
I’m not a fan of CSVs. They’re slow to query and take more disk space than required. Think expensive if you’re using the cloud to process large CSV files.
There are many alternatives – such as Excel, databases, and HDFs – but one in particular stands above the competition. That is, if you want to stick with row storage. It’s called Apache Avro, and you’ll learn all about it today.
If you want even more efficient columnar data format, look no further than Parquet:
Today’s article answers the following questions:
- What is Avro?
- How to work with Avro in Python?
- CSV or Avro – which is more efficient?
But what is Avro?
Avro is an open-source project which provides services of data serialization and exchange for Apache Hadoop. Don’t worry – you don’t need a big data environment – your laptop will do just fine. The guy behind Avro is Doug Cutting. He’s also called the father of Hadoop.
If you’re unfamiliar with the term serialization, here’s a crash course. It is a process of converting objects such as arrays and dictionaries into byte streams that can be efficiently stored and transferred elsewhere. You can then deserialize the byte stream to get the original objects back.
Avro is row-orientated, just like CSV. This makes it different from, let’s say, Parquet, but it’s still a highly efficient data format.
Here’s another crash course – for those unfamiliar with the difference between row and column storage. Imagine you have the following data:
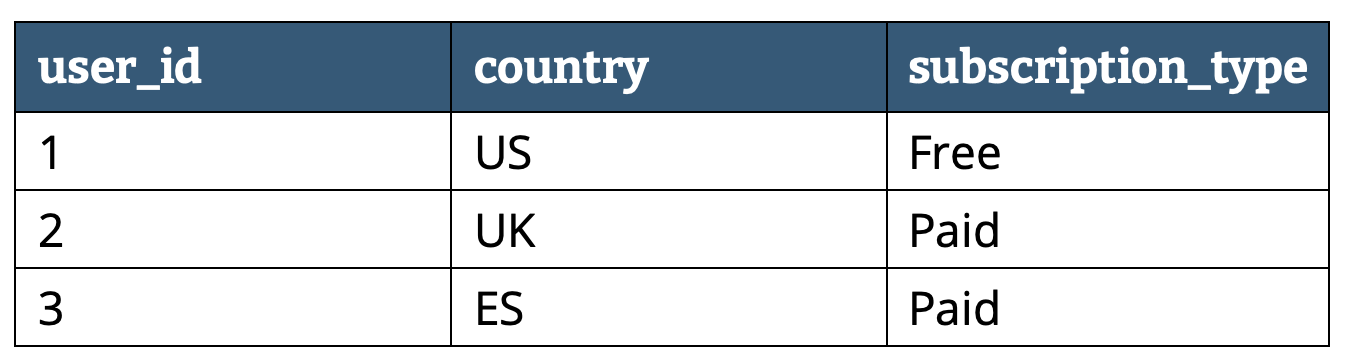
Here’s how it would be organized in both row and column storage:

Column storage files are more lightweight, as adequate compression can be made for each column. Row storage doesn’t work in that way, since a single row can have multiple data types.
But here’s the deal with Avro – it stores a JSON-like schema with the data, so the correct data types are known in advance. That’s where the compression happens.
In a nutshell, a single Avro file contains a JSON-like schema for data types and the data itself in binary format.
Avro has an API for every major programming language. But there’s a catch – Pandas doesn’t support it by default. So no, you don’t have access to read_avro() and to_avro() functions. You’ll have to work around that.
It’s not difficult – as you’ll see next.
How to work with Avro in Python?
There are two installable libraries for working with Avro files:
avro– Documentation linkfastavro– Documentation link
The latter states the former library is dog slow, as it takes about 14 seconds to process 10K records. You’ll stick with fastavro for that reason.
Here’s how to set up a new virtual environment and install necessary libraries (for Anaconda users):
conda create --name avro_env python=3.8
conda activate avro_env
conda install -c conda-forge pandas fastavro jupyter jupyterlabExecute the following command to start JupyterLab session:
jupyter labYou’ll use the NYSE stock prices dataset for the hands-on part. The dataset comes in CSV format – around 50 MB in size. Use the following snippet to import the required libraries and load the dataset:
import pandas as pd
from fastavro import writer, reader, parse_schema
df = pd.read_csv('prices.csv')
df.head()Here’s how the stock prices dataset looks like:

