A Guide to Word Embedding
What is it? How is it more useful than a Bag-of-Words model?
Reading, comprehending, communicating and ultimately producing new content is something we all do regardless of who we are in our professional lives.
When it comes to extracting useful features from a given body of text, the processes involved are fundamentally different when compared to, say a vector of continuous integers. This is because the information in a sentence or a piece of text is encoded in structured sequences, with the semantic placement of words conveying the meaning of the text.
I’m expanding with more posts on ML concepts + tutorials over at my blog!
So this dual requirement of appropriate representation of the data along with preserving the contextual meaning of the text has led me to learn about and implement 2 different NLP models to achieve the task of text classification.
Word Embeddings are dense representations of the individual words in a text, taking into account the context and other surrounding words that that individual word occurs with.
The dimensions of this real-valued vector can be chosen and the semantic relationships between words are captured more effectively than a simple Bag-of-Words Model.
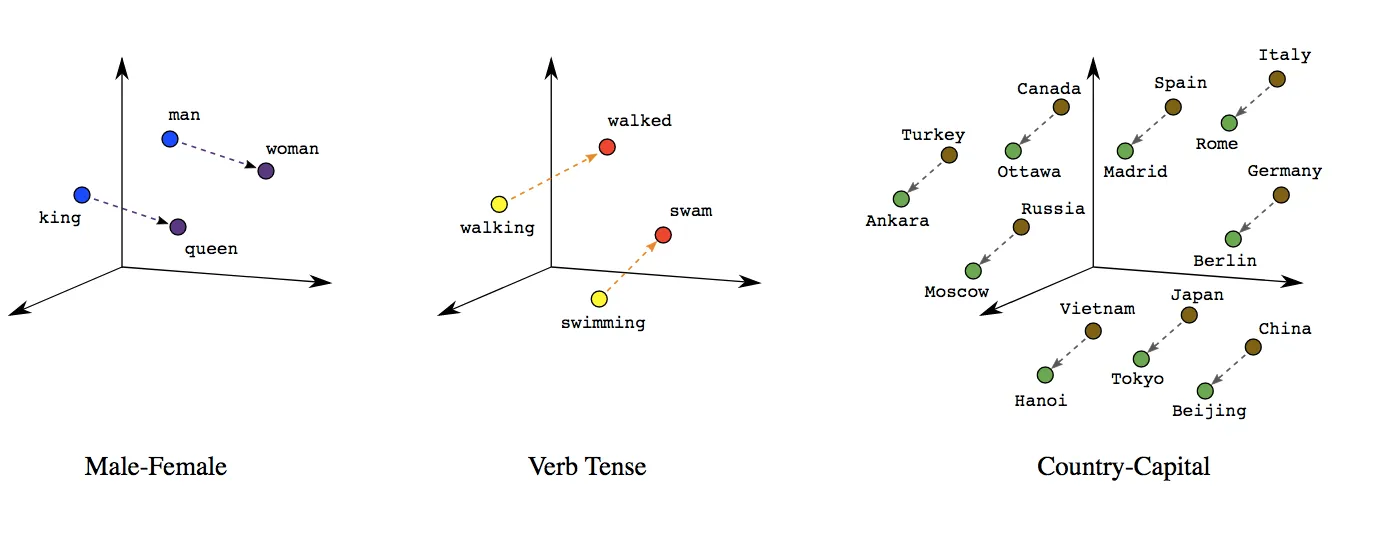
Simply put, words possessing similar meanings or often occuring together in similar contexts, will have a similar vector representation, based on how “close” or “far apart” those words are in their meanings.
In this article, I will be exploring two Word Embeddings —
1. Training our Own Embedding
2. Pre-trained GloVe Word Embedding
Dataset —
For this case study, we will be using the Stack Overflow Dataset from Kaggle. This dataset contains 60,000 questions asked by users on the website and the main task is to categorize the quality of the questions asked into 3 classes.
Let us now look at the actual models themselves for this multi-class NLP project.
Before starting, however, make sure you have installed these packages/libraries.
pip install gensim # For NLP preprocessing taskspip install keras # For the Embedding layer
1. Training the Word Embedding —
Access the entire code here for the first model, if you wish to skip the explanation.
1) Data Preprocessing —
In the first model, we will be training a neural network to learn an embedding from our corpus of text. Specifically, we will supply word tokens and their indexes to an Embedding Layer in our neural network using the Keras library.
There are some key parameters that have to be decided upon before training our network. These include the size of the vocabulary or the number of unique words in our corpus and the dimension of our embedded vectors.
There are 2 datasets provided for training and testing in the download zip. We’ll now import them and only retain the questions and the quality columns for analysis.
I’ve also changed the column names and defined a function text_clean to clean up the questions.
If you peek at the original dataset, you’ll find the questions enclosed in HTML tags like so, <p>…..question </p>. Moreover, there are also words like href, https etc., peppered throughout the entire text so I’m making sure to remove both sets of unwanted characters from the texts.
Gensim’s simple_preprocess method returns a list of tokens in lowercase with accent marks removed.
Using the apply method here will iteratively run each observation/row through the preprocessing function and return the output before moving on to the next row. Go ahead and apply the text preprocessing function to both training and testing datasets.
Since there are 3 categories in the dependent variable vector, we’ll apply one-hot encoding and initialize some parameters for later use.
2) Tokenization —
Next, we’ll be using the Keras Tokenizer class to convert our questions which are still composed of words into an array representing the words with their indices.
So we’ll first have to build an indexed vocabulary out of the words appearing in our dataset, with the fit_on_texts method.
After the vocabulary has been built, we use the text_to_sequences method to convert sentences into a list of numbers representing words.
The pad_sequences function ensures that all observations are of the same length, set to either an arbitrary number or to the length of the longest question in the dataset.
The vocab_size parameter we initialized previously is simply the size of our vocabulary of unique words (to learn and index).
3) Training the Embedding Layer —
Finally, in this part, we’ll build and train our model which consists of 2 main layers, an Embedding layer that will learn from our training documents prepared above and a Dense output layer to implement the classification task.
The embedding layer will learn the word representations, along with the neural network while training and requires a lot of text data to provide accurate predictions. In our case, the 45,000 training observations are sufficient to effectively learn the corpus and classify the quality of questions asked. As we will see from the metrics.
4) Evaluation & Metric Plots —
All that’s left is to evaluate our model’s performance and also draw plots to view how the accuracy & the loss metrics of the model change with epochs.
Our model’s performance metrics are displayed in the screenshot below.

