the stability of your data pipelines. So, there’s a feedback loop from your domains to the central management cockpit.
When achieving stability over all your data movements, continue scaling by capturing what data attributes, such as tables and columns, are used by what data consumers. You could use the same metastore for this information. This input about usage is needed for detecting breaking changes. It is your mechanism that allows you to determine the impact on producers or consumers. If data product datasets aren’t consumed by anyone, you can allow disruptive changes to happen. Put controls to allow handshakes between data providers and consumers. I’ve seen companies using source control, such as Git, for managing this process.
Data Sharing Agreement
Data sharing agreements are an extension of your data contracts. They cover intended usage, privacy, and purpose (including limitations). They’re interface independent and give insights into what data is used for what particular purpose and are input for data security controls. These agreements can be, for example, what filters or security protections to be applied on what data.
Data sharing agreements also prevent miscommunication over data usage. Before data is shared, domains should discuss data sharing and data usage issues. When they reach a collaborative understanding, they should then document that understanding in a data sharing agreement. Your data sharing agreement might also cover items like functional data quality, historization, data life cycle management and further distribution. This approach of reaching a common understanding is important not only from a regulatory perspective, but also delivers value to your organization.
You also want to apply classifications and conditions on your data, such as sensitivity labels or filtering conditions. This becomes a concern when securing data. In the diagram from the previous section, you witness a "data product sidecar". Zhamak refers to this as a component or layer for injecting policy execution, such as data access controls or output method of data consumption. In my previous role, I designed a similar pattern: data product access layer. It’s a security abstraction over your domain data for handling your security enforcement. It is a security layer that generated from your data contracts for safe access to data. It can be an ACL or serverless view, which is dynamically created from your data contract repository after reaching a common understanding. Or duplicated dataset, which is selected and filtered for a specific consumer. Your end goal must be to derive these security views from your data contracts in a fully automated manner.
Finally, I encourage you to also make a relationship between your data contract attributes and documentation. Ensure semantic context is provided and a relationship is made to your glossary. This allows consumers to understand how the translation from business requirements to an actual implementation has been made. If a relationship to business terms is important to you, consider implementing policies. For example, a contract can only be established when all data product attributed are linked to business term entities. Same policies might also apply for contextual changes, such as relationship and definition adjustments.
Best practices when starting
How to get started with data contracts? How to make things practical? My recommendation is to start slow. It’s mostly an organizational challenge. Don’t introduce too many changes after each other. Data contracts are a cultural shift. Users need to become familiar and must understand the importance of data ownership. The transition is also about finding the sweet spot between too few and too many metadata attributes. About the transition:
- First, create stability over your technical data pipelines. If they’re unstable and subject to unexpected and disruptive changes, none of your use cases will make it into production.
- For your data sharing agreements, start simple and pragmatic by putting a process in place. Don’t overcomplicate things. You could, for example, start with a simple form or template that is designed in Microsoft Forms. You should draft it in clear, concise language that is easy to understand. Accept manual processes. Limit your initial metadata requirements. Your first phase is about cultural shift and collecting requirements. Iterate until your metadata requirements become stable.
- After you put your first processes in place, try to replace your manual forms with a web-based application, database and/or message queue. During this stage, your central data governance team will still be overseeing. The level of granularity of data access is typically coarse-grained, so on folders or files. Try to utilize REST APIs for automatically provisioning data access policies or ACLs.
- Your next stage is implementing a stronger workflow for handling approvals. Put your data owners or data stewards in the lead. Your central data governance team will be overseeing from the back seat. This team reviews all data contracts on a regular basis. By this stage you should also have a data catalog up and running showing all ready-for-consumption data products. Make improvements to your data security and enforcement capabilities. Allow for finer-grained selections and filters. Consider techniques like dynamic data masking to prevent data duplication.
- At the end of your journey, everything will be self-service and fully automated. This includes automated security enforcement and machine learning for predicting data approvals. Secure views, for example, are automatically deployed after approval.
Data contracts are a relatively new approach to Data Mesh. They are important as they provide transparency over your dependencies and data usage. Start small and focus on technical stability and standardization first. Iterate by using a lessons-learned process. Data governance is essential, but too much will cause overhead. Slowly build up and automate. These are my lessons learned.