Converting a Pandas DataFrame to Avro file is a three-step process:
- Define the schema – You’ll have to define a JSON-like schema to specify what fields are expected, alongside their respective data types. Write it as a Python dictionary and parse it using
fastavro.parse_schema(). - Convert the DataFrame to a list of records – Use
to_dict('records')function from Pandas to convert a DataFrame to a list of dictionary objects. - Write to Avro file – Use
fastavro.writer()to save the Avro file.
Here’s how all three steps look like in code:
# 1. Define the schema
schema = {
'doc': 'NYSE prices',
'name': 'NYSE',
'namespace': 'stocks',
'type': 'record',
'fields': [
{'name': 'date', 'type': {
'type': 'string', 'logicalType': 'time-millis'
}},
{'name': 'symbol', 'type': 'string'},
{'name': 'open', 'type': 'float'},
{'name': 'close', 'type': 'float'},
{'name': 'low', 'type': 'float'},
{'name': 'high', 'type': 'float'},
{'name': 'volume', 'type': 'float'}
]
}
parsed_schema = parse_schema(schema)
# 2. Convert pd.DataFrame to records - list of dictionaries
records = df.to_dict('records')
# 3. Write to Avro file
with open('prices.avro', 'wb') as out:
writer(out, parsed_schema, records)It’s not as straightforward as calling a single function, but it isn’t that difficult either. It could get tedious if your dataset has hundreds of columns, but that’s the price you pay for efficiency.
There’s also room for automating name and type generation. Get creative. I’m sure you can handle it.
Going from Avro to Pandas DataFrame is also a three-step process:
- Create a list to store the records – This list will store dictionary objects you can later convert to Pandas DataFrame.
- Read and parse the Avro file – Use
fastavro.reader()to read the file and then iterate over the records. - Convert to Pandas DataFrame – Call
pd.DataFrame()and pass in a list of parsed records.
Here’s the code:
# 1. List to store the records
avro_records = []
# 2. Read the Avro file
with open('prices.avro', 'rb') as fo:
avro_reader = reader(fo)
for record in avro_reader:
avro_records.append(record)
# 3. Convert to pd.DataFrame
df_avro = pd.DataFrame(avro_records)
# Print the first couple of rows
df_avro.head()And here’s how the first couple of rows look like:

Both CSV and Avro versions of the dataset are identical – but which one should you use? Let’s answer that next.
CSV vs. Avro – Which one should you use?
It’s a bit tricky to answer this question. Some people like CSVs because you can edit them directly. Avro doesn’t come with that option. All results you’ll see are based on the original 50 MB CSV file. Your mileage may vary.
Here’s a comparison between read times – pd.read_csv() and fastavro.reader(), alongside the appending to a list:
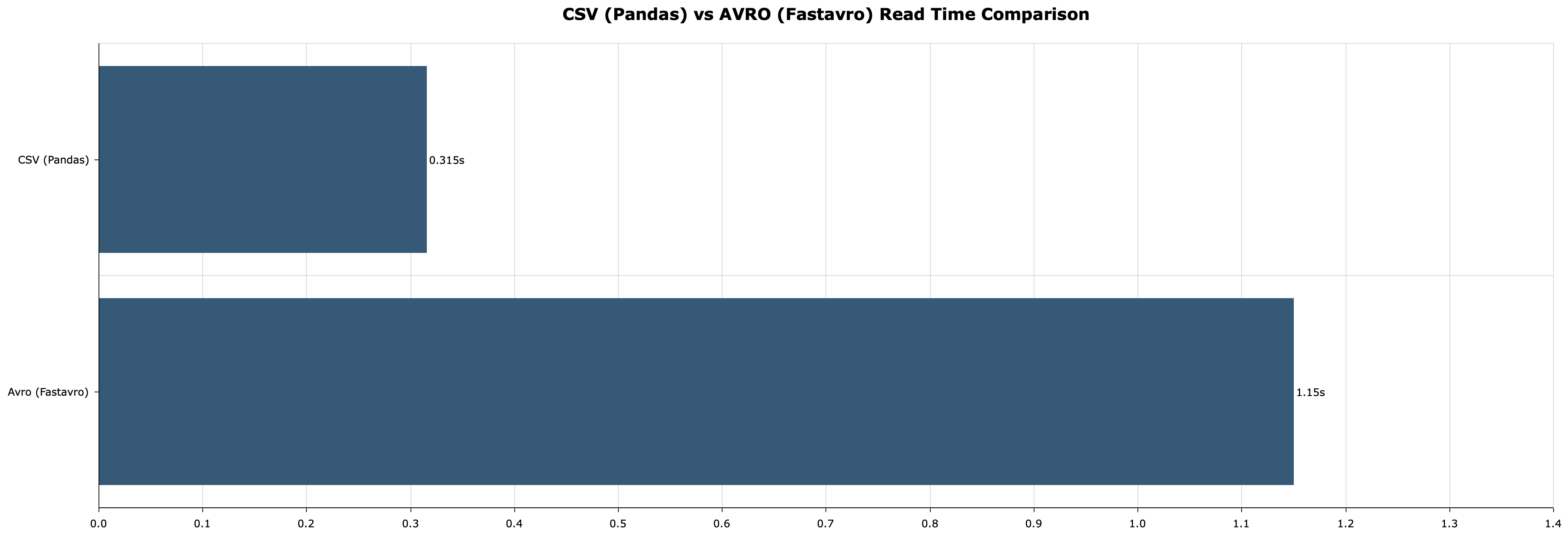
Pandas is about three times faster here, provided a 50 MB dataset.
Here’s a comparison between write times – pd.to_csv() and fastavro.writer():

The tables have turned – Pandas takes longer to save the identical dataset.
The final comparison is probably the most interesting one – file size comparison. Avro should provide a significant reduction in file size due to serialization. Here are the results:

Not quite the reduction Parquet offered, but it still isn’t too bad.
Does it matter for 50 MB datasets? Probably not, but the savings scale on larger datasets, too. That’s especially important if you’re storing data on the cloud and paying for the overall size.
That’s something to think about.
Loved the article? Become a Medium member to continue learning without limits. I’ll receive a portion of your membership fee if you use the following link, with no extra cost to you.
Read every story from Dario Radečić (and thousands of other writers on Medium)
Stay connected
- Follow me on Medium for more stories like this
- Sign up for my newsletter
- Connect on LinkedIn