And the code for the same is displayed below.
Here’s how the accuracy increased during training…

… and the loss decreased over 20 epochs.

2. Pre-trained GloVe Word Embeddings —
Full code here, if you just want to run the model.
Instead of training your own embedding, an alternative option is to use pre-trained word embedding like GloVe or Word2Vec. In this part, we will be using the GloVe Word Embedding trained on Wikipedia + Gigaword 5; download it from here.
i) Choose a Pre-Trained Word Embedding If —
Your dataset is composed of more “general” language and you don’t have that big of a dataset, to begin with.
Since these embeddings have been trained on a lot of words from different sources, pre-trained models might do well if your data is generalized as well.
Also, you will save on time and computing resources with pre-trained embeddings.
ii) Choose to Train Your Own Embedding If —
Your data (and project) is based on a niche industry, such as medicine, finance or any other non-generic and highly specific domains.
In such cases, a general word embedding representation might not work out for you and some words might be altogether missing from the pre-trained embeddings.
On the downside, a lot of data is needed to ensure that the word embeddings being learned do a proper job of representing the various words and the semantic relationships between them, unique to your domain.
Also, it takes a lot of computing resources to go through your corpus and build word embeddings.
Ultimately the choice between training your own embedding from the data you’ve got or using a pre-trained embedding will boil down to your unique project circumstances.
Obviously, you can still experiment with both models and choose the one offering better accuracy, but the above guide was a simplified one to aid you in making a decision.
The Process —
Most of the steps required have already been taken in the previous parts and only some adjustments are needed.
We need only build an embedding matrix of words and their vectors which will then be used to set the weights of the embedding layer.
So if you are following along with this tutorial (are you?), leave the preprocessing, tokenization and padding steps unchanged.
Once we’ve imported the original dataset and ran it through the previous text cleaning steps, we will run the below code to build the embedding matrix.
Decide how many dimensions you want your embedding to have (50, 100, 200) and include its name in the path variable below.
The code to build and train the Embedding layer and the neural network should be slightly modified to allow the embedding matrix to be used as weights in the embedding layer.
And here are the performance metrics on the test set for our pre-trained model.

Conclusion:
From the performance metrics of both models, training the embedding layer seems to be the better fit for this dataset.
Some of the reasons could be —
1) Most of the questions on Stack Overflow are related to IT & Programming, i.e, a niche domain which benefits more from a custom embedding.
2) Large Training Dataset of 45,000 samples provided a good learning scenario for our embedding layer.
Hope you found this tutorial helpful and were able to understand the concepts behind training your own word embedding.
As always any suggestions for improvement are helpful and welcome.
I’ll leave below some links for further reading as this is definitely an advanced topic and you should practice further to grasp a good understanding.
Thank you for reading and I’ll see you in my next article.
