Control What You Can: Reinforcement Learning with Task Planning!
Here I talk about our NeurIPS 2019 paper, combining planning with reinforcement learning agents agraphnd intrinsic motivation.
Many control problems in the real world have some kind of hierarchical structure. When we talk about truly autonomous robots, ideally we want them to gain maximal control of their environment. We want this to happen based on little or no supervision through the reward function. Furthermore, we want the agents to make use of these inherent task hierarchies in the environment in order to make learning more sample efficient. In layman's terms, we want to leave the robot alone without any specification and let it figure out everything by itself. Most approaches deal with only one of these problems, whereby we [1] proposed a method to deal with all of them at the same time.
Before jumping into the method, we must make clear the assumptions that we made and certain terminology. For one, we assumed that the environment has task spaces that are well defined and available to us. In our case, a task space is defined as a subspace of the observation space, e.g. the coordinates of an object, although the semantics are not known to the robot. This means that the self-imposed goals correspond to reaching a goal in the task space, e.g., moving an object to a certain location.
Naturally, tasks can depend on each other, however, just learning this dependency is now enough, because we also need to know which exact goal needs to be reached in the subtasks. To give an example, consider a robot in a warehouse. There is a heavy object in the warehouse that is too heavy to lift directly, hence the robot needs to use the forklift. This scenario naturally decomposes into 3 tasks (simplified): the robot position, the forklift position, the heavy object position. We want the robot to figure out by itself that it should move to the forklift, get the forklift to the heavy object and then move the object. This involves aiming at the correct goals in each of the sub-tasks, respectively.

Keeping all of this in mind, in our proposed approach, these are the main challenges that we tried to address:
- How do we select which task to attempt before executing a rollout with the agent?
- Given that the tasks have a co-dependency between them, how do we find the correct task dependencies?
- How do we generate subgoals based on the learned task dependencies?
The Control What You Can Framework
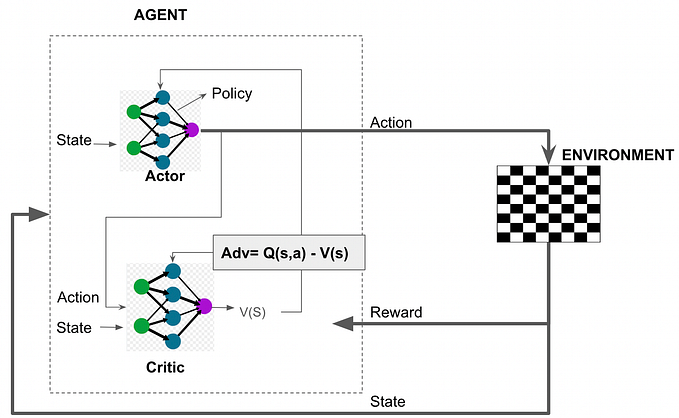
In Control What You Can (CWYC), we have multiple components that play together in order to achieve sample efficiency in learning. But before jumping into the individual components, we need a way to guide the learning in the absence of extrinsic reward. One could rely on a prediction error of forward models as a surrogate reward, but the prediction error is not enough. The reason that it is not enough is in noisy environments. If we have unpredictable factors in the environment, this yields constant prediction error. Hence we heavily rely on the measure of surprise for intrinsic motivation in all of the following components. In the absence of a success signal (which is 1 if the task was solved), the algorithm relies more heavily on surprise as a surrogate reward. We say that an event/transition is surprising if it incurs an error considerably outside a certain confidence interval, which enables us to deal with noise in the environment.
The task selector determines which task is to be attempted by the agent. The task selector is effectively a multi-armed bandit, and we need a way to fit its arm distribution. The task that should be attempted is the one that can be the most improved upon, hence we introduce improvement/learning progress (the time derivative of the success) as a means to update the distribution.
The information about the task dependencies is contained within the task planner, which is effectively a matrix encoding the task graph or contextual multi-arm bandit (where the context is the task to solve and the actions are the previous tasks). We sample the task sequence from the task planner based on the cell entries. A transition probability from task A to task B as an example is proportional to the amount of time required to solve B given solving task A and surprise seen when solving task A before task B in the goal space of B.
The subgoal generator enables us to set a goal given a task transition in the task chain. I.e., this means that given that we know we want to solve task B later, the generator outputs a goal for task A. The subgoal generator can be seen as a potential function over the goal space of a task. Again, in the absence of a success signal, this reward is dominated by the surprise.
All of the previous components are summarized in the following figure:

Experiments
We evaluated our method on two continuous control tasks, a synthetic tool-use task and a challenging robotic tool-use task against an intrinsic motivation and hierarchical RL baseline. What we have noticed is that in the absence of a well-shaped reward, the baselines fail to learn how to solve these hierarchical tasks. This is strongly connected to the fact that a really small part of the state space being relevant to solving a task. In the presence of a well-shaped reward, other methods were able to solve the tasks as well.

In the following figure are the performance plots of the tool-use task. Our method (CWYC) has consistently outperformed the baselines on tasks with a bit more complexity in the hierarchy, such as picking up a heavy object. Details can be seen in [1].


In the animation (2), we can see the training progression of the algorithm in the robotic arm task. The box is too far for the robot to reach by itself, so it needs to realize that it should go for the hook first to succeed in the task of moving the box to the goal position (red).
Additionally, we measured the “resource allocation” of the algorithm, meaning how much time does the algorithm contribute to each of the individual tasks. In the following figure, we can nicely illustrate our point. Based on our method with the use of the surprise signal and its combination with the success signal, we achieve efficient resource allocation. Tasks that cannot be solved such as moving an object appears randomly in different places quickly receive almost no attention.

Questions remain however can we alleviate our assumptions further, as in the case of the task spaces. Can we learn efficient task space partitioning for a problem that leads to efficient learning? How can we learn to sample feasible goals for the task given that we do not know which parts of the task space are reachable? This we leave for future research.
References
[1] Blaes, Sebastian et al. Control What You Can: Intrinsically Motivated Task-Planning Agent, NeurIPS 2019
[2] Images taken from Pixabay
Acknowledgment
This is work from the Autonomous Learning Group of the Max Planck Institute for Intelligent Systems.