Deep Learning
Beautifully Illustrated: NLP Models from RNN to Transformer
Explaining their complex mathematical formula with working diagrams
Published in
12 min readOct 11, 2022
Table of Contents· Recurrent Neural Networks (RNN)
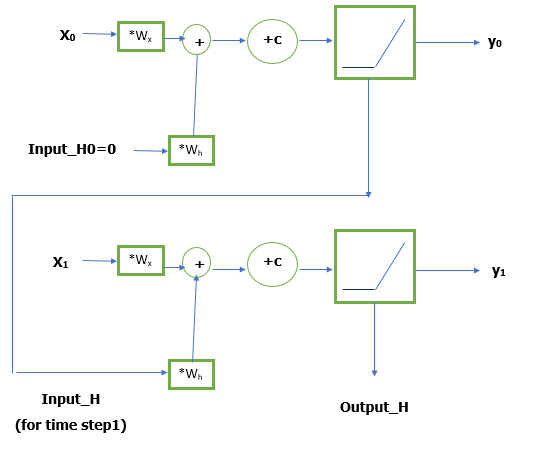
∘ Vanilla RNN
∘ Long Short-term Memory (LSTM)
∘ Gated Recurrent Unit (GRU)· RNN Architectures· Attention
∘ Seq2seq with Attention
∘ Self-attention
∘ Multi-head Attention· Transformer
∘ Step 1. Adding Positional Encoding to Word Embeddings
∘ Step 2. Encoder: Multi-head Attention and Feed Forward
∘ Step 3. Decoder: (Masked) Multi-head Attention and Feed Forward
∘ Step 4. Classifier· Wrapping Up
Natural Language Processing (NLP) is a challenging problem in deep learning since computers don’t understand what to do with raw words. To use computer power, we need to convert words to vectors before feeding them into a model. The resulting vectors are called word embeddings.
Those embeddings can be used to solve the desired task, such as sentiment classification, text generation, name entity recognition, or machine translation. They are processed in a clever way such that the performance of the model for some tasks becomes on par with that of…